[top |
prev |
next]
[top |
prev |
next]
Isolation with Flexibility:
A Resource Management Framework for Central Servers
David G. Sullivan,
Margo I. Seltzer
Division of Engineering and Applied Sciences
Harvard University, Cambridge, MA 02138
{sullivan,margo}@eecs.harvard.edu
5. Experiments
We conducted a number of experiments to test the effectiveness of our
extended framework and to assess its ability to provide increased
flexibility in resource allocation while preserving secure
isolation. In the following sections, we first discuss tests of the
proportional-share mechanisms that we implemented and demonstrate that
they provide accurate proportional-share guarantees and effective
isolation. We then present experiments that test the impact of ticket
exchanges on two sets of applications.
5.1 Experimental Setup
All of these experiments were conducted using our modified kernel. We
ran it on a 200-MHz Pentium Pro processor with 128 MB of RAM and a
256-KB L2 cache. The machine had an Adaptec AHA-2940 SCSI controller
with a single 2.14-GB Conner CFP2105S hard disk.
5.2 Providing Shares of CPU Time
To test our implementation of the basic lottery-scheduling framework,
we replicated an experiment from the original lottery-scheduling paper
(Wal94, Section 5.5). We ran five concurrent
instances of a CPU-intensive program (the dhrystone benchmark [Wei84]) for 200 seconds using the CPU funding shown
in Figure 5. Principal B3 sleeps for the first half
of the test, during which time its tickets are not active.
Figure 6 shows the number of iterations accomplished
as a function of time for the jobs funded by each currency. In all
cases, the relative levels of progress of the processes match their
relative funding levels. When B3 awakes, its tickets are reactivated;
as a result, the other tasks funded by currency B receive reduced CPU
shares, while the tasks funded by currency A are unaffected because of
the isolation that currencies provide.
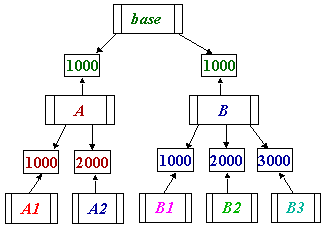
Figure 5. The CPU funding used for the experiment described
in Section 5.2. Currencies A and B receive equal
funding from the base currency, which they divide among the tasks they
fund. A2 receives twice the funding of A1, B2 receives twice the
funding of B1, and B3 has three times the funding of B1.
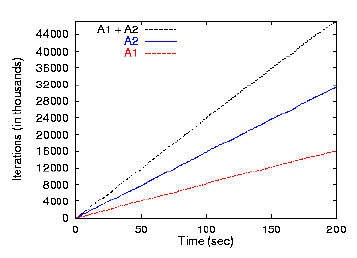
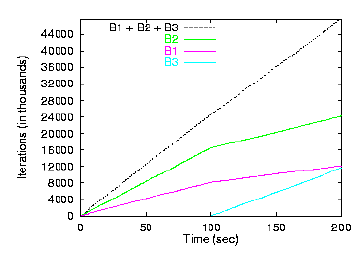
Figure 6: Hierarchical Proportional Sharing of CPU Time.
Five CPU-intensive tasks, with funding shown in Figure 5,
compete for the CPU. Shown above are the number of iterations completed by each
task as a function of time. Task B3 sleeps for the first half of the
test.
5.3 Providing Memory Shares
The next experiment tests our prototype's ability to guarantee fixed
shares of physical memory. To create enough memory pressure to force
frequent page reclamation, we limited the accessible memory to 8
MB. After subtracting out the pages wired by the kernel as well as the
desired number of free pages in the system, there were approximately
4.2 MB of memory that principals could reserve. We ran four concurrent
instances of a memory-intensive benchmark; each instance repeatedly
reads random 4-KB portions of the same 16-MB file into random
locations in a 4-MB buffer. This load keeps the pageout daemon running
more or less continuously. We gave one of the processes a 2-MB memory
guarantee (500 pages) and another a 1.4-MB guarantee (350 pages); the
other two processes ran without memory reservations.
