| ||||||||||||||||||||||||||||||||||||||||||||||||||||
|
USENIX 2003 Annual Technical Conference, General Track — Paper
[USENIX Annual Conference '03 Tech Program Index]
Application-specific Delta-encoding via Resemblance DetectionFred Douglis
Abstract:
Many objects, such as files, electronic messages, and web pages,
contain overlapping content. Numerous past research projects have
observed that one can compress one object relative to another one by
computing the differences between the two, but these
delta-encoding systems have almost invariably required
knowledge of a specific relationship between them--most commonly, two
versions using the same name at different points in time. We consider
cases in which this relationship is determined dynamically, by
efficiently determining when a sufficient resemblance exists between
two objects in a relatively large collection. We look at specific
examples of this technique, namely web pages, email, and files in a
file system, and evaluate the potential data reduction and the factors
that influence this reduction. We find that delta-encoding using this
resemblance detection technique can improve on simple compression by
up to a factor of two, depending on workload, and that a small
fraction of objects can potentially account for a large portion of
these savings.
1 IntroductionDelta-encoding is the act of compressing a data object, such as a file or web page, relative to another object [1,13]. Usually there is a temporal relationship between the two objects: the latter object exists, and when it is subsequently modified, the changes can be represented in a small fraction of the size of the entire object. There is often also a naming relationship between the objects, since a modified file can have the same name as the original copy. In these cases, identifying the base version against which to compute a delta is straightforward. Delta-encoding is particularly attractive for situations where information is being updated across a network with limited bandwidth. For example, web sites are often replicated both for higher performance and availability. The bandwidth between the replicas can be limited. Another example would be replicated mail systems. Electronic mail systems often allow clients to replicate copies of mail messages locally. Clients may be connected to the network via phone lines with limited bandwidth. For an email client connected to a mail server via a slow link, techniques which minimize bandwidth required for updates are highly desirable. However, in each of these environments, it is not always possible to identify an appropriate base version to take advantage of delta-encoding. Our work therefore addresses a domain in which there are very many objects with arbitrary overlap among different pairs of objects, and the relationships between these pairs are not known a priori. If one can identify which pairs are suitable candidates, delta-encoding can reduce the size of one relative to another, thereby reducing storage or transmission costs in exchange for computation. We consider several application domains for this technique, which we refer to as delta-encoding via resemblance detection, or DERD: web traffic, email, and files in a file system. We defer additional discussion of our research until after a more detailed discussion of delta-encoding and resemblance detection, which appears in the following subsection. After that, the next section describes the framework of our analysis in greater detail, including the metrics we consider. Section 3 presents the various datasets we used. Section 4 describes the experiments, and Section 5 provides the results of these experiments. Section 6 discusses the resource usage issues that would arise in a practical implementation of DERD. Section 7 surveys related work, and Section 8 summarizes and describes possible future work.
