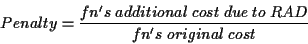To establish the baseline performance for the binary-rewriting RAD prototype, we apply it to a set of synthetic programs and measure its space and performance overhead. Table 1 shows the constant space overhead associated with binary-rewriting RAD, which excludes the per-function prologue and epilogue RAD code. Every instrumented function needs a prologue and epilogue checking code, which take 38 and 41 bytes, respectively.
Table 1:The constant space overhead of binary-rewriting RAD. The last row corresponds to the step that searches the kernel32.dll export table for the entry point of VirtualProtect().
Step
Size
Return Address Repository
16 Kbytes
Exception Handler
130 bytes
Installing Exception Handler
19 bytes
Set up RAD mine-zones
55 bytes
Search for VirtualProtect()
371 bytes
Total
16.2 - 16.6 KBytes
We then measure the performance overhead of an instrumented function due to its prologue and epilogue RAD code. Depending on whether an epilogue RAD code is triggered by a jump instruction or by a software exception handler, the measured performance overhead is different. We tested three different instrumented functions:
void fn() that does nothing and invokes prologue and epilogue RAD code through a jump instruction
void fn() that does nothing and invokes prologue RAD code through a jump and epilogue RAD code through a software exception
void fn() that does some amount of computation (incrementing a variable 25000 times), without making any other function calls
The performance penalty of the binary-rewriting RAD prototype is defined as:
and was measured using the Pentium performance counter, which has a resolution of 2 nsec.
Table 2:Per-function performance overhead due to the RAD code injected into an instrumented function. The Null function + epilog case is the same as the Null function case except its epilogue is invoked through a software interrupt. The Incrementing function case corresponds to a function that increments a variable 25000 times. All measurements are in terms of Pentium cycle counts.
Test Function
Cycle Counts - Original
Cycle Counts - RAD
Relative Penalty
Null function
292
392
34.25%
Null function + epilogue
271
641
136.53%
Incrementing function
350,425
350,722
0.085%
For the do-nothing test function case, the overhead of RAD is 34.25%, which is higher than expected, considering that both the prolog and epilogue RAD code size is just about 9 to 11 instructions, each of which is such a simple instruction as ' push reg32', ' pop reg32', ' mov reg32, mem32', ' cmp reg32, mem32', ' add mem32, imm32' ' sub reg32, imm32' etc., none of which appear to be costly. We believe this performance overhead is due to additional instruction cache misses that arise because the code region of the test function is separate from that of its prolog and epilogue RAD code. If a function's epilogue does not contain enough space to hold a jump instruction, the epilogue RAD code is implemented inside an exception handler. The additional performance overhead due to exception delivery and return, as compared to two jump instructions, is almost quadrupled, as shown in the second test function case of Table 2.When the test function is doing something more computation-intensive, as in the third test function case, the relative performance overhead of RAD immediately becomes negligible. Compared with the original RAD system [1], which works on source code only, binary-rewriting RAD performs better in all three cases, because its prolog and epilogue code is implemented in assembly and is thus more efficient. This result is somewhat surprising as the original RAD system places per-function prolog and epilogue code together with the associated function, rather than in a separate code region, and therefore does not incur additional instruction cache miss penalty.
Next:Macro-Benchmark Results Up:Experimental Results Previous:Experimental ResultsManish Prasad 2003-04-05