Song Jiang
Performance and Architecture Laboratory (PAL)
Los Alamos National Laboratory, CCS Division
Los Alamos, NM 87545, USA
sjiang@lanl.gov
Feng Chen and Xiaodong Zhang
Computer Science Department
College of William and Mary
Williamsburg, VA 23187, USA
{fchen, zhang}@cs.wm.edu
Inspired by our I/O buffer cache replacement algorithm, LIRS [13], we propose an improved CLOCK replacement policy, called CLOCK-Pro. By additionally keeping track of a limited number of replaced pages, CLOCK-Pro works in a similar fashion as CLOCK with a VM-affordable cost. Furthermore, it brings all the much-needed performance advantages from LIRS into CLOCK. Measurements from an implementation of CLOCK-Pro in Linux Kernel 2.4.21 show that the execution times of some commonly used programs can be reduced by up to 47%.
We believe that there are two reasons responsible for the lack of significant improvements on VM page replacements. First, there is a very stringent cost requirement on the policy demanded by the VM management, which requires that the cost be associated with the number of page faults or a moderate constant. As we know, a page fault incurs a penalty worth of hundreds of thousands of CPU cycles. This allows a replacement policy to do its job without intrusively interfering with application executions. However, a policy with its cost proportional to the number of memory references would be prohibitively expensive, such as doing some bookkeeping on every memory access. This can cause the user program to generate a trap into the operating system on every memory instruction, and the CPU would consume much more cycles on page replacement than on user programs, even when there are no paging requests. From the cost perspective, even LRU, a well-recognized low-cost and simple replacement algorithm, is unaffordable, because it has to maintain the LRU ordering of pages for each page access. The second reason is that most proposed replacement algorithms attempting to improve LRU performance turn out to be too complicated to produce their approximations with their costs meeting the requirements of VM. This is because the weak cases for LRU mostly come from its minimal use of history access information, which motivates other researchers to take a different approach by adding more bookkeeping and access statistic analysis work to make their algorithms more intelligent in dealing with some access patterns unfriendly to LRU.
The objective of our work is to provide a VM page replacement algorithm to take the place of CLOCK, which meets both the performance demand from application users and the low overhead requirement from system designers.
Inspired by the I/O buffer cache replacement algorithm, LIRS [13], we design an improved CLOCK replacement, called CLOCK-Pro. LIRS, originally invented to serve I/O buffer cache, has a cost unacceptable to VM management, even though it holds apparent performance advantages relative to LRU. We integrate the principle of LIRS and the way in which CLOCK works into CLOCK-Pro. By proposing CLOCK-Pro, we make several contributions: (1) CLOCK-Pro works in a similar fashion as CLOCK and its cost is easily affordable in VM management. (2) CLOCK-Pro brings all the much-needed performance advantages from LIRS into CLOCK. (3) Without any pre-determined parameters, CLOCK-Pro adapts to the changing access patterns to serve a broad spectrum of workloads. (4) Through extensive simulations on real-life I/O and VM traces, we have shown the significant page fault reductions of CLOCK-Pro over CLOCK as well as other representative VM replacement algorithms. (5) Measurement results from an implementation of CLOCK-Pro in a Linux kernel show that the execution times of some commonly used programs can be reduced by up to 47%.
The LRU assumption is valid for a significant portion of workloads, and LRU works well for these workloads, which are called LRU-friendly workloads. The distance of a page in the LRU stack from the stack top to its current position is called recency, which is the number of other distinct pages accessed after the last reference to the page. Assuming an unlimitedly long LRU stack, the distance of a page in the stack away from the top when it is accessed is called its reuse distance, which is equivalent to the number of other distinct pages accessed between its last access and its current access. LRU-friendly workloads have two distinct characteristics: (1) There are much more references with small reuse distances than those with large reuse distances; (2) Most references have reuse distances smaller than the available memory size in terms of the number of pages. The locality exhibited in this type of workloads is regarded as strong, which ensures a high hit ratio and a steady increase of hit ratio with the increase of memory size.
However, there are indeed cases in which this assumption does not hold, where LRU performance could be unacceptably degraded. One example access pattern is memory scan, which consists of a sequence of one-time page accesses. These pages actually have infinitely large reuse distance and cause no hits. More seriously, in LRU, the scan could flush all the previously active pages out of memory.
As an example, in Linux the memory management for process-mapped program memory and file I/O buffer cache is unified, so the memory can be flexibly allocated between them according to their respective needs. The allocation balancing between program memory and buffer cache poses a big problem because of the unification. This problem is discussed in [22]. We know that there are a large amount of data in file systems, and the total number of accesses to the file cache could also be very large. However, the access frequency to each individual page of file data is usually low. In a burst of file accesses, most of the memory could serve as a file cache. Meanwhile, the process pages are evicted to make space for the actually infrequently accessed file pages, even though they are frequently accessed. An example scenario on this is that right after one extracts a large tarball, he/she could sense that the computer becomes slower because the previous active working set is replaced and has to be faulted in. To address this problem in a simple way, current Linux versions have to introduce some ``magic parameters'' to enforce the buffer cache allocation to be in the range of 1% to 15% of memory size by default [22]. However, this approach does not fundamentally solve the problem, because the major reason causing the allocation unbalancing between process memory and buffer cache is the ineffectiveness of the replacement policy in dealing with infrequently accessed pages in buffer caches.
Another representative access pattern defeating LRU is loop, where a set of pages are accessed cyclically. Loop and loop-like access patterns dominate the memory access behaviors of many programs, particularly in scientific computation applications. If the pages involved in a loop cannot completely fit in the memory, there are repeated page faults and no hits at all. The most cited example for the loop problem is that even if one has a memory of 100 pages to hold 101 pages of data, the hit ratio would be ZERO for a looping over this data set [9,24]!
A recent breakthrough in replacement algorithm designs, called LIRS (Low Inter-reference Recency Set) replacement [13], removes all the aforementioned LRU performance limitations while still maintaining a low cost close to LRU. It can not only fix the scan and loop problems, but also can accurately differentiate the pages based on their locality strengths quantified by reuse distance.
