
Performance Analysis
In Section 1 we identified two main reasons for data
replication on the Web: better reliability and better performance. The
reliability improvement is obvious: If a single server has a mean time
to failure MTTF1 and mean time to repair MTTR1, then a system
with n fully replicated servers has a mean time to failure given by
assuming that the server failures are statistically independent
[21]. Clearly, the mean time to failure improves with the
number of replica servers. In order to ascertain the performance gains
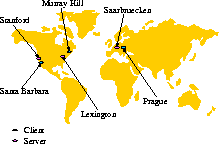
of resource replication, we conducted a live experiment with the
Web++ system.
Figure 9:
Experimental configuration.
 |