
| ||||||||||||||||||||||||||||||||||||||||||||||||||||
|
USENIX 2002 Annual Technical Conference, Freenix Track - Paper
[USENIX 2002 Technical Program Index]
|
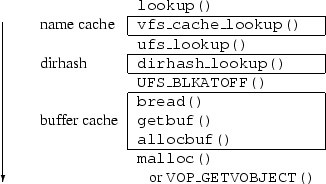 |
Like the name cache, dirhash also maintains a hash table for mapping component names to offsets within the directory. This hash table differs from the global name cache in several ways:
Due to the initial population of the dirhash table, filling the name cache with a working set of m files from a directory of size n should cost n + m rather than nm for random accesses without dirhash. If a working set of files is established in the name cache, then the dirhash hash table will no longer be accessed. The case of sequential directory access was traditionally optimised in the FFS code and would have given a cost of m. A sequential lookup optimisation is also present in dirhash; after each successful lookup, the offset of the following entry is stored. If the next lookup matches this stored value then the sequential optimisation is enabled. While the optimisation is enabled, dirhash first scans through the hash chain looking for the offset stored by the previous lookup. If the offset is found, then dirhash consults that offset before any other.
A comparison between cost per operation of the traditional linear scheme and dirhash for file creation and removal is shown in Figures 2 and 3 respectively. The costs for large directories are shown on the left and those for small directories are on the right. All these tests were performed with our benchmarking hardware described in Section 4.2. For creation with the linear scheme, we can see the cost of creations increasing as the directory size increases. For dirhash the cost remains constant at about 50us. Files were removed in sequential order, so we expect the cost to be roughly constant for both schemes. This is approximately what we see (dirhash around 35us, linear around 45us), though the results are quite noisy (perhaps due to delayed operations).
The cost of stat operations, both with and without dirhash, are shown in Figure 4 for sequentially ordered files, in Figure 5 for randomly ordered files and Figure 6 for nonexistent files. Where the name cache has a significant impact on the results, we show figures for both a purged cache and a warm cache. Sequential operation here shows a cost of about 5us if the result is in the name cache, 7us for dirhash and 9us for the linear search. For random ordering, results are similar for the name cache and dirhash. Here the linear search shows the expected linear growth rate. Both these graphs show an interesting jump at about 4000 files, which is explained below. Operating on nonexistent files incurs similar costs to operating on files in a random order. As no lookups are repeated, the name cache has no effect.
As mentioned, only directories over 2.5KB are usually indexed by dirhash. For the purposes of our tests, directories of any size were considered by dirhash, allowing us to assess this cut-off point. It seems to have been a relatively good choice, as dirhash look cheaper in all cases at 2KB and above. However, in practice, directories will be more sparsely populated than in these tests as file creation and removal will be interleaved, so 2.5KB or slightly higher seems like a reasonable cut-off point.
The elbow in Figure 2 and the jump in Figures 4 and 5 at around 4000 vnodes is caused by an interaction between the test used, the way vnodes are recycled and the name cache:
Dirhash also maintains two arrays of free-space summary information (see Figure 7 for an example). The first array, dh_blkfree, maps directory block numbers to the amount of free space in that block. As directory blocks are always 512 bytes and the length of entries is always a multiple of 4 bytes, only a single byte per block is required.
![\includegraphics[width=\textwidth / \real{2.2}]{firstfree}](img13.png)
|
The second array, dh_firstfree, maps an amount of free space to the first block with exactly that much free space, or to -1 if there is no such block. The largest legal FFS directory entry has a size of 264 bytes. This limits the useful length of the dh_firstfree array because there is never a need to locate a larger slot. Hence, the array is truncated at this size and the last element refers to a block with at least enough space to create the largest directory entry.
As entries are allocated and freed within a block, the first array can be recalculated without rescanning the whole block. The second array can then be quickly updated based on changes to the first.
Without dirhash, when a new entry is created, a full sweep of the directory ensures that the entry does not already exist. As this sweep proceeds, a search for suitable free space is performed. In order of preference, the new entry is created in:
When dirhash is used, the full sweep is no longer necessary to determine if the entry exists and the dh_firstfree array is consulted to find free space. The new entry is created in the first block listed in this array that contains enough free space.
These two policies are quite different, the former preferring to avoid compaction and the latter preferring to keep blocks as full as possible. Both aim to place new entries toward the start of the directory. This change of policy does not seem to have had any adverse effects.
Dirhash uses memory for the dirhash structure, the hash table and the free-space summary information. The dirhash structure uses 3 pointers, 9 ints, 1 doff_t and an array of 66 ints for dh_firstfree, about 320 bytes in total.