A key and unique approach in handling history access information in LIRS is that it uses reuse distance rather than recency in LRU for its replacement decision. In LIRS, a page with a large reuse distance will be replaced even if it has a small recency. For instance, when a one-time-used page is recently accessed in a memory scan, LIRS will replace it quickly because its reuse distance is infinite, even though its recency is very small. In contrast, LRU lacks the insights of LIRS: all accessed pages are indiscriminately cached until either of two cases happens to them: (1) they are re-accessed when they are in the stack, and (2) they are replaced at the bottom of the stack. LRU does not take account of which of the two cases has a higher probability. For infrequently accessed pages, which are highly possible to be replaced at the stack bottom without being re-accessed in the stack, holding them in memory (as well as in stack) certainly results in a waste of the memory resources. This explains the LRU misbehavior with the access patterns of weak locality.
ARC maintains two variably-sized lists holding history access information of referenced pages. Their combined size is two times of the number of pages in the memory. So ARC not only records the information of cached pages, but also keeps track of the same number of replaced pages. The first list contains pages that have been touched only once recently (cold pages) and the second list contains pages that have been touched at least twice recently (hot pages). The cache spaces allocated to the pages in these two lists are adaptively changed, depending on in which list the recent misses happen. More cache spaces will serve cold pages if there are more misses in the first list. Similarly, more cache spaces will serve hot pages if there are more misses in the second list. However, though ARC allocates memory to hot/cold pages adaptively according to the ratio of cold/hot page accesses and excludes tunable parameters, the locality of pages in the two lists, which are supposed to hold cold and hot pages respectively, can not directly and consistently be compared. So the hot pages in the second list could have a weaker locality in terms of reuse distance than the cold pages in the first list. For example, a page that is regularly accessed with a reuse distance a little bit more than the memory size can have no hits at all in ARC, while a page in the second list can stay in memory without any accesses, since it has been accepted into the list. This does not happen in LIRS, because any pages supposed to be hot or cold are placed in the same list and compared in a consistent fashion. There is one pre-determined parameter in the LIRS algorithm on the amount of memory allocation for cold pages. In CLOCK-Pro, the parameter is removed and the allocation becomes fully adaptive to the current access patterns.
Compared with the research on the general replacement algorithms targeting LRU, the work specific to the VM replacements and targeting CLOCK is much less and is inadequate. While Second Chance (SC) [28], being the simplest variant of CLOCK algorithm, utilizes only one reference bit to indicate recency, other CLOCK variants introduce a finer distinction between page access history. In a generalized CLOCK version called GCLOCK [25,17], a counter is associated with each page rather than a single bit. Its counter will be incremented if a page is hit. The cycling clock hand sweeps over the pages decrementing their counters until a page whose counter is zero is found for replacement. In Linux and FreeBSD, a similar mechanism called page aging is used. The counter is called age in Linux or act_count in FreeBSD. When scanning through memory for pages to replace, the page age is increased by a constant if its reference bit is set. Otherwise its age is decreased by a constant. One problem for this kind of design is that they cannot consistently improve LRU performance. The parameters for setting the maximum value of counters or adjusting ages are mostly empirically decided. Another problem is that they consume too many CPU cycles and adjust to changes of access patterns slowly, as evidenced in Linux kernel 2.0. Recently, an approximation version of ARC, called CAR [2], has been proposed, which has a cost close to CLOCK. Their simulation tests on the I/O traces indicate that CAR has a performance similar to ARC. The results of our experiments on I/O and VM traces show that CLOCK-Pro has a better performance than CAR.
In the design of VM replacements it is difficult to obtain much improvement in LRU due to its stringent cost constraint, yet this problem remains a demanding challenge in the OS development.
CLOCK-Pro takes the same principle as that of LIRS - it uses the reuse distance (called IRR in LIRS) rather than recency in its replacement decision. When a page is accessed, the reuse distance is the period of time in terms of the number of other distinct pages accessed since its last access. Although there is a reuse distance between any two consecutive references to a page, only the most current distance is relevant in the replacement decision. We use the reuse distance of a page at the time of its access to categorize it either as a cold page if it has a large reuse distance, or as a hot page if it has a small reuse distance. Then we mark its status as being cold or hot. We place all the accessed pages, either hot or cold, into one single list 2 in the order of their accesses 3. In the list, the pages with small recencies are at the list head, and the pages with large recencies are at the list tail.
To give the cold pages a chance to compete with the hot pages and to ensure their cold/hot statuses accurately reflect their current access behavior, we grant a cold page a test period once it is accepted into the list. Then, if it is re-accessed during its test period, the cold page turns into a hot page. If the cold page passes the test period without a re-access, it will leave the list. Note that the cold page in its test period can be replaced out of memory, however, its page metadata remains in the list for the test purpose until the end of the test period or being re-accessed. When it is necessary to generate a free space, we replace a resident cold page.
The key question here is how to set the time of the test period. When a cold page is in the list and there is still at least one hot page after it (i.e., with a larger recency), it should turn into a hot page if it is accessed, because it has a new reuse distance smaller than the hot page(s) after it. Accordingly, the hot page with the largest recency should turn into a cold page. So the test period should be set as the largest recency of the hot pages. If we make sure that the hot page with the largest recency is always at the list tail, and all the cold pages that pass this hot page terminate their test periods, then the test period of a cold page is equal to the time before it passes the tail of the list. So all the non-resident cold pages can be removed from the list right after they reach the tail of the list. In practice, we could shorten the test period and limit the number of cold pages in the test period to reduce space cost. By implementing this testing mechanism, we make sure that ``cold/hot'' are defined based on relativity and by constant comparison in one clock, not on a fixed threshold that are used to separate the pages into two lists. This makes CLOCK-Pro distinctive from prior work including 2Q and CAR, which attempt to use a constant threshold to distinguish the two types of pages, and to treat them differently in their respective lists (2Q has two queues, and CAR has two clocks), which unfortunately causes these algorithms to share some of LRU's performance weakness.
Let us first assume that the memory
allocations for the hot and cold pages, ![]() and
and ![]() , respectively, are fixed, where
, respectively, are fixed, where
![]() is the total memory size
is the total memory size ![]() (
(![]() ). The number of the hot pages is also
). The number of the hot pages is also
![]() , so all the hot pages are always cached. If a hot page is going to be replaced,
it must first change into a cold page. Apart from the hot pages, all the
other accessed pages are categorized as cold pages. Among the cold pages,
, so all the hot pages are always cached. If a hot page is going to be replaced,
it must first change into a cold page. Apart from the hot pages, all the
other accessed pages are categorized as cold pages. Among the cold pages, ![]() pages
are cached, another at most
pages
are cached, another at most ![]() non-resident cold pages only
have their history access
information cached. So totally there are at most
non-resident cold pages only
have their history access
information cached. So totally there are at most ![]() metadata entries for keeping
track of page access history in the list.