1.1 BackgroundIt is difficult to describe our approach without providing a general overview of both delta-encoding and resemblance detection. We cover enough of each of these areas here to set the stage for combining the two, then return to a more comprehensive comparison with related work toward the end of the paper.Deltas are useful for reducing resource requirements, and existing applications of deltas generally fall into two categories: storage and networking. For storage, when one already stores a base version of a file, subsequent versions can be represented by changes. This lowers storage demands within file systems (the Revision Control System (RCS) [25] is a longstanding example of this), backup-restore systems [1], and similar environments. Over a network, transmitting data that are already known to the recipient can be avoided. The most common approach in this case is to work from a common base version known to the sender and recipient, compute the delta, and transmit it. This technique has been applied to web traffic [16], IP-level network communication [24], and other domains. An extension to the traditional web delta-encoding approach is to select the base version by finding similar, rather than identical, URLs [7]. What if one wishes to find a similar file based on content rather than name, among a large collection of files? Manber devised a method for extracting features of files based on their contents, in order to find files with overlapping content efficiently [14]. He computed hashes of overlapping sequences of bytes (also known as ``shingles''), then looked for how many of these hashes were shared by different files. Manber indicated that clustering similar files for improved compression would be an application of this technique. Broder used a similar approach but used a deterministic sampling of the hash values to dramatically reduce the amount of data needed for each file [5,6]. With his approach, a subset of features of a file is used to represent the file, and if two files share many of those features in common, there is a high probability of significant content in common as well. A common use for this technique is to suppress near-duplicates in search engine results [6], and variations of the technique have been used in link-level duplicate suppression [24] and file systems [8,17,20]. Because the shingling technique has seen so much use in the systems community of late, we refrain from providing a detailed description of it. Briefly, it uses Rabin fingerprints [21] to compute a hash of consecutive bytes; the key properties of Rabin fingerprints are that they are efficient to compute over a sliding window, and they are uniformly distributed over all possible values. Thus, Broder's approach of selecting the N fingerprints with the smallest values effectively selects N ``random'' features in a deterministic fashion, and two documents with many features in common overall would hopefully have many of these N features in common.
1.2 GoalsAs Manber suggested, one can use the features of documents to identify when files overlap and then delta-encode pairs of overlapping files to save space or bandwidth. One goal of this work was to assess whether this technique is generally applicable, and if not, to identify some specific instances in which it is applicable. A second goal was to evaluate a number of the parameters used in this process, such as:
1.3 Summary of ResultsWe have found that the benefits of application-specific deltas vary depending on the mix of content types. For example, HTML and email messages display a great deal of redundancy across large datasets, resulting in deltas that are significantly smaller than simply compressing the data, while mail attachments are often dominated by non-textual data that do not lend themselves to the technique. A few large files can contribute much of the total savings if they are particularly amenable to delta-encoding. Application-specific techniques, such as delta-encoding an unzipped version of a zip or gzip file and then zipping the result, can significantly improve results for a particular file, but unless an entire dataset consists of such files, overall results improve by just a couple of percent. Numerous parameters can be varied in assessing the benefits of deltas in this context, and we have evaluated several. The results do not appear to be sensitive to the size of shingles or the delta-encoding algorithm, within reason. The extent of the match of the number of features is a good predictor of the delta size. Perhaps most importantly, when multiple files match the same number of features, there is minimal difference between the best delta--the smallest delta obtained across all the files--and the average delta. The latter two results suggest that while it is beneficial to determine the file(s) with the maximal number of matching features, only one delta need be computed. This is crucial because finding matching features, given a precomputed database of the features of other files and the dynamically computed feature set of the file being delta-encoded, is far more efficient than computing an actual delta.
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
As described in Section 2.2, we varied a number of parameters in the delta-encoding and resemblance detection process. Our general goals were to determine how much more data could be eliminated by using deltas rather than just compression, and how sensitive that result would be to this set of parameters. In particular, we wanted to estimate the minimal work a system might do to get a reasonable benefit (i.e., the point of diminishing returns).
In general, we fixed the parameters to a common set. We then varied each parameter to evaluate its effect. Table 3 lists these parameters, with a brief description of each one, the default value in boldface, and other tested parameters. The parameters are clustered into two sets: the first controls the pass over the data to compute the features, and the second controls the comparison of those features and computation of the deltas.
In some cases, due to space constraints, we do not present additional details about variations in parameters that did not significantly affect results; these are denoted by italic text. Additional descriptions of many of the parameters were given above in Section 2.2. Note that min_features_ratio is special, in that it is possible to compute the savings for each number of matching features and then compute a cumulative benefit for each number of matches in a later stage, as demonstrated in Section 5.1.
|
Most of the work to encode differences based on similarity is performed by a pair of Perl scripts. One of these recursively descends over a set of directories and invokes a Java program to compute the features. Each computation is a separate invocation of Java, though that could be optimized. Once a file's features have been computed, they are cached in a separate file.