Figure 7 shows
the actual memory shares of the tasks as a function of time. The tasks
with hard shares lose pages only when they own more than their
guaranteed shares. The tasks without memory tickets end up owning much
less memory than the ones with guaranteed shares.
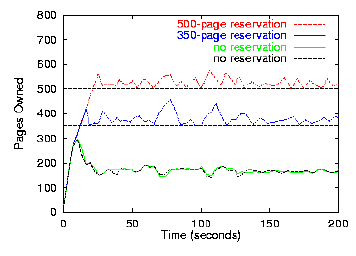
Figure 7: Providing Hard Memory Shares. Four
memory-intensive tasks run concurrently on a system with approximately
4.2 MB of available memory. Two have guaranteed memory shares; two do
not. Shown are the number of 4-KB pages owned by each process as a
function of time.
5.4 Providing Shares of Disk Bandwidth
We tested our implementation of the YFQ algorithm for
proportional-share disk scheduling by running five concurrent
instances of an I/O-intensive benchmark (iohog) that maps a 16-MB file
into its address space and touches the first byte of each page,
causing all of the pages to be brought in from disk. Each copy of the
benchmark used a different file. Throughout the test, each process
almost always has one outstanding disk request. We limited YFQ's batch
size to 2 for this and all of our tests to approximate strict
proportional sharing. We gave one process a 50% hard share of the disk
(i.e., one-half of the base currency's hard disk tickets), while the
other four tasks received the default number of disk tickets from
their user's currency.
Figure 8 shows the number of iterations that
each process accomplishes over the first 100 seconds of the
test. Because one task has reserved half of the disk, the other four
tasks divide up the remaining bandwidth and effectively get a
one-eighth share each. Thus, the process with the hard share makes
four times as much progress as the others; when it has finished
touching all 4096 of its file's pages, the other four have touched
approximately 1000 pages (a 4.1:1 ratio).
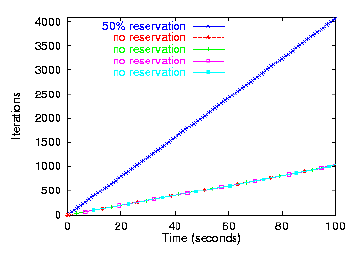
Figure 8: Providing Proportional Shares of Disk Bandwidth. Five
I/O-intensive tasks compete for the disk. One of them receives a 50%
hard share, while the others receive equal funding from their user's
currency and thus divide up the other 50% of the bandwidth. Each
iteration corresponds to paging in one 4-KB page of a memory-mapped
file.
5.5 Ticket Exchanges: CPU and Disk Tickets
To study the impact of ticket exchanges, we first conducted
experiments involving the CPU-intensive dhrystone benchmark
[Wei84] and the I/O-intensive iohog benchmark
(see Section 5.4). In the first set of runs, we gave the
benchmarks allocations of 1000 CPU and 1000 disk tickets from the base
currency. We then experimented with a series of one-for-one exchanges
in which dhrystone gives iohog n disk tickets in exchange for
n CPU tickets, where n = 100, 200, ..., 800. To create added
competition for the resources--as would typically be the case on a central
server--we ran additional tasks (one dhrystone and four iohogs) in the
background during each experiment. Each of the extra tasks received
the standard funding of 1000 CPU and 1000 disk tickets.
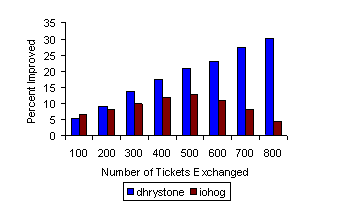
Figure 9 shows the performance improvements of the exchanging
applications under each exchange, in comparison to their performance
under the original, equal allocations. Dhrystone benefits from all of
the exchanges, and the degree of its improvement increases as it
receives additional CPU tickets. Iohog also benefits from all of the
exchanges, but the degree of its improvement decreases for exchanges
involving more than 500 tickets. While dhrystone does almost no I/O
and can thus afford to give up a large number of disk tickets, iohog
needs to be scheduled in order to make progress, and thus the benefit
of extra disk tickets is gradually offset by the loss of CPU
tickets. However, both applications can clearly benefit from this type
of exchange, which takes advantage of their differing resource
needs.