As in CLOCK, all the page entries are organized as a circular linked list, shown
in Figure 1.
For each page, there is a cold/hot status associated with it. For each cold page,
there is a flag indicating if the page is in the test period.
metadata entries for keeping
track of page access history in the list.
As in CLOCK, all the page entries are organized as a circular linked list, shown
in Figure 1.
For each page, there is a cold/hot status associated with it. For each cold page,
there is a flag indicating if the page is in the test period.
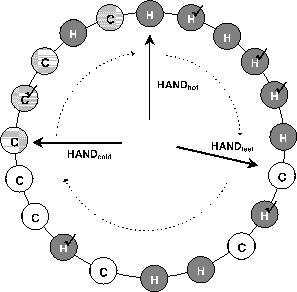 |
In CLOCK-Pro, there are three hands. The HAND![]() points to the hot
page with the largest recency. The position of this hand actually serves
as a threshold of being a hot page. Any hot pages swept by the hand turn into
cold ones.
For the convenience of the presentation,
we call the page pointed to by HAND
points to the hot
page with the largest recency. The position of this hand actually serves
as a threshold of being a hot page. Any hot pages swept by the hand turn into
cold ones.
For the convenience of the presentation,
we call the page pointed to by HAND![]() as the tail of the list, and the
page immediately after the tail page in the clockwise direction as
the head of the list.
HAND
as the tail of the list, and the
page immediately after the tail page in the clockwise direction as
the head of the list.
HAND![]() points to the last resident cold page
(i.e., the furthest one to the list head). Because we always select this cold
page for replacement, this is the position where we start to look for
a victim page, equivalent
to the hand in CLOCK.
HAND
points to the last resident cold page
(i.e., the furthest one to the list head). Because we always select this cold
page for replacement, this is the position where we start to look for
a victim page, equivalent
to the hand in CLOCK.
HAND![]() points to
the last cold page in the test period.
This hand is used to terminate the test period
of cold pages. The non-resident cold pages swept over
by this hand will leave the circular list.
All the hands move in the clockwise direction.
points to
the last cold page in the test period.
This hand is used to terminate the test period
of cold pages. The non-resident cold pages swept over
by this hand will leave the circular list.
All the hands move in the clockwise direction.
HAND![]() is used to search for a resident cold page for replacement.
If the reference bit of the cold page currently pointed to by HAND
is used to search for a resident cold page for replacement.
If the reference bit of the cold page currently pointed to by HAND![]() is unset,
we replace the cold page for a free space.
The replaced cold page will remain in the list as a non-resident cold page
until it runs out of its test period, if it is in its test period.
If not, we move it out of the clock.
However, if its bit is set and it is in
its test period, we turn
the cold page into a hot page,
and ask HAND
is unset,
we replace the cold page for a free space.
The replaced cold page will remain in the list as a non-resident cold page
until it runs out of its test period, if it is in its test period.
If not, we move it out of the clock.
However, if its bit is set and it is in
its test period, we turn
the cold page into a hot page,
and ask HAND![]() for its actions,
because an access during the test period indicates a competitively small reuse distance.
If its bit is set but it is not in its test period, there are no status change
as well as HAND
for its actions,
because an access during the test period indicates a competitively small reuse distance.
If its bit is set but it is not in its test period, there are no status change
as well as HAND![]() actions.
In both of the cases, its reference bit is reset, and we move it to the list head.
The hand will keep moving until it encounters a cold
page eligible for replacement, and
stops at the next resident cold page.
actions.
In both of the cases, its reference bit is reset, and we move it to the list head.
The hand will keep moving until it encounters a cold
page eligible for replacement, and
stops at the next resident cold page.
As mentioned above, what triggers the movement of HAND![]() is that a cold page is found to have been accessed in its test period and thus
turns into a hot page, which maybe accordingly turns the hot
page with the largest recency
into a cold page.
If the reference bit of the hot page pointed to by HAND
is that a cold page is found to have been accessed in its test period and thus
turns into a hot page, which maybe accordingly turns the hot
page with the largest recency
into a cold page.
If the reference bit of the hot page pointed to by HAND![]() is
unset, we can simply change its status
and then move the hand forward.
However, if the bit is set, which indicates the page has been re-accessed,
we spare this page, reset its reference bit and keep it as
a hot page. This is because the actual access time of
the hot page could be earlier than the cold page.
Then we move the hand forward
and do the same on the hot pages with their bits set until the hand encounters a hot page
with a reference bit of zero. Then the hot page turns into a cold page.
Note that moving HAND
is
unset, we can simply change its status
and then move the hand forward.
However, if the bit is set, which indicates the page has been re-accessed,
we spare this page, reset its reference bit and keep it as
a hot page. This is because the actual access time of
the hot page could be earlier than the cold page.
Then we move the hand forward
and do the same on the hot pages with their bits set until the hand encounters a hot page
with a reference bit of zero. Then the hot page turns into a cold page.
Note that moving HAND![]() forward is equivalent to leaving the page it moves by
at the list head.
Whenever the hand encounters a cold page, it will terminate the page's
test period. The hand will
also remove the cold page from the clock if it is non-resident (the most probable case).
It actually does the work on the cold page on behalf of hand HAND
forward is equivalent to leaving the page it moves by
at the list head.
Whenever the hand encounters a cold page, it will terminate the page's
test period. The hand will
also remove the cold page from the clock if it is non-resident (the most probable case).
It actually does the work on the cold page on behalf of hand HAND![]() .
Finally the hand stops at a hot page.
.
Finally the hand stops at a hot page.
We keep track of the number of non-resident cold pages. Once the number exceeds ![]() ,
the memory size in the number of pages, we terminate the test period of the cold
page pointed to by HAND
,
the memory size in the number of pages, we terminate the test period of the cold
page pointed to by HAND![]() . We also
remove it from the clock if it is a non-resident page.
Because the cold page has used up its test period without a re-access
and has no chance to turn into a hot page with its next access.
HAND
. We also
remove it from the clock if it is a non-resident page.
Because the cold page has used up its test period without a re-access
and has no chance to turn into a hot page with its next access.
HAND![]() then moves forward and stops at the next cold page.
then moves forward and stops at the next cold page.
Now let us summarize how these hands coordinate their operations on the clock
to resolve a page fault.
When there is a page fault, the faulted page must be a cold page.