The hash table is initially sized at 150% of the maximum number of entries that the directory could contain (about 1 byte for every 2 bytes of the directory's size). The table used is actually two-level, so an additional pointer must be stored for every 256 entries in the table, or one pointer for every 2KB on the disk. The dh_blkfree array is sized at 150% of the blocks used on the disk, about 1 byte for every 340 on disk. This gives a total memory consumption of 266 bytes + 0.505dirsize on a machine with 32-bit pointers or 278 bytes + 0.507dirsize on a 64-bit platform.
The dirhash information is just a cache, so it is safe to discard it at any time and it will be rebuilt, if necessary, on the next access. In addition to being released when the directory's vnode is freed, the hash is freed in the following circumstances:
To avoid thrashing when the working set is larger than the amount of memory available to dirhash, a score system is used which achieves a hybrid of least-recently-used (LRU) and least-frequently-used (LFU). This is intended to limit the rate of hash builds when the working set is large.
The implementation of dirhash is relatively straightforward, requiring about 100 lines of header and 1000 lines of C. The actual integration of the dirhash code was unobtrusive and required only small additions to the surrounding FFS code at points where lookups occurred and where directories were modified. This means it should be easy for other systems using FFS to import and use the code.
The hash used is the FNV hash [9], which is already used within the FreeBSD kernel by the VFS cache and in the NFS code. The hash table is maintained as a two-level structure to avoid the kernel memory fragmentation that could occur if large contiguous regions were allocated. The first level is an array of pointers allocated with malloc. These point to fixed-size blocks of 256 offsets, which are currently allocated with the zone allocator.
Some of the issues that emerged since the initial integration of dirhash include:
The last three issues were uncovered during the writing of this paper (the version of dirhash used for the benchmarks predates the resolution of these issues).
On investigation, several dirhash bug reports have turned out to be faulty hardware. Since dirhash is a redundant store of information it may prove to be an unwitting detector of memory or disk corruption.
It may be possible to improve dirhash by storing hashes in the buffer cache and allowing the VM system to regulate the amount of memory which can be used. Alternatively, the slab allocator introduced for FreeBSD-5 may provide a way for dirhash to receive feedback about memory demands and adjust its usage accordingly. These options are currently under investigation.
Traditionally, directories were only considered for truncation after a create operation, because the full sweep required for creations was a convenient opportunity to determine the offset of the last useful block. Using dirhash it would be possible to truncate directories when delete operations take place, instead of waiting for the next create operation. This has not yet been implemented.
The most common directory indexing technique deployed today is probably the use of on-disk tree structures. This technique is used in XFS [16] and JFS [1] to support large directories; it is used to store all data in ReiserFS [13]. In these schemes, the index is maintained on-disk and so they avoid the cost of building the index on first access. The primary downsides to these schemes are code complexity and the need to accommodate the trees within the on-disk format.
Phillips's HTree system [11] for Ext2/3 is a variant of these schemes designed to avoid both downsides. HTree uses a fixed-depth tree and hashes keys before use to achieve a more even spread of key values.
The on-disk format remains compatible with older versions of Ext2 by hiding the tree within directory blocks that are marked as containing no entries. The disk format is constructed cleverly so that likely changes made by an old kernel will be quickly detected and consistency checking is used to catch other corruption.
Again, HTree's index is persistent, avoiding the cost of dirhash's index building. However, the placing of data within directory blocks marked as empty is something which should not be done lightly as it may reduce robustness against directory corruption and cause problems with legacy filesystem tools.
Persistent indexes have the disadvantage that once you commit to one, you cannot change its format. Dirhash does not have this restriction, which has allowed the changing of the hash function without introducing any incompatibility. HTree allows for the use of different hashes by including a version number. The kernel can fall back to a linear search if it does not support the hash version.
Another obstacle to the implementation of a tree-based indexing scheme under FFS is the issue of splitting a node of the tree while preserving consistency of the filesystem. When a node becomes too full to fit into a single block it is split across several blocks. Once these blocks are written to the disk, they must be atomically swapped with the original block. As a consequence, the original block may not be reused as one of the split blocks. This could introduce complex interactions with traditional write ordering and soft updates.
A directory hashing scheme that has been used by NetApp Filers is described by Rakitzis and Watson, [12]. Here the directory is divided into a number of fixed length chunks (2048 entries) and separate fixed-size hash tables are used for each chunk (4096 slots). Each slot is a single byte indicating which 1/256th of the chunk the entry resides in. This significantly reduces the number of comparisons needed to do a lookup.