The other script takes the precomputed set of filenames and features, and for each file determines which other files have the maximum number of matching features. Currently this is done by identifying which features a file has, and incrementing counters for all other files with a given feature in common, using the value of the feature as a hash key. This records the most features in common at any point, F. After all features are processed, any files that have at least one feature in common are sorted by the number of matching features. Typically, only the files that match exactly F features are considered as base versions, up to the max_comparisons parameter, but if the best matches fail to produce a small enough delta, poorer matches are considered until the maximum is reached. There are methods to optimize this comparison by precomputing the overlap of files, as well as through estimation [22], which we intend to integrate at a later date.
Delta-encoding is performed by one of a set of programs, all written in C. Once a pair of files has been so encoded, the size of the output is cached. Occasionally, the delta-encoding program might generate a delta that is larger than the compressed file, or even larger than the original file. In those cases, the minimum of the other values is used.
For a given dataset, the results are reported by listing how many files have a maximum features match for a given number of features, with statistics aggregated over those files: the original size, the size of the delta-encoded output, and the size of the output using vcdiff compression (delta-encoding against /dev/null, comparable to gzip). Table 4 is an example of this output. The rows at the top show dissimilar files, where deltas made no difference, while the rows at the bottom had the greatest similarity and the smallest deltas. The BestDelta and AvgDelta columns show that, in general, there was at most a 1% difference in size (relative to the original file) between the best of up to ten matching files and the average of all ten. This characteristic was common to all the datasets. Correspondingly, in all the figures, the curves for the savings for delta-encoding depict the average cases.
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
There are two apparent anomalies in Table 4 worth noting. First, there is a substantial jump in size at the complete 30/30 features match, despite a consistent number of files, showing a much higher average file size. This is skewed by a large number of nearly identical files, resulting from form letters attaching manuscripts for review; if each manuscript was sent to three persons and the features in the large common data were all selected by the minimization process, they all match in every feature. (This is a desirable behavior, but may not be typical of all datasets.) Second, the files with 0-2 out of 30 features matching have a dramatically worse compression ratio than the other data. We believe these are attributable to types of data that neither match other files to a great extent nor exhibit particularly good compressibility from internally repeated text strings. MIME-encoded compressed data would have this attribute, when the same compressed file does not appear in multiple messages.
To analyze the benefits of unzipping files, encoding them, and zipping the results, we take two approaches. Zip files can contain entire directory hierarchies, while gzip files compress just one file. Therefore, for zip files, we create a special ZIPDIR directory, into which the contents are unzipped before features are calculated. We assume there are no additional benefits to compression, since zip has already taken care of that. For deltas, we delta-encode each file in this directory, storing the results in a second temporary directory, and then zip the results. For gzip files, we gunzip the files, compute the features, and discard the uncompressed output. Each time we delta-encode a gzipped file, either as the reference or the version, we uncompress it on the fly (the most recent uncompressed version file is then cached and reused for each encoding). Section 5.4 discusses the added benefits of these two approaches.
In some cases, the features for all the files in a single dataset, with other run-time state, resulted in a virtual memory image that exceeded the 512 Mbytes of physical memory on the machine performing the comparisons--this is an artifact of our Perl-based prototype, and not inherent to the methodology, as evidenced by the scale of the search engines that use resemblance detection to suppress duplicates [6]. For the usr and MH datasets, we preprocessed the data to separate them into manageable subdirectories, then merged the results. This would result in files in different partitions not being compared: for example, a file in Mail/conferences would not be compared against a file in Mail/projects. In general, spatial locality would suggest that the best matches for a file in Mail/conferences would be found in Mail/conferences. (We subsequently validated this theory by rerunning the script on all MH directories at once, using a more capable machine, with no significant difference in the overall benefits.) Also, since partitions were based on subdirectories of a single root such as /usr, it also would result in some partitions having too few files to perform meaningful comparisons; we skipped any subdirectories with fewer than 100 files, resulting in a small fraction of files being omitted (listed in Table 2).
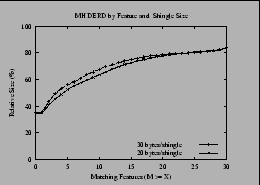
Our overall goal is to reduce file sizes and to evaluate how sensitive this reduction is to different data types, the amount of effort expended, and other considerations. Table 4 gives a sense of these results, in tabular form, for a dataset that is particularly conducive to this approach; Figure 1 shows the same data graphically. Figure 1(a) plots compressed sizes and delta-encoded sizes, as well as the original total file sizes, against the number of matching features. For each possible number of matching features from 0-30, we plot the total data of files having that number of matching features as their maximum match. As we expected, the more features match, the smaller the delta size. The cumulative effect is shown in Figure 1(b). In this graph (as well as several subsequent ones with the same label on the X-axis), a point (X,Y) shows that the total data size obtained using a particular technique such as compression or delta-encoding is Y if all files with at least X maximal matching features are encoded. For instance, the Y-value of the point on the Compressed curve with X-value 15 is the percent of the total data size obtained if all files matching at least one other file in at least 15 features are compressed. Figure 1(b) shows that the most benefit is derived from including all files, even with zero matches, although in those cases these benefits come from compression rather than deltas--recall that the size of a delta is never larger than delta-encoding it against the empty file, i.e., compressing it.
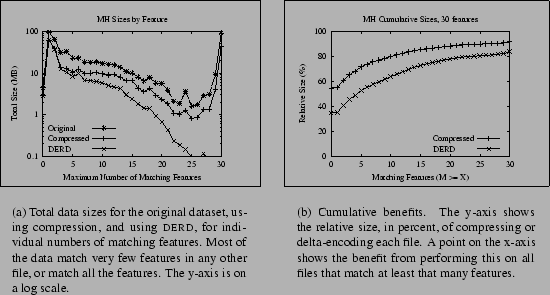 |
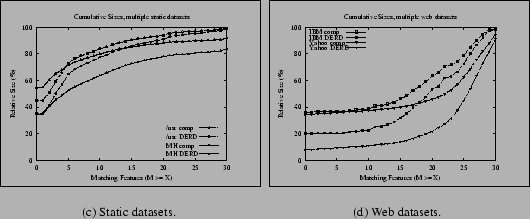
Figure 2(a) shows the cumulative benefits of deltas and compression for two of the static datasets: usr, and the MH data. Figure 2(b) does the same for two of the web datasets, IBM and Yahoo. Both graphs are limited to two datasets in order to avoid cluttering them with many overlapping lines, but the bottom-line savings for the other datasets were reported in Table 2 and Table 1, respectively. In each, the different datasets show different benefits, due to the amount of data being compared and the nature of the contents. Specifically, the graphs have very different shapes because many more files in the web datasets have high degrees of overlap.
 |
The graphs presented thus far have emphasized the effect of statistics such as the number of features that match. Another consideration is the skew in the savings: do a small number of files contribute most of the benefits of delta-encoding? In the case of the MH dataset, such a skew was suggested by the statistics in Table 4, which showed 91 of the 566 Mbytes matching in all 30 features and delta-encoding to virtually nothing.
We visualize an answer to this question by considering every file in a particular dataset, sorting by the most bytes saved for any delta obtained for it, and plotting the cumulative distribution of the savings as a function of the original files. Figure 3(a) plots the cumulative savings of the MH dataset (as a fraction of the original data) against the fraction of files used to produce those savings or the fraction of bytes in those files. In each case the savings for DERD and strict compression are shown as separate curves. Finally, points are plotted on a log-log scale to emphasize the differences at small values, and note that the Comp by byte% curve starts at just over 2% on the X-axis.