We first run HAND![]() for a free space.
If the faulted cold page is not in the list, its reuse distance is highly likely
to be larger than the recency of hot pages 4.
So the page is still categorized as a cold page and is placed at the list head.
The page also initiates its test period. If the number of cold pages is
larger than the threshold (
for a free space.
If the faulted cold page is not in the list, its reuse distance is highly likely
to be larger than the recency of hot pages 4.
So the page is still categorized as a cold page and is placed at the list head.
The page also initiates its test period. If the number of cold pages is
larger than the threshold (![]() ),
we run HAND
),
we run HAND![]() .
If the cold page is in the list 5,
the faulted page turns into a hot page and is placed at the head of the list.
We run HAND
.
If the cold page is in the list 5,
the faulted page turns into a hot page and is placed at the head of the list.
We run HAND![]() to turn a hot page with a large recency into a cold page.
to turn a hot page with a large recency into a cold page.
Until now, we have assumed that the memory allocations for
the hot and cold pages are fixed.
In LIRS, there is a pre-determined parameter, denoted as ![]() , to
measure the percentage of memory that are used by cold pages.
As it is shown in [13],
, to
measure the percentage of memory that are used by cold pages.
As it is shown in [13], ![]() actually affects how LIRS
behaves differently from LRU. When
actually affects how LIRS
behaves differently from LRU. When ![]() approaches 100%,
LIRS's replacement behavior, as well as its hit ratios, are close
to those of LRU.
Although the evaluation of LIRS algorithm indicates that
its performance is not sensitive to
approaches 100%,
LIRS's replacement behavior, as well as its hit ratios, are close
to those of LRU.
Although the evaluation of LIRS algorithm indicates that
its performance is not sensitive to ![]() variations
within a large range between 1% and 30%, it also shows
that the hit ratios of LIRS could be moderately lower than
LRU for LRU-friendly workloads (i.e. with strong locality)
and increasing
variations
within a large range between 1% and 30%, it also shows
that the hit ratios of LIRS could be moderately lower than
LRU for LRU-friendly workloads (i.e. with strong locality)
and increasing ![]() can eliminate the performance gap.
can eliminate the performance gap.
In CLOCK-Pro, resident cold pages are actually
managed in the same way as in CLOCK.
HAND![]() behaves the same as what the clock hand in CLOCK does: sweeping
across the pages while sparing the page with a reference bit
of 1 and replacing the page with a reference bit of 0.
So increasing
behaves the same as what the clock hand in CLOCK does: sweeping
across the pages while sparing the page with a reference bit
of 1 and replacing the page with a reference bit of 0.
So increasing ![]() , the size of
the allocation for cold pages, makes CLOCK-Pro behave more like CLOCK.
, the size of
the allocation for cold pages, makes CLOCK-Pro behave more like CLOCK.
Let us see the performance implication of changing
memory allocation in CLOCK-Pro. To overcome
the CLOCK performance disadvantages with weak access patterns
such as scan and loop, a small ![]() value means a quick eviction
of cold pages just faulted in and the strong protection of hot pages
from the interference of cold pages. However, for a strong locality access stream,
almost all the accessed pages have relatively small reuse distance.
But, some of the pages have to be categorized as cold pages.
With a small
value means a quick eviction
of cold pages just faulted in and the strong protection of hot pages
from the interference of cold pages. However, for a strong locality access stream,
almost all the accessed pages have relatively small reuse distance.
But, some of the pages have to be categorized as cold pages.
With a small ![]() , a cold page would have to be
replaced out of memory soon after its being loaded in.
Due to its small reuse distance, the page is probably faulted in the
memory again soon after its eviction and treated as a hot page
because it is in its test period this time.
This actually generates unnecessary misses for the pages with
small reuse distances.
Increasing
, a cold page would have to be
replaced out of memory soon after its being loaded in.
Due to its small reuse distance, the page is probably faulted in the
memory again soon after its eviction and treated as a hot page
because it is in its test period this time.
This actually generates unnecessary misses for the pages with
small reuse distances.
Increasing ![]() would allow these
pages to be cached for a longer period of time and
make it more possible for them to be re-accessed and to turn into hot pages
without being replaced.
Thus, they can save additional page faults.
would allow these
pages to be cached for a longer period of time and
make it more possible for them to be re-accessed and to turn into hot pages
without being replaced.
Thus, they can save additional page faults.
For a given reuse distance of an accessed cold page,
![]() decides the probability of
a page being re-accessed before its being replaced from the memory.
For a cold page with its reuse distance larger than its test period, retaining
the page in memory with a large
decides the probability of
a page being re-accessed before its being replaced from the memory.
For a cold page with its reuse distance larger than its test period, retaining
the page in memory with a large ![]() is a waste of buffer spaces.
On the other hand, for a page with a small reuse distance, retaining
the page in memory for a longer period of time with a large
is a waste of buffer spaces.
On the other hand, for a page with a small reuse distance, retaining
the page in memory for a longer period of time with a large ![]() would save an
additional page fault. In the adaptive CLOCK-Pro, we allow
would save an
additional page fault. In the adaptive CLOCK-Pro, we allow ![]() to
dynamically adjust to the current reuse distance distribution.
If a cold page is accessed during its test period, we increment
to
dynamically adjust to the current reuse distance distribution.
If a cold page is accessed during its test period, we increment ![]() by 1. If a cold page passes its test period without a re-access,
we decrement
by 1. If a cold page passes its test period without a re-access,
we decrement ![]() by 1. Note the aforementioned cold pages include
resident and non-resident cold pages. Once the
by 1. Note the aforementioned cold pages include
resident and non-resident cold pages. Once the ![]() value is changed,
the clock hands of CLOCK-Pro will realize the memory allocation
by temporally adjusting the moving speeds of HAND
value is changed,
the clock hands of CLOCK-Pro will realize the memory allocation
by temporally adjusting the moving speeds of HAND![]() and HAND
and HAND![]() .
.
With this adaptation, CLOCK-Pro could take both LRU advantages with strong locality and LIRS advantages with weak locality.
We use both trace-driven simulations and prototype implementation to evaluate our CLOCK-Pro and to demonstrate its performance advantages. To allow us to extensively compare CLOCK-Pro with other algorithms aiming at improving LRU, including CLOCK, LIRS, CAR, and OPT, we built simulators running on the various types of representative workloads previously adopted for replacement algorithm studies. OPT is an optimal, but offline, unimplementable replacement algorithm [1]. We also implemented a CLOCK-Pro prototype in a Linux kernel to evaluate its performance as well as its overhead in a real system.
The file I/O traces used in this section are from [13] used for the LIRS evaluation. In their performance evaluation, the traces are categorized into four groups based on their access patterns, namely, loop, probabilistic, temporally-clustered and mixed patterns. Here we select one representative trace from each of the groups for the replacement evaluation, and briefly describe them here.
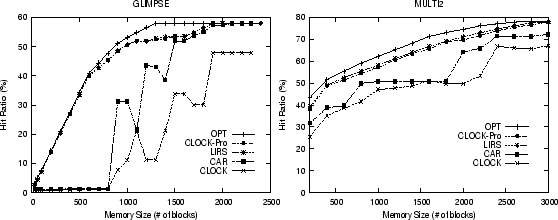 |
First, even though CLOCK-Pro
does not responsively deal with hit accesses in order to meet the cost
requirement of VM management,
the hit ratios of CLOCK-Pro and LIRS are very close, which shows that CLOCK-Pro
effectively retains the performance advantages of LIRS. For
workloads ![]() and
and ![]() , which contain many loop accesses,
LIRS with a small
, which contain many loop accesses,
LIRS with a small ![]() is most effective. The hit ratios of CLOCK-pro
are a little lower than LIRS. However, for the LRU-friendly workload,
is most effective. The hit ratios of CLOCK-pro
are a little lower than LIRS. However, for the LRU-friendly workload,
![]() , which consists of strong locality accesses, the performance of
LIRS could be lower than CLOCK (see Table 2). With its memory
allocation adaptation, CLOCK-Pro improves the LIRS performance.
, which consists of strong locality accesses, the performance of
LIRS could be lower than CLOCK (see Table 2). With its memory
allocation adaptation, CLOCK-Pro improves the LIRS performance.
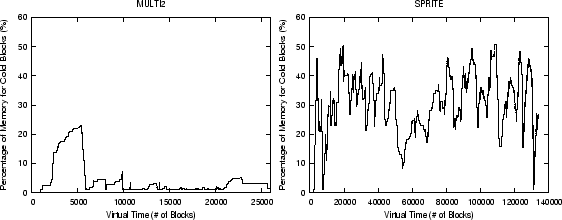
Figure 3 shows the percentage of the memory allocated to cold pages
during the execution courses of ![]() and
and ![]() for a memory size of
600 pages. We can see that for
for a memory size of
600 pages. We can see that for ![]() , the allocations
for cold pages are much larger than 1% of the memory used in LIRS, and the allocation fluctuates
over the time adaptively to the changing access patterns. It sounds paradoxical
that we need to increase the cold page allocation when there are many hot page accesses
in the strong locality workload. Actually only the real cold pages with large reuse distances
should be managed in a small cold allocation for their quick replacements. The so-called
``cold'' pages could actually be hot pages in strong locality workloads because the number of
so-called ``hot'' pages are limited by their allocation. So quickly replacing
these pseudo-cold pages should
be avoided by increasing the cold page allocation.
We can see that the cold page allocations for
, the allocations
for cold pages are much larger than 1% of the memory used in LIRS, and the allocation fluctuates
over the time adaptively to the changing access patterns. It sounds paradoxical
that we need to increase the cold page allocation when there are many hot page accesses
in the strong locality workload. Actually only the real cold pages with large reuse distances
should be managed in a small cold allocation for their quick replacements. The so-called
``cold'' pages could actually be hot pages in strong locality workloads because the number of
so-called ``hot'' pages are limited by their allocation. So quickly replacing
these pseudo-cold pages should
be avoided by increasing the cold page allocation.
We can see that the cold page allocations for ![]() are lower than
are lower than ![]() ,
which is consistent with the fact that
,
which is consistent with the fact that ![]() access patterns consist of many long loop accesses
of weak locality.
access patterns consist of many long loop accesses
of weak locality.
Second, regarding the performance difference of the algorithms, CLOCK-Pro and LIRS have much
higher hit ratios than CAR and CLOCK for ![]() and
and ![]() , and
are close to
optimal. For strong locality accesses like
, and
are close to
optimal. For strong locality accesses like ![]() , there is little
improvement
either for CLOCK-Pro or CAR. This is why CLOCK is popular,
considering its extremely
simple implementation and low cost.
, there is little
improvement
either for CLOCK-Pro or CAR. This is why CLOCK is popular,
considering its extremely
simple implementation and low cost.
Third, even with a built-in memory allocation adaption mechanism, CAR cannot provide consistent improvements over CLOCK, especially for weak locality accesses, on which a fix is most needed for CLOCK. As we have analyzed, this is because CAR, as well as ARC, lacks a consistent locality strength comparison mechanism.
In this section, we use the traces of memory accesses of program executions to evaluate the performance of the algorithms. All the traces used here are also used in [10] and many of them are also used in [9,24]. However, we do not include the performance results of SEQ and EELRU in this paper because of their generality or cost concerns for VM management. In some situations, EELRU needs to update its statistics for every single memory reference, having the same overhead problem as LRU [24]. Interested readers are referred to the respective papers for detailed performance descriptions of SEQ and EELRU. By comparing the hit ratio curves presented in those papers with the curves provided in this paper about CLOCK-Pro (these results are comparable), readers will reach the conclusion that CLOCK-Pro provides better or equally good performance compared to SEQ and EELRU. Also because of overhead concern, we do not include the LRU and LIRS performance. Actually LRU has its hit ratio curves almost the same as those of CLOCK in our experiments.
Table 3 summarizes all the program traces used in this paper.
The detailed program descriptions, space-time memory access graphs, and trace collection
methodology, are described in [10,9]. These traces cover a large range
of various access patterns. After observing their memory access graphs drawn from
the collected traces, the authors of paper [9] categorized programs ![]() ,
, ![]() ,
and
,
and ![]() as having ``no clearly visible patterns'' with all accesses temporarily
clustered together, categorized programs
as having ``no clearly visible patterns'' with all accesses temporarily
clustered together, categorized programs ![]() ,
, ![]() , and
, and ![]() as
having ``patterns at a small scale'', and categorized the rest of programs as
having ``clearly-exploitable, large-scale reference patterns''. If we examine the
program access behaviors in terms of reuse distance, the programs in
the first category are the strong locality workloads. Those in the second category
are moderate locality workloads. And the remaining
programs in the third category
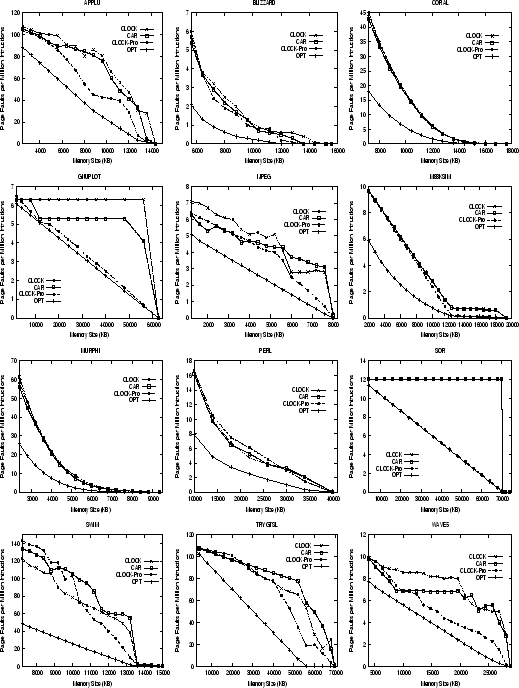
are weak locality workloads. Figure 4 shows the
number of page faults per million of instructions executed for each of the programs,
denoted as page fault ratio,
as the memory increases up to the its maximum memory demand.
We exclude cold page faults which occur on their first time accesses.
The algorithms considered here are CLOCK, CLOCK-Pro, CAR and OPT.
as
having ``patterns at a small scale'', and categorized the rest of programs as
having ``clearly-exploitable, large-scale reference patterns''. If we examine the
program access behaviors in terms of reuse distance, the programs in
the first category are the strong locality workloads. Those in the second category
are moderate locality workloads. And the remaining
programs in the third category
are weak locality workloads. Figure 4 shows the
number of page faults per million of instructions executed for each of the programs,
denoted as page fault ratio,
as the memory increases up to the its maximum memory demand.
We exclude cold page faults which occur on their first time accesses.
The algorithms considered here are CLOCK, CLOCK-Pro, CAR and OPT.
The simulation results clearly show that CLOCK-Pro significantly outperforms
CLOCK for the programs with weak locality, including programs
![]() ,
, ![]() ,
, ![]() ,
, ![]() ,
, ![]() , and
, and ![]() . For
. For ![]() and
and ![]() , which have very large loop accesses, the page fault ratios
of CLOCK-Pro
are almost equal to those of OPT. The improvements of CAR over CLOCK are
far from being consistent and significant. In many cases, it performs
worse than CLOCK. The poorest performance of CAR appears on traces
, which have very large loop accesses, the page fault ratios
of CLOCK-Pro
are almost equal to those of OPT. The improvements of CAR over CLOCK are
far from being consistent and significant. In many cases, it performs
worse than CLOCK. The poorest performance of CAR appears on traces ![]() and
and ![]() - it cannot correct the LRU problems with loop accesses and
its page fault ratios are almost as high as those of CLOCK.
- it cannot correct the LRU problems with loop accesses and
its page fault ratios are almost as high as those of CLOCK.
For programs with strong locality accesses, including ![]() ,
, ![]() and
and ![]() ,
there is little room for other replacement algorithms to do a better job than CLOCK/LRU.
Both CLOCK-Pro and ARC retain the LRU
performance advantages
for this type of programs, and CLOCK-Pro even does a little bit better than CLOCK.
,
there is little room for other replacement algorithms to do a better job than CLOCK/LRU.
Both CLOCK-Pro and ARC retain the LRU
performance advantages
for this type of programs, and CLOCK-Pro even does a little bit better than CLOCK.
For the programs with moderate locality accesses, including ![]() ,
, ![]() and
and ![]() ,
the results are mixed. Though we see the improvements of CLOCK-Pro and CAR over CLOCK in the
most cases, there does exist a case in
,
the results are mixed. Though we see the improvements of CLOCK-Pro and CAR over CLOCK in the
most cases, there does exist a case in ![]() with small memory sizes where CLOCK performs
better than CLOCK-Pro and CAR.
Though in most cases CLOCK-Pro performs better than CAR,
for
with small memory sizes where CLOCK performs
better than CLOCK-Pro and CAR.
Though in most cases CLOCK-Pro performs better than CAR,
for ![]() and
and ![]() with small memory sizes, CAR performs moderately better.
After examining the traces, we found that the CLOCK-Pro performance variations
are due to the working set shifting in the workloads. If a workload frequently
shifts its working set, CLOCK-Pro has to actively adjust the composition
of the hot page set to
reflect current access patterns. When the memory size is small,
the set of cold resident pages is
small, which causes a cold/hot status exchange to
be more possibly associated with an additional page fault.
However, the existence of locality itself confines the extent of working set changes.
Otherwise, no caching policy would fulfill its work.
So we observed moderate performance degradations for CLOCK-Pro only with small memory
sizes.
with small memory sizes, CAR performs moderately better.
After examining the traces, we found that the CLOCK-Pro performance variations
are due to the working set shifting in the workloads. If a workload frequently
shifts its working set, CLOCK-Pro has to actively adjust the composition
of the hot page set to
reflect current access patterns. When the memory size is small,
the set of cold resident pages is
small, which causes a cold/hot status exchange to
be more possibly associated with an additional page fault.
However, the existence of locality itself confines the extent of working set changes.
Otherwise, no caching policy would fulfill its work.
So we observed moderate performance degradations for CLOCK-Pro only with small memory
sizes.
To summarize, we found that CLOCK-Pro can effectively remove the performance disadvantages of CLOCK in case of weak locality accesses, and CLOCK-Pro retains its performance advantages in case of strong locality accesses. It exhibits apparently more impressive performance than CAR, which was proposed with the same objectives as CLOCK-Pro.
In an unified memory management system, file buffer cache and process memory are managed with
a common replacement policy. As we have stated in Section 2.1, memory competition
from a large number of file data accesses in a shared memory space could
interfere with program execution.
Because file data is far less frequently accessed than process
VM, a process should be more competitive in preventing its memory from being
taken away to be used as file
cache buffer. However, recency-based replacement algorithms
like CLOCK allow these file pages
to replace process memory even if they are not frequently used,
and to pollute the memory. To provide a preliminary study on the effect,
we select an I/O trace
(WebSearch1) from a popular search engine [26] and use
its first 900 second accesses
as a sample I/O accesses to co-occur with the process memory accesses
in a shared memory space.