Of the schemes considered here, this scheme is the most similar to dirhash, both in design requirements (faster lookups without changing on-disk format) and implementation (it just uses open storage hash tables to implement a complete name cache). In the scheme described by Rakitzis and Watson the use of fixed-size hash tables, which are at most 50% full, reduces the number of comparisons by a factor of 256 for large directories. This is a fixed speed-up by a factor N = 256. As pointed out by Knuth [6], one attraction of hash tables is that as the number of entries goes to infinity the search time for hash table stays bounded. This is not the case for tree based schemes. In principal dirhash is capable of these larger speed-ups, but the decision of Rakitzis and Watson to work with fixed-size hash tables avoids having to rebuild the entire hash in one operation.
We now present testimonial and benchmark results for these optimisations, demonstrating the sort of performance improvements that can be gained. We will also look at the interaction between the optimisations.
First, our testimonials: extracting the X11 distribution and maintaining a large MH mailbox. These are common real-world tasks, but since these were the sort of operations that the authors had in mind when designing dirpref and dirhash, we should expect clear benefits.
We follow with the results of some well-known benchmarks: Bonnie++ [2], an Andrew-like benchmark, NetApp's Postmark [5], and a variant of NetApp's Netnews benchmark [15]. The final benchmark is the running of a real-world workload, that of building the FreeBSD source tree.
The tar benchmark consisted of extracting the X410src-1.tgz file from the XFree [17] distribution, running find -print on the resulting directory tree and then removing the directory tree.
The folder benchmark is based on an MH inbox which has been in continuous use for the last 12 years. It involves creating 33164 files with numeric names in the order in which they were found to exist in this mailbox. Then the MH command folder -pack is run, which renames the files with names 1-33164, keeping the original numerical order. Finally the directory is removed.
Bonnie++ [2] is an extension of the Bonnie benchmark. The original Bonnie benchmark reported on file read, write and seek performance. Bonnie++ extends this by reporting on file creation, lookup and deletion. It benchmarks both sequential and random access patterns. We used version 1.01-d of Bonnie++.
The Andrew filesystem benchmark involves 5 phases: creating directories, copying a source tree into these directories, recursive stat(2) of the tree (find -exec ls -l and du -s), reading every file (using grep and wc), and finally compilation of the source tree. Unfortunately, the original Andrew benchmark is too small to give useful results on most modern systems, and so scaled up versions are often used. We used a version which operates on 100 copies of the tree. We also time the removal of the tree at the end of the run.
Postmark is a benchmark designed to simulate typical activity on a large electronic mail server. Initially a pool of text files is created, then a large number of transactions are performed and finally the remaining files are removed. A transaction can either be a file create, delete, read or append operation. The initial number of files and the number of transactions are configurable. We used version 1.13 of Postmark.
The Netnews benchmark is the simplified version of Karl Swartz's [15] benchmark used by Seltzer et al. [14]. This benchmark initially builds a tree resembling inn's [3] traditional method of article storage (tradspool). It then performs a large number of operations on this tree including linking, writing and removing files, replaying the actions of a news server.
As an example of the workload caused by software development, the FreeBSD build procedure was also used. Here, a copy of the FreeBSD source tree was checked out from a local CVS repository, it was then built using make buildworld, then the kernel source code searched with grep and finally the object tree was removed.
The tests were conducted on a modern desktop system (Pentium 4 1.6GHz processor, 256MB ram, 20GB IDE hard disk), installed with FreeBSD 4.5-PRERELEASE. The only source modification was an additional sysctl to allow the choice between the old and new dirpref code.
Each benchmark was run with all 16 combinations of soft updates on/off, vmiodir on/off, dirpref new/old and dirhash maxmem set to 2MB or 0MB (i.e., disabling dirhash). Between each run a sequence of sync and sleep commands were executed to flush any pending writes. As the directory in which the benchmarking takes place is removed between runs, no useful data could be cached.
This procedure was repeated several times and the mean and standard deviation of the results recorded. Where rates were averaged, they were converted into time-per-work before averaging and then converted back to rates. A linear model was also fitted to the data to give an indication of the interaction between optimisations.
In some cases minor modifications to the benchmarks were needed to get useful results. Bonnie++ does not usually present the result of any test taking less than a second to complete. This restriction was removed as it uses gettimeofday() whose resolution is much finer than one second. Recording the mean and standard deviation over several runs should help confirm the validity of the result.