Figure 9: Performance Improvements from Ticket Exchanges. A
CPU-intensive task (dhrystone) exchanges disk tickets for some of the
CPU tickets of an I/O-intensive task (iohog). The improvements are
with respect to runs in which both tasks receive the default ticket
allocations. All results are averages of five runs.
We also examined the effect of the ticket exchanges on the
non-exchanging tasks. As discussed in
Section 3.2, the resource rights
of these tasks should be preserved, but their actual resource
shares may be affected. Such an effect is especially likely in these
experiments, because the two benchmarks rely so heavily on different
resources. For example, dhrystone uses almost no disk bandwidth. As a
result, the iohogs obtain more bandwidth than they would if the
dhrystones were competing for the disk. However, when the exchanging
iohog receives some of the exchanging dhrystone's disk tickets, it
obtains rights to a portion of this "extra" bandwidth, and
the other iohogs thus end up with smaller bandwidth shares. Exchanges
affect the CPU share of the non-exchanging dhrystone in the same
way.
However, the non-exchanging processes should still obtain at least the
resource shares that they would receive if all of the tasks were
continuously competing for both resources. To verify this, we used
getrusage (2) to determine each task's CPU and disk usage during
the first 100 seconds of each run. The results
(Fig. 10) show that the minimal resource rights of the
non-exchanging processes are preserved by all of the exchanges. The
top graph shows the CPU shares of both the exchanging and
non-exchanging dhrystones, and the bottom graph shows the
disk-bandwidth shares of the exchanging and non-exchanging iohogs.
6 Because there are seven tasks running during each
test, the non-exchanging tasks are each guaranteed a one-seventh share
(approximately 14.3%). The non-exchanging iohogs are affected less
than the non-exchanging dhrystone because each of them loses only a
portion of the bandwidth gained by the exchanging iohog. In general,
as the number of tasks competing for a resource increases, the effect
of exchanges on non-exchanging tasks should decrease.
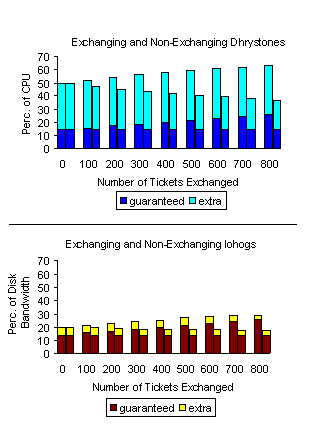
Figure 10: Resource Shares under Exchanges. Shown are the CPU
shares of the exchanging and non-exchanging dhrystones (top) and the
disk-bandwidth shares of the exchanging and non-exchanging iohogs
(bottom). The dark portion of each bar represents the share guaranteed
by the task's tickets, while the full bar indicates its actual
share. In each pair, the left bar is the exchanging copy, and the
right bar is the non-exchanging copy. All results are averages of five
runs.
5.6 Ticket Exchanges Between Database Applications: Memory and Disk Tickets
We further experimented with ticket exchanges using two simple
database applications that we developed using the Berkeley DB package
[Ols99]. Both applications emulate a
phone-number lookup server that takes a query and returns a number;
when run in automatic mode, they repeatedly generate random queries
and service them. One of the applications (small) has a 4-MB database
with 70,000 entries, while the other (big) has a much larger, 64-MB
database with 220 entries. Both applications use a memory-mapped file
as a cache.
We ran these applications concurrently for a series of 300-second
runs. We disabled the update thread for the sake of consistency,
because its periodic flushing of dirty blocks from the applications'
cache files can cause large performance variations. To emulate the
environment on a busy server, we created added memory
pressure--limiting the available memory to 16 MB--and we ran four
iohogs in the background. After subtracting out the pages wired by the
kernel and the system's free-page target, there was approximately 11.1
MB of memory that principals could reserve. When small runs alone, it
uses up to 8 MB as a result of double buffering between the
filesystem's buffer cache and its own 4-MB cache. With only 70,000
entries, it makes a large number of repeated queries, and it should
thus benefit from additional memory tickets that allow it to cache
more of its database. On the other hand, big uses a smaller, 500-KB
cache because it seldom repeats a query; it should benefit from more
disk tickets.
We started by giving the applications equal allocations: 1000 CPU
tickets, 1375 hard memory tickets 7, and 1000
disk tickets, all from the base currency. We then experimented with
exchanges in which small gives up some of its disk tickets for some of
big's memory tickets, trying all possible pairs of values from the
following set of exchange amounts: {100, 200, ..., 800}
8. The iohogs had 1000 CPU and 1000 disk tickets
each.
While the exchanges in Section 5.5 were preset, the
exchanges in these experiments were proposed and carried out
dynamically using the exch_offer() system call
(see Section 4.7). Big
proposes the exchange as soon as it starts running, but small waits
until it has made 10,000 queries (approximately one-third of the way
through the run), at which point the exchange is carried out. By
waiting, small is able to use its original disk-ticket allocation to
bring a portion of its database into memory quickly, at which point it
can afford to exchange some disk tickets for memory tickets.
Small benefits from most of the exchanges, including any in which it
obtains 400 or more memory tickets. It fails to benefit when it gains
only 100 memory tickets (not shown), or when it gives away a large
number of disk tickets for 300 or fewer memory tickets
(Fig. 11, top). Because small can only
fit about three-quarters of its database in memory with this allocation, it
cannot afford to give away a large number of disk tickets. When small
obtains 700 or 800 memory tickets, it can hold all of its database in
memory, and it thus sees performance gains of over 1000 percent
(Fig. 11, bottom). Big likewise benefits
from most of the exchanges, including any in which it obtains disk tickets
worth 600 or more.
It is interesting to note that these applications cannot simply
specify an exchange ratio, such as two disk tickets for every one
memory ticket, because what constitutes an acceptable ratio depends on
the number of tickets being exchanged. For example, small should not
accept a ratio of 2 disk for 1 memory if only 100 or 200 memory
tickets are offered, but it should accept exchanges with this ratio to
obtain 300 or more memory tickets. More generally, what constitutes an
acceptable exchange depends heavily on the environment in which the
tasks are running. For example, because tasks need to wait until a
synchronous I/O completes before enqueueing a new one, they receive at
most 50% of the bandwidth in the absence of prefetching. Therefore,
without extra tasks competing for the disk, big cannot benefit from
extra disk tickets, because it already obtains 50% of the disk by
default. Applications like big will need to use negotiators that can
assess the current system conditions before proposing an exchange.
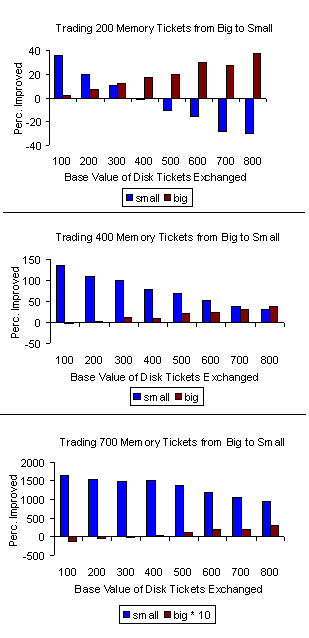
Figure 11. Results of exchanges in which an application with
a large working set (big) exchanges memory tickets for some of
the disk tickets of a similar application with a small working set
(small). The graphed changes compare the number of requests
serviced in a 100-s interval after the exchange has occurred with the
requests serviced during the same interval with no exchange. Results
are averages of at least five runs. There is a different vertical
scale for each graph, and the values for big in the third graph are
scaled by 10 to make them more visible. See related work [Sul99b] for graphs of the other exchanges.
____________________
6.
The four non-exchanging iohogs have approximately equal shares. In
each case, the graphed value is the smallest share of the four.
7.
Each hard memory ticket from the base currency represents one page of
physical memory, so 1375 tickets confer a 5.5-MB reservation.
8.
Because these exchanges were carried out by the kernel, the values
given represent the base value of the tickets exchanged, whereas the
values given in Section 5.5 are the number of
soft tickets exchanged.
[top |
prev |
next]