Next: Implementation
Techniques Up: Hit-Server
Implementation Previous: Hit-Server Implementation
Our current hit-server machine is an off-the-shelf PC, equipped with a 200-MHz PentiumPro uniprocessor, an Intel 440FX chipset, and 256-K of L2 cache memory. For our experiments, the hit-server was equipped with 256M of main memory. External devices are connected to the processor and the memory by a 32-bit PCI bus with a cycle time of 30 ns (33 MHz). The PCI-bus specification [17] permits burst DMA transfers with a rate of 1 word per PCI-bus cycle, corresponding to 132 MByte/s or 1056 Mbps. However, the 440FX chipset, at least in combination with the Ethernet controller chips we use, takes on average 1.5 cycles to transfer a word. So the maximum achievable transfer rate is 88 MByte/s or 704 Mbps.
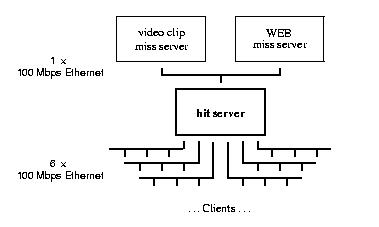
The SMC EtherPower 10/100 PCI network cards we use support 100Mbps Ethernets. They are based on the DEC 21140AE (``Tulip'') controller chip. Since the machine has only 4 PCI slots on its motherboard, we had to use an additional PCI bridge (DEC 21152) for connecting 7 Ethernet cards. In our experimental setup (Figure 2), 6 Ethernets are used as client networks, 4 of them are connected with the motherboard through the additional bridge. The seventh Ethernet connects the hit-server with the miss-servers.
Figure 2: Single-Hit-Server Architecture.
For increased numbers of miss-servers and hit-servers in a server cluster, the inter-server network hardware can be upgraded: multiple Ethernets for point-to-point connections, an ATM switch or a Myrinet. Since the inter-server network connects only 2 to perhaps 15 nodes, the related costs are economically feasible.
From the performance point of view, the most relevant operations are delivering objects to clients and receiving requests. We start with an idealistic and optimistic pre-implementation analysis of these both basic functions. The purpose of this analysis is twofold: (1) estimate an upper bound of the achievable performance; (2) identify the system's potential bottlenecks. Of course, the thus determined idealistic performance is in practice not completely achievable. Nevertheless, it gives us a reasonable order-of-magnitude goal and helps us to concentrate on the relevant optimizations in the design. Furthermore, this methodology helps us checking whether the theory, i.e., our understanding of the system, is in accordance with the reality of the system. If later performance experiments roughly corroborate with the idealistic predictions, we have a certain confidence about theory and implementation. If experiments largely diverge with our theory, we either have the wrong model or made mistakes in implementing it.
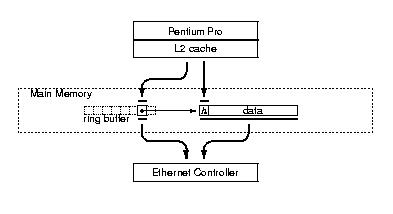
Even if an ideal implementation of the hit-server core would spend no time for bookkeeping and OS overhead, sending and receiving packets through the Ethernet controller are unavoidable. So we first analyze the optimal costs for sending a packet. Figures 3 and 4 illustrate the interaction between processor and Ethernet controller.
Figure 3: Sending an Ethernet packet.
The ring buffer holds descriptors pointing (thin arrow)
to the packets that the Ethernet controller should transmit. For
each packet, the processor first writes the descriptor and the
packet header; then the Ethernet controller reads the descriptor
and the whole packet. Memory reads and writes are denoted by
thick arrows.
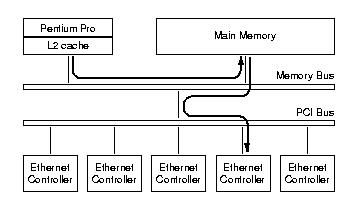
Figure 4: Accessing Main Memory.
Processor read/writes use only the memory bus while transferring
data to or from Ethernet controllers involves PCI bus and memory
bus.
Both components communicate via the main memory: the processor accesses the main memory through the memory bus and the Ethernet controller through the PCI bus and the memory bus.
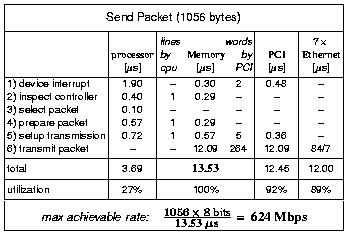
For this analysis, we assume that the packets consist of 32B header information and 1024B object data. Transmitting a packet requires the following steps:
In Table 1, the costs of these six steps are estimated and given for the critical components: processor, memory bus, PCI bus and Ethernet buses. Due to buffering and pipelining, these components can to a large degree work in parallel. However, main-memory reads through the PCI bus always require corresponding memory-bus activity.
Table 1: Pre-Implementation Micro
Analysis for a Hit-Server. Processor costs are derived from
instruction estimates (disregarding memory costs) and from micro
benchmarks of the underlying u-kernel. Memory and PCI-bus costs
are calculated from the derived number of transfers and the
average throughput costs of these transfer measured by micro
benchmarks. Ethernet costs are derived from the specified
throughput of 100 Mbps.
Next: Implementation
Techniques Up: Hit-Server
Implementation Previous: Hit-Server Implementation
Vsevolod Panteleenko
Tue Apr 28 11:56:10 EDT 1998