Postmark uses time(), which has a resolution of 1 second. This proved not to be of high enough resolution in several cases. Modifications were made to the Postmark timing system to use gettimeofday() instead.
The analysis of the results was something of a challenge. For each individual test there were 4 input parameters and one output parameter, making the data 5 dimensional. The benchmarks provided 70 individual test results.
First analysis attempts used one table of results for each test. The table's rows were ranked by performance. A column was assigned to each optimisation and presence of an optimisation was indicated by a bullet in the appropriate column. An example of such a table is shown in Table 1.
To determine the most important effects, look for large vertical blocks of bullets. In our example, soft updates is the most important optimisation because it is always enabled in the top half of the table. Now, to identify secondary effects look at the top of the upper and lower halves of the table, again searching for vertical blocks of bullets. Since dirpref is at the top of both the upper and lower halves, we declare it to be the second most important factor. Repeating this process again we find vmiodir is the third most important factor. Dirhash, the remaining factor, does not seem to have an important influence in this test.
The table also shows the time as a percentage, where no optimisations is taken to be 100%. The standard deviation and the number of runs used to produce the mean result are also shown.
An attempt to analyse these results statistically was made by
fitting to the data the following linear model, containing all
possible interactions:
| t | = | Cbase + | |
| CSUdSU + CDPdDP + CVMdVM + CDHdDH + | |||
| Coefficients for pairs, triples, ... |
Table 2 shows the results of fitting such a model to using the same input data used to build Table 1. Only coefficients that have a statistical significance of more than 1/1000 are shown. The coefficients suggests a 42.71% saving for soft updates, a 14.28% saving for dirpref and a 1.91% saving for vmiodir. The presence of a positive coefficient for the combination of dirpref and soft updates means that their improvements do not add directly, but overlap by 4.57 percentage points.
If a coefficient for a combination is negative, it means that the combined optimisation is more than the sum of its parts. An example is shown in Table 3, where the benefits of dirhash are dependent on the presence of soft updates (see Section 4.4 for more details).
In some cases the results of fitting the linear model was not satisfactory as many non-zero coefficients might be produced to explain a feature more easily understood by looking at a rank table, such as the one in Table 1, for that test.
|
|
Attempts to graphically show the data were also made, but here the 5 dimensional nature of the data is a real obstacle. Displaying the transition between various combinations of optimisations was reckoned to be most promising. A decision was also made to display the data on a log scale. This would highlight effects such as those observed while removing an MH mailbox (Table 3), where soft updates reduces the time to 1.3% and then dirhash further reduces the time to 0.3%, which is a relative improvement of around 70%.
Figure 8 again shows the results of the build phase of the Buildworld benchmark, this time using a graphical representation where optimisations are sorted left to right by size of effect. The left-most triangle represents the benefit of enabling soft updates. The next column (two triangles) represents the effects of dirpref, starting with soft updates on and off. The third column (four triangles) represents vmiodir and the right-most triangles represent dirhash. Most of these triangles point up, representing improvements, but some point down, representing detrimental effects.
These graphs make it relatively easy to identify important effects and relative effects as optimisations combine. They have two minor weaknesses however. First, not all transitions are shown in these graphs. Second, the variance of results is not shown.
In an effort to produce a representation that shows both of these factors, a graph of nodes was drawn, representing the various combinations of optimisations. An edge was drawn from one node to another to represent the enabling of individual optimisations. The x coordinate of the nodes indicates the number of enabled optimisations and the y coordinate the performance. The height of nodes shows the variance of the measurement.
Figure 9 shows the graph corresponding to the build phase of the Buildworld benchmark. There are many rising edges marked with soft updates and dirpref, indicating that these are significant optimisations. Although these graphs contain all the relevant information, they are often cluttered, making them hard to read.
![\includegraphics[width=\textwidth / \real{1.13}]{greediest}](img25.png)
|
Figure 10 presents a summary of the benchmark results (the Bonnie++ file I/O and CPU results have been omitted for reasons of space). Studying the results indicates that soft updates is the most significant factor in almost all the benchmarks. The only exceptions to this are benchmarks that do not involve writing.
Of the tests significantly affected by soft updates, most saw the elapsed time reduced by a factor of more than 2 with soft updates alone. Even benchmarks where the metadata changes are small (such as Bonnie++'s sequential data output tests) saw small improvements of around 1%.
Some of the read-only tests were slightly adversely affected by soft updates (Andrew's grep 0.7%, Andrew's stat 2.4%). This is most likely attributable to delayed writes from other phases of the tests. In a real-world read-only situation this should not be a problem, as there will be no writes to interact with reading.