The results for this dataset clearly show significant skew. For example, for deltas, 1% of the files account for 38% of the total 65% saved; encoding 25% of the bytes will save 22% of the data. Compression also shows some skew, since some files are extremely compressible. If one compressed the best files containing 25% of the bytes, one would save 17% of the data. This degree of skew suggests that heuristics for intelligently selecting a subset of potential delta-encoded pairs, or compressed files, could be quite beneficial.
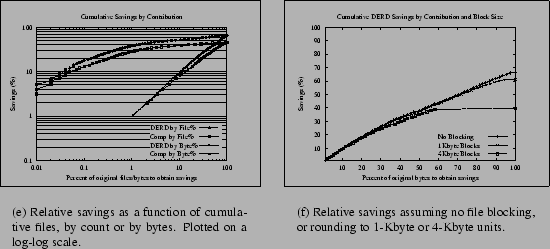 |
Section 2.2 referred to an impact on size reduction from rounding to fixed block sizes. In some workloads, such as file backups, this is a non-issue, but in others it can have a moderate impact for small blocks and a substantial impact for large ones.
Figure 3(b) shows how varying the blocksize affects overall savings for the MH dataset. Like Figure 3(a), it plots the cumulative savings sorted by contribution, but it accounts for block rounding effects. A 1-Kbyte minimum blocksize, typical for many UNIX systems with fragmented file blocks, reduces the total possible benefit of delta-encoding from around 66% (assuming no rounding) to 61%, but a 4-Kbyte blocksize brings the benefit down to 40% since so many messages are smaller than 4 Kbytes.
Section 2.2 provided a justification for comparing the uncompressed versions of zip and gzip files, as well as a hypothesis that tar files would not need special treatment. For some workloads this is irrelevant, since for example the MH repository stored all messages with full bodies, uncompressed. An attachment might contain MIME-encoded compressed files, but these would be part of the single file being examined, and one would have to be more sophisticated about extracting these attachments. In fact, there was no single workload in our study with large numbers of both zip and gzip files, and overall benefits from including this feature were only 1-2% of the original data size in any dataset. For example, the User4_Attach workload, which had the most zip files, only saved an additional 2% over the case without special handling. Even though the zip files themselves were reduced by about a third, overall storage was dominated by other file types.
We expected directly delta-encoding one tar file against a similar tar file to generate a small delta if individual files had much overlap, but this was not the case in some limited experiments. Vcdiff generated a delta about the size of the original gzipped tar file, and two other delta programs used within IBM performed similarly. We tried a sample test, using two email tar file attachments unpacked into two directories, and then using DERD to encode all files in the two directories. We selected the delta-encoded and compressed sizes of the individual files in the smaller of the tar files, and found delta-encoding saved 85% of the bytes, compared to 71% for simple compression of individual files and 79% when the entire tar file was compressed as a whole. Depending on how this extends to an entire workload, just as with zip and gzip, these savings may not justify the added effort.
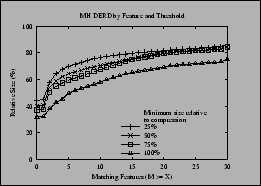
We varied the threshold for using a delta to be 25-100% of the compressed size, in increments of 25%. Figure 4 shows the result of this experiment on the MH dataset. There is a dramatic increase in the relative size of the delta-encoded data at higher numbers of matching features, because in some cases, there is no longer a usable match at a given level. The most interesting metric is the overall savings if all files are included, since that no longer suffers from this shift; the relative size increases from about 35% to about 45% as the threshold is reduced.
 |
Broder has described a way to store the features even more compactly, such as 48 bytes per file, by treating the features as aggregates of multiple features computed in the ``traditional'' method [6]. For one such meta-feature to match, all of some subset of the regular features must match exactly, suggesting a higher degree of overlap than we felt would be appropriate for DERD.
