| ||||||||||||||||||||||||||||||||||||||||||||||||||||
|
USENIX 2001 Paper
[USