


Next: Defining Similarity
Up: Role Classification of Hosts
Previous: System Overview
Model
In this section, we develop a model for thinking about the grouping
problem. We define the problem in the abstract, providing a model with
several functions and parameters that can be adjusted to meet various
goals. Later in the paper, we present and evaluate instantiations of
these parameters.
- Let I be the set of hosts in an enterprise network. We will use
|I| to denote the number of hosts in I.
- Let similarity be a commutative function from pairs of hosts in
I to an integer greater than or equal to 0. Roughly speaking, if
similarity(h1, h2) is high, then we would like our grouping
algorithm to place the hosts h1 and h2 in the same
group. Defining similarity so that it is both efficient to compute
and yields a good grouping is at the heart of the problem addressed in
this paper.
- A partitioning P of I respects similarity if for all
distinct groups
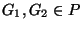 ,
,
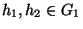 , and
, and 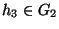 ,
,
- similarity
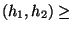 similarity(h1,h3)
similarity(h1,h3)
- similarity
similarity(h2,h3)
We extend this definition of similarity to define the average
similarity between a host h1 and a group G2,
avg_similarity(h1, G2), as the ratio of the sum of the
similarity between h1 and each 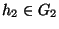 to the number of hosts
in G2:
to the number of hosts
in G2:
A partitioning P of I respects avg_similarity if
for all 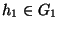 and
and 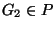 , avg_similarity
, avg_similarity
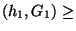 avg_similarity(h1, G2).
Respecting similarity or avg_similarity is not
sufficient to generate a useful partitioning of I. After all, a
partitioning that puts all the nodes in one group or one that puts
each node in a separate group respects similarity. We therefore
provide a parameter that can be used by network administrators to
control how aggressive the algorithm is in partitioning I into
groups.
avg_similarity(h1, G2).
Respecting similarity or avg_similarity is not
sufficient to generate a useful partitioning of I. After all, a
partitioning that puts all the nodes in one group or one that puts
each node in a separate group respects similarity. We therefore
provide a parameter that can be used by network administrators to
control how aggressive the algorithm is in partitioning I into
groups.
- Let Smin, the similarity threshold, be an
integer greater 0. A partitioning respects similarity and
Smin if it respects similarity and if, for h1 and h2 in G,
similarity
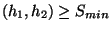 .
.
- A partitioning P of I is said to be maximal with respect
to similarity and Smin if it respects similarity and Smin and
there does not exist another partitioning of I that respects
similarity and Smin and has fewer groups. By
adjusting Smin, one gets a maximal grouping with fewer groups in
which the members of each group are more similar to each other.
Subsections
Next: Defining Similarity
Up: Role Classification of Hosts
Previous: System Overview
Godfrey Tan
2003-04-01