A system using our techniques to efficiently delta encode files and web documents could compute features for objects when it first becomes aware of them. The cost for determining features is not that high, and it could be amortized over time. The system could also be tuned to perform delta-encoding when space is the critical resource and to store things in a conventional manner when CPU resources are the bottleneck.
Using 30 features of 4 bytes apiece, the space overhead per file is around 120 bytes. For large files, this is insignificant. Once the features for a file have been determined, it requires O(n) operations to determine the maximum number of matching features with existing files where n is the total number of files. However, to get a reasonably good number of matching features, it is not always necessary to examine features for all of the existing files. A reasonable number of matching features can often be determined by only examining a fraction of the objects when the number of objects is large. That way, the number of comparisons needed for performing efficient delta-encoding can be bounded.
Delta-encoding itself has been made extremely efficient [1], and it should not usually be a bottleneck except in extremely high-bandwidth environments. Early work demonstrated its feasibility on wireless networks [11] and showed that processors an order of magnitude slower than current machines could support deltas over HTTP over network speeds up to about T3 speeds [16]. More recent systems like rsync [26] and LBFS [17], and the inclusion of the Ajtai delta-encoding work in a commercial backup system, also support the argument that DERD will not be limited by the delta-encoding bandwidth.
Mogul, et al., analyzed the potential benefits of compression and delta-encoding in the context of HTTP [16]. They found that delta-encoding could dramatically reduce network traffic in cases where a client and server shared a past version of a web page, termed a ``delta-eligible'' response. When a delta was available, it reduced network bandwidth requirements by about an order of magnitude. However, in the traces evaluated in that study, responses were delta-eligible only a small fraction of the time: 10% in one trace and 30% in the other, but the one with 30% excluded binary data such as images. On the other hand, most resources were compressible, and they estimated that compressing those resources dynamically would still offer significant savings in bandwidth and end-to-end transfer times--factors of 2-3 improvement in size were typical.
Later, Chan and Woo devised a method to increase the frequency of delta-eligible responses by comparing resources to other cached resources with similar URLs [7]. Their assumption was that resources ``near'' each other on a server would have pieces in common, something they then validated experimentally. They also described an algorithm for comparing a file against several other files, rather than the one-on-one comparison typically performed in this context. However, they did not explain how a server would select the particular related resources in practice, assuming that it has no specific knowledge of a client's cache. We believe there is an implicit assumption that this approach is in fact limited to ``personal proxies'' with exact knowledge of the client's cache [11,2], in which case it has limited applicability.
Ouyang, et al., similarly clustered related web pages by URL, and tried to select the best base version for a given cluster by computing deltas from a small sample [18]. While they were not focused on a caching context, and are more similar to the general applications described herein, they did not initially use the more efficient resemblance detection methods of Manber and Broder to best select the base versions. Subsequently, they applied resemblance detection techniques to scale the technique to larger collections [19]. This work, roughly concurrent with our own, is similar in its general approach. However, the largest dataset they analyzed was just over 20,000 web pages, and they did not consider other types of data such as email. Another possibly significant distinction is that they used shingle sizes of only 4 bytes, whereas we used 20-30 bytes. (We did not obtain this paper in time to repeat our analyses with such a small shingle size.)
Spring and Weatherall [24] essentially generalized Chan and Woo's work by applying it to all data sent over a specific communication channel, and using resemblance detection to detect duplicate sequences in a collection of data. This was done by computing fingerprints of shingles, selecting those with a predetermined number of zeroes in the low-order bits (deterministically selecting a fraction of features), and scanning before and after the matching shingle to find the longest duplicate data sequence. Like Chan and Woo's work, this system worked only with a close coupling between clients and servers, so both sides would know what redundant data existed in the client. In addition, the communication channel approach requires a separate cache of packets exchanged in the past, which may compete with the browser cache and other applications for resources.
