


Next: Related Work
Up: A Binary Rewriting Defense against Stack-based Buffer Overflow Attacks
Previous: A Binary Rewriting Defense against Stack-based Buffer Overflow Attacks
Buffer overflow attacks exploit a particular type of program weakness: lack of array/buffer bound check in the compiler or in the applications. Accordingly, the ideal solution to the buffer overflow vulnerability problem is to build a bound checking mechanism into the compiler, or to require applications to strictly follow a programming guideline that checks the bound of an array/buffer upon each access. Neither solution is considered practical at this point. A more promising approach is to transform a given application into a form that is immune from buffer overflow attack without requiring any modification to the compiler or the application itself.
Figure 1:
The typical stack layout if a function when it is called, and how some of the stack entries, including the return address could be corrupted by an unsafe copy operation..
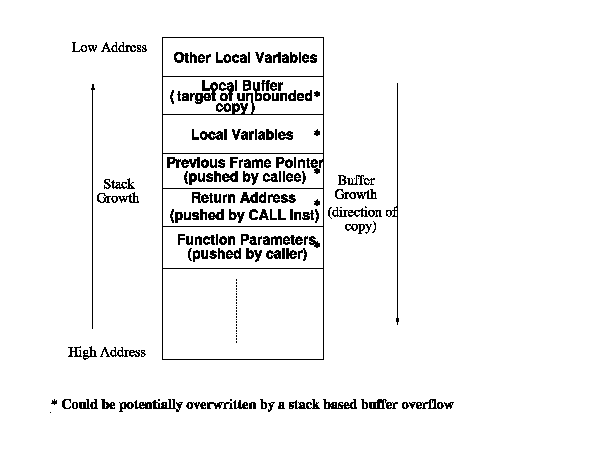 |
To understand a buffer overflow attack, consider a typical stack layout when a function is called, as shown in Figure 1. Lack of bound checking during a buffer copy operation causes areas adjacent to the buffer (as shown by * in Figure 1) to be overwritten. A generic buffer overflow attack [2] involves exploiting such an unsafe copy to overwrite the return address on the stack with the address of a piece of malicious code, which is injected by the attacker and most likely reside also on the stack; when the RET instruction (which pops the return address from the stack) in the victim function is executed, program control is transferred to the injected malicious code.
A less common form of buffer overflow attack involves corrupting memory pointer variables on the stack instead of return addresses [18]. The requirements for such an attack to occur are:
- A pointer variable p that is physically located on the stack after the buffer a[], to be overflowed,
- An overflow bug that allows overwriting this pointer p by overflowing a[] (taking user-specified data as source), usually with the address of a Global Offset Table (GOT) entry, which contains the address of a dynamic library function,
- A copy function such as str(n)cpy/memcpy which takes *p as the destination and user-specified data as the source, without p being modified between overflow and copy,
- A call to a common library function (like printf), the GOT entry of which is to be overwritten.
So leveraging the unsafe copy, the attacker overflows a[], thus overwriting p with the address of a GOT entry of a common library function, say printf(). By providing the address of the exploit code as input to the safe copy taking *p as the destination, the attacker has managed to corrupt the GOT entry of printf(). So any subsequent call to printf() would transfer control to the exploit code.
Another form of buffer overflow attack overwrites up to the old base pointer [19] on the stack with the address of malicious code, so that when the caller function returns, the control is transferred to the exploit code.
A seemingly non-stop stream of buffer overflow attacks [3, 4] has called for an effective and practical solution to protect application programs against such attacks on the Windows platform. Past approaches to protecting programs against buffer overflow vulnerabilities relied on compiler extensions, either to perform array bounds check or to prevent the return address on the stack from being overwritten. Although fairly successful in preventing most conventional buffer overflow attacks [2], these approaches require access to program source code. All known systems that take such an approach require the availability of the protected application's source code. While integrating software protection into a compiler is technically desirable, this approach exhibits several practical limitations. First, requiring access to source code makes it difficult to protect third-party legacy applications whose source code is unavailable for various reasons. Second, because modern software applications tend to be built on third-party libraries, access to the source code of these libraries again is unlikely. Finally, for those program segments that are written in assembly code directly, their high-level-language source code that is amenable to compiler analysis simply does not exist. The goal of this paper to describe our experiences and the extent of success that we have achieved in applying a combination of well known disassembly techniques to implement a binary rewriting solution that aims to provide the same level of protection as its compiler-based counterpart
There are two major technical challenges in applying binary rewriting to the buffer overflow attack problem. First, to determine where to insert protection instructions, the boundary of each function in an input program needs to be clearly identified, which in turns requires an accurate disassembler that can correctly decode each instruction in an executable binary. Unfortunately, 100% disassembly accuracy is difficult because the problem of distinguishing code from data embedded into code regions is fundamentally undecidable. Second, even if the function boundaries are successfully identified, inserting protection code into a given binary without disturbing the addresses used in its existing instructions is itself non-trivial. The main problem here is that in many cases it is possible that the binary does not have enough spare space to hold a jump instruction to the inserted protection code, let alone to hold the protection code itself.
Section 2 surveys related work in the areas of static binary translation and buffer overflow defense. Section 3 discusses the design and implementation of our disassembly engine and the binary instrumentation issues with emphasis on the approaches we employ to ensure program safety and to preserve the semantics of input programs. Section 4 details the software architecture and implementation of the binary rewriting RAD prototype. Section 5 presents experimental results on the prototype's resistance to attacks, ability to preserve the semantics of applications, space cost and performance overheads. Finally, section 6 summarizes the main results of this work and charts out directions for future research.
Next: Related Work
Up: A Binary Rewriting Defense ....
Previous: camera
Manish Prasad
2003-04-05