This segment of I/O trace contains extremely weak locality - among the total 1.12 millions page
accesses, there are 1.00 million unique pages accessed.
We first scale the I/O trace onto
the execution time of a program and then aggregate the I/O trace with the program VM trace in
the order of their access times. We select a program with strong locality accesses, ![]() ,
and a program with weak locality accesses,
,
and a program with weak locality accesses, ![]() , for the study.
, for the study.
|
Tables 4 and 5 show the number of page faults per million
of instructions (only the instructions for ![]() or
or ![]() are counted) for
are counted) for
![]() and
and ![]() , respectively, with various memory sizes.
We are not interested in the performance of the I/O accesses.
There would be few page hits even for a very large dedicated memory
because there is little locality in their accesses.
, respectively, with various memory sizes.
We are not interested in the performance of the I/O accesses.
There would be few page hits even for a very large dedicated memory
because there is little locality in their accesses.
|
From the simulation results shown in the tables, we observed that:
(1) For the strong locality program, ![]() , both CLOCK-Pro and CAR can effectively protect
program execution from I/O access interference, while CLOCK is not able
to reduce its page faults with increasingly large memory sizes.
(2) For the weak locality program,
, both CLOCK-Pro and CAR can effectively protect
program execution from I/O access interference, while CLOCK is not able
to reduce its page faults with increasingly large memory sizes.
(2) For the weak locality program, ![]() , only CLOCK-Pro can protect
program execution from interference, though its page faults are
moderately increased compared with its dedicated execution on the
same size of memory. However, CAR and CLOCK cannot reduce their faults
even when the memory size exceeds the program memory demand, and the
number of faults on the dedicated executions has been zero.
, only CLOCK-Pro can protect
program execution from interference, though its page faults are
moderately increased compared with its dedicated execution on the
same size of memory. However, CAR and CLOCK cannot reduce their faults
even when the memory size exceeds the program memory demand, and the
number of faults on the dedicated executions has been zero.
We did not see a devastating influence on the program executions
with the co-existence of the intensive file data accesses.
This is because even the weak accesses of ![]() are strong enough to stave
off memory
competition from file accesses with their page re-accesses, and actually there are almost
no page reuses in the file accesses.
However, if there are quiet periods during program active executions, such as waiting for user
interactions, the program working set would be flushed by file accesses
under recency-based
replacement algorithms. Reuse distance based algorithms
such as CLOCK-Pro will not have the problem,
because file accesses have to generate small reuse distances to qualify
the file data for a long-term memory stay, and to replace the program memory.
are strong enough to stave
off memory
competition from file accesses with their page re-accesses, and actually there are almost
no page reuses in the file accesses.
However, if there are quiet periods during program active executions, such as waiting for user
interactions, the program working set would be flushed by file accesses
under recency-based
replacement algorithms. Reuse distance based algorithms
such as CLOCK-Pro will not have the problem,
because file accesses have to generate small reuse distances to qualify
the file data for a long-term memory stay, and to replace the program memory.
The ultimate goal of a replacement algorithm is to reduce application execution times in a real system. In the process of translating the merits of an algorithm design to its practical performance advantages, many system elements could affect execution times, such as disk access scheduling, the gap between CPU and disk speeds, and the overhead of paging system itself. To evaluate the performance of CLOCK-Pro in a real system, we have implemented CLOCK-Pro in Linux kernel 2.4.21, which is a well documented recent version [11,23].
We use a Gateway PC, which has its CPU of Intel P4 1.7GHz, its Western Digital WD400BB hard disk of 7200 RPM, and its memory of 256M. It is installed with RedHat 9. We are able to adjust the memory size available to the system and user programs by preventing certain portion of memory from being allocated.
In Kernel 2.4, process memory and file buffer are under an unified management. Memory pages are placed either in an active list or in an inactive list. Each page is associated with a reference bit. When a page in the inactive list is detected being referenced, the page is promoted into the active list. Periodically the pages in the active list that are not recently accessed are removed to refill the inactive list. The kernel attempts to keep the ratio of the sizes of the active list and inactive list as 2:1. Each list is organized as a separate clock, where its pages are scanned for replacement or for movement between the lists. We notice that this kernel has adopted an idea similar to the 2Q replacement [12], by separating the pages into two lists to protect hot pages from being flushed by cold pages. However, a critical question still remains unanswered: how are the hot pages correctly identified from the cold pages?
This issue has been addressed in CLOCK-Pro, where we place all the pages in one single clock list, so that we can compare their hotness in a consistent way. To facilitate an efficient clock hand movement, each group of pages (with their statuses of hot, cold, and/or on test) are linked separately according to their orders in the clock list. The ratio of cold pages and hot pages is adaptively adjusted. CLOCK-Pro needs to keep track of a certain number of pages that have already been replaced from memory. We use their positions in the respective backup files to identify those pages, and maintain a hash table to efficiently retrieve their metadata when they are faulted in.
We ran SPEC CPU2000 programs and some commonly used tools to test the performance
of CLOCK-Pro as well as the original system. We observed consistent performance
trends while running programs with weak, moderate,
or strong locality on the original and modified systems.
Here we present the representative
results for three programs, each from one of the locality groups.
Apart from ![]() , a widely used interactive plotting program with its input
data file of 16 MB, which we have used in our simulation experiments,
the other two are from SPEC CPU2000 benchmark suite [27], namely,
, a widely used interactive plotting program with its input
data file of 16 MB, which we have used in our simulation experiments,
the other two are from SPEC CPU2000 benchmark suite [27], namely, ![]() and
and ![]() .
.
![]() is a popular data compression program, showing a moderate locality.
is a popular data compression program, showing a moderate locality.
![]() is a program implementing
a language and library designed mostly for computing in groups,
showing a strong locality.
Both take the inputs from their respective training data sets.
is a program implementing
a language and library designed mostly for computing in groups,
showing a strong locality.
Both take the inputs from their respective training data sets.