In some cases, the suppression of redundancy is at a very coarse level, for instance identifying when an entire payload is identical to an earlier payload [12], or when a particular region of a file has not changed. Examples of system taking this approach include rsync [26], a popular protocol for remote file copying, and the Low-bandwidth File System (LBFS) [17]. However, there are applications for which identifying an appropriate base version is difficult and the available redundancy is ignored. For instance, LBFS exploits similarities not only between different versions of the same file but across files. To identify similar files, it hashes the contents of blocks of data, where a block boundary is (usually) defined by a subset of features--like the Spring & Wetherall approach, except that the features determine block boundaries rather than indices for the data being compared. Variable block boundaries allow a change within one block not to affect neighboring blocks. (The Venti archival system [20] and the Pastiche peer-to-peer backup system [8] are two more recent examples of the use of content-defined blocks to identify duplicate content; we use LBFS here as the ``canonical'' example of the technique.)
Similarly, it is not always possible to ensure that both sides of a network connection share a single common base version. Rsync allows the two communicating parties to ascertain dynamically which blocks of a file are already contained in a version of the file on the receiving side.
LBFS and rsync are well suited to compressing large files with long sequences of unchanged bytes, but if the granularity of change is finer than their block boundaries, they get no benefit. Most delta-encoding algorithms remove redundancy if it is large enough to amortize the overhead of the pointers and other meta-data that identify the redundancy. A resemblance detection procedure should therefore be suited to the delta-encoding algorithm, and the size and contents of the data. Our work demonstrates that fine-grained deltas work well in a variety of environments, but a head-to-head comparison with LBFS and rsync in these environments will help determine which approach is best in which context.
For web content, we have found substantial overlap among pages on a single site. This is consistent with Chan and Woo [7], Ouyang, et al. [19], and recent work on automatic detection of common fragments within pages [23]. For the five web datasets we considered, deltas reduced the total size of the dataset to 8-19% of the original data, compared to 29-36% using compression. For files and email, there was much more variability, and the overall benefits are not as dramatic, but they are significant: two of the largest datasets reduced the overall storage needs by 10-20% beyond compression. There was significant skew in at least one dataset, with a small fraction of files accounting for a large portion of the savings. Factors such as shingle size and the number of features compared do not dramatically affect these results. Given a particular number of maximal matching features, there is not a wide variation across base files in the size of the resulting deltas.
A new file will often be created by making a small number of changes to an older file; the new file may even have the same name as the old file. In these cases, the new file can often be delta-encoded from the old file with minimal overhead. For the most part, our datasets did not consider these scenarios. For situations where this type of update is prevalent, the benefits from delta-encoding are likely to be higher.
Now that we have demonstrated the potential savings of DERD, in the abstract, we would like to implement underlying systems using this technology. The smaller deltas for web data suggest that an obvious approach is to integrate DERD into a web server and/or cache, and then use a live system over time. However, supporting resemblance-based deltas in HTTP involves extra overheads and protocol support [10] that do not affect other applications such as backups. We are also interested in methods to reduce storage and network costs in email systems, and hope to implement our approach in commonly used mail platforms. As the system scales to larger datasets, we can add heuristics for more efficient resemblance detection and feature computation. We can also evaluate additional application-specific methods, such as encoding individual elements of tar files, and compare the various delta-based approaches against other systems such as LBFS and rsync in greater depth.
This document was generated using the LaTeX2HTML translator Version 2K.1beta (1.47)
Copyright © 1993, 1994, 1995, 1996,
Nikos Drakos,
Computer Based Learning Unit, University of Leeds.
Copyright © 1997, 1998, 1999,
Ross Moore,
Mathematics Department, Macquarie University, Sydney.
The command line arguments were:
latex2html -split 0 -show_section_numbers -no_navigation paper.tex
The translation was initiated by Fred Douglis on 2003-03-31
|
This paper was originally published in the
Proceedings of the
USENIX Annual Technical Conference (General Track),
June 9 – 14, 2003,
San Antonio, TX, USA
Last changed: 3 Jun 2003 aw |
|