As expected, dirpref shows up as an important factor in benchmarks involving directory traversal: Andrew, Buildworld, Netnews and X11 Archive. For the majority of these tests dirpref improves times by 10%-20%. Of all the individual tests within these benchmarks, the only one that is not noticeably affected is the compile time in the Andrew benchmark.
Though it involves no directory traversal, the performance of Postmark with 10,000 files does seem to be very weakly dependent on dirpref. The most likely explanation for this is that the directory used by Postmark resides in a different cylinder group when dirpref is used and the existing state of the cylinder group has some small effect.
The impact of vmiodir was much harder to spot. On both the Andrew compile phase, and the build and remove phases of Buildworld, there was an improvement of around 2%. This is worthy of note as buildworld was used as a benchmark when vmiodir was assessed.
Vmiodir and dirpref have an interesting interaction on the grep and remove phases of the Andrew benchmark. Both produced similar-sized effects and the effects show significant overlap. This must correspond to vmiodir and dirpref optimising the same caching issue associated with these tasks.
As expected, dirhash shows its effect in the benchmarks involving large directories. On the Folder benchmark, dirhash takes soft updates's already impressive figures (×29, ×13 and ×77 for create, pack and remove respectively) and improves them even further (×12, ×38 and ×3 respectively). However, without soft updates, dirhash's improvements are often lost in the noise. This may be because dirhash saves CPU time and writes may be overlapped with the use of the CPU when soft updates is not present.
There are improvements too for Bonnie++'s large directory tests showing increased rates and decreased %CPU usage. The improvements for randomly creating/reading/deleting files and sequentially creating/deleting files are quite clear. Only Bonnie++'s sequential file reads on a large directory failed to show clear improvements.
Some improvements were also visible in Postmark. The improvements were more pronounced with 20,000 files than with 10,000. When combined with soft updates, overall gains were about 1%-2%. Dirhash presumably would show larger benefits for larger file sets.
We have described soft updates, dirpref, vmiodir and dirhash and studied their effect on a variety of benchmarks. The micro-benchmarks focusing on individual tasks were often improved by two orders of magnitude using combinations of these optimisations.
The Postmark, Netnews and Buildworld benchmarks are most representative of real-world workloads. Although they do not show the sort of outlandish improvements seen in the earlier micro-benchmarks, they still show large improvements over unoptimised FFS.
Many of these optimisations trade memory for speed. It would be interesting to study how reducing the memory available to the system changes its performance.
We also studied dirhash's design and implementation in detail. Given the constraint of not changing the on-disk filesystem format, dirhash seems to provide constant-time directory operations in exchange for a relatively small amount of memory. Whereas dirhash might not be the ideal directory indexing system, it does offer a way out for those working with large directories on FFS.
The complete set of scripts, code, tables and graphs are available at https://www.cnri.dit.ie/~dwmalone/ffsopt.
The authors would like to thank: Robert Watson for his comments and advice; Chris Demetriou and Erez Zadok for providing us with last-minute shepherding; Cathal Walsh for advice on linear models. Some of the work in this paper was developed or tested at the School of Mathematics, Trinity College Dublin where both authors are members of the system administration team.
|
This paper was originally published in the Proceedings of the FREENIX Track: 2002 USENIX Annual Technical Conference, June 10-15, 2002, Monterey Conference Center, Monterey, California, USA.
Last changed: 16 May 2002 ml |
|

![\includegraphics[width=\textwidth / \real{2.2}]{create}](img2.png)
![\includegraphics[width=\textwidth / \real{2.2}]{create_small}](img3.png)
![\includegraphics[width=\textwidth / \real{2.2}]{remove}](img4.png)
![\includegraphics[width=\textwidth / \real{2.2}]{remove_small}](img5.png)
![\includegraphics[width=\textwidth / \real{2.2}]{sequential}](img6.png)
![\includegraphics[width=\textwidth / \real{2.2}]{sequential_small}](img7.png)
![\includegraphics[width=\textwidth / \real{2.2}]{random}](img8.png)
![\includegraphics[width=\textwidth / \real{2.2}]{random_small}](img9.png)
![\includegraphics[width=\textwidth / \real{2.2}]{nonexistent}](img10.png)
![\includegraphics[width=\textwidth / \real{2.2}]{nonexistent_small}](img11.png)
![\includegraphics[width=\textwidth / \real{3.2},height=\textwidth / \real{2.5}]{buildworldfsopt}](img23.png)
![\includegraphics[width=\textwidth / \real{2.1}]{buildworldlattice}](img24.png)