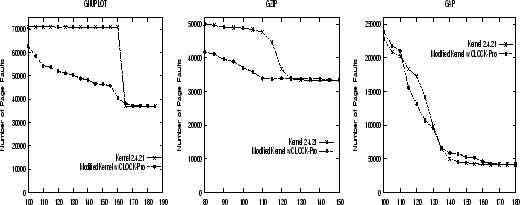 |
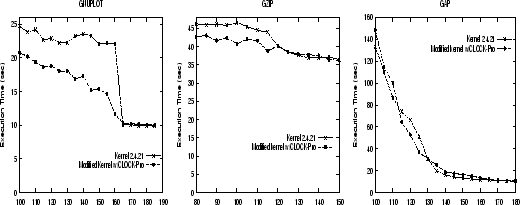 |
Figures 5 and 6 show the number of page faults
and the execution times
of programs ![]() ,
, ![]() , and
, and ![]() on the original system and the modified system adopting CLOCK-Pro.
In the simulation-based evaluation,
only page faults can be obtained. Here we also show the program
execution times, which include page fault penalties and system paging overhead.
It is noted that we include cold page faults in the statistics, because
they contribute to the execution times.
We see that the variations of the execution times
with memory size generally keep the same trends
as those of page fault numbers, which shows that
page fault is the major factor to affect system
performance.
on the original system and the modified system adopting CLOCK-Pro.
In the simulation-based evaluation,
only page faults can be obtained. Here we also show the program
execution times, which include page fault penalties and system paging overhead.
It is noted that we include cold page faults in the statistics, because
they contribute to the execution times.
We see that the variations of the execution times
with memory size generally keep the same trends
as those of page fault numbers, which shows that
page fault is the major factor to affect system
performance.
The measurements are consistent with the simulation results on the
program traces shown in Section 5.1.2. For the weak locality program ![]() ,
CLOCK-Pro significantly improves its performance by reducing both
its page fault numbers and its execution times.
The largest performance improvement comes at around 160MB, the available
memory size approaching the memory demand, where the time for CLOCK-Pro
(11.7 sec) is reduced by 47% when compared with the time for the original
system (22.1 sec).
There are some fluctuations in the
execution time curves. This is caused by the block layout on the disk.
A page faulted in from a disk position sequential to the previous access
position has a much smaller access time than that retrieved from a
random position. So the penalty varies from one page fault to another.
For programs
,
CLOCK-Pro significantly improves its performance by reducing both
its page fault numbers and its execution times.
The largest performance improvement comes at around 160MB, the available
memory size approaching the memory demand, where the time for CLOCK-Pro
(11.7 sec) is reduced by 47% when compared with the time for the original
system (22.1 sec).
There are some fluctuations in the
execution time curves. This is caused by the block layout on the disk.
A page faulted in from a disk position sequential to the previous access
position has a much smaller access time than that retrieved from a
random position. So the penalty varies from one page fault to another.
For programs ![]() and
and ![]() with a moderate or strong locality,
CLOCK-Pro provides a performance as good as the original system.
with a moderate or strong locality,
CLOCK-Pro provides a performance as good as the original system.
Currently this is only a prototype implementation of CLOCK-Pro, in which we have attempted to minimize the changes in the existing data structures and functions, and make the most of the existing infrastructure. Sometimes this means a compromise in the CLOCK-Pro performance. For example, the hardware MMU automatically sets the reference bits on the pte (Page Table Entry) entries of a process page table to indicate the references to the corresponding pages. In kernel 2.4, the paging system works on the active or inactive lists, whose entries are called page descriptors. Each descriptor is associated with one physical page and one or more (if the page is shared) pte entries in the process page tables. Each descriptor contains a reference flag, whose value is transfered from its associated pte when the corresponding process table is scanned. So there is an additional delay for the reference bits (flags) to be seen by the paging system. In kernel 2.4, there is no infrastructure supporting the retrieval of pte through the descriptor. So we have to accept this delay in the implementation. However, this tolerance is especially detrimental to CLOCK-Pro because it relies on a fine-grained access timing distinction to realize its advantages. We believe that further refinement and tuning of the implementation will exploit more performance potential of CLOCK-Pro.
Because we almost keep the paging infrastructure of the original system intact except replacing the active/inactive lists with an unified clock list and introducing a hash table, the additional overhead from CLOCK-Pro is limited to the clock list and hash table operations.
We measure the average number of entries the clock hands sweep over per page fault
on the lists for the two systems.
Table 6 shows a sample of the measurements.
The results show that
CLOCK-Pro has a number of hand movements comparable to the original
system except for large memory sizes, where the original system significantly
lowers its movement number while CLOCK-Pro does not.
In CLOCK-Pro, for every referenced
cold page seen by the moving HAND![]() , there is at least one HAND
, there is at least one HAND![]() movement to exchange the page statuses.
For a specific program with a stable locality,
there are fewer cold pages with a smaller memory,
as well as less possibility for a cold page to be re-referenced before HAND
movement to exchange the page statuses.
For a specific program with a stable locality,
there are fewer cold pages with a smaller memory,
as well as less possibility for a cold page to be re-referenced before HAND![]() moves to it. So HAND
moves to it. So HAND![]() can take a small number of movements to
reach a qualified replacement page,
and the number of additional HAND
can take a small number of movements to
reach a qualified replacement page,
and the number of additional HAND![]() movements per page fault
is also small.
When the memory size is close to the program memory demand,
the original system can take less hand movements during its search
on its inactive list, due to the increasing chance of finding an
unreferenced page.
However, HAND
movements per page fault
is also small.
When the memory size is close to the program memory demand,
the original system can take less hand movements during its search
on its inactive list, due to the increasing chance of finding an
unreferenced page.
However, HAND![]() would encounter more referenced cold pages,
which causes additional HAND
would encounter more referenced cold pages,
which causes additional HAND![]() movements.
We believe that this is not a performance concern, because
one page fault penalty is equivalent to the time of tens of thousands of hand movements.
We also measured the bucket size of the hash table, which is only 4-5 on average.
So we conclude that the additional overhead is negligible compared with the original
replacement implementation.
movements.
We believe that this is not a performance concern, because
one page fault penalty is equivalent to the time of tens of thousands of hand movements.
We also measured the bucket size of the hash table, which is only 4-5 on average.
So we conclude that the additional overhead is negligible compared with the original
replacement implementation.
https://www.storageperformance.org
This document was generated using the LaTeX2HTML translator Version 2002 (1.62)
Copyright © 1993, 1994, 1995, 1996,
Nikos Drakos,
Computer Based Learning Unit, University of Leeds.
Copyright © 1997, 1998, 1999,
Ross Moore,
Mathematics Department, Macquarie University, Sydney.
The command line arguments were:
latex2html -split 0 -show_section_numbers -local_icons html.tex
The translation was initiated by Song Jiang on 2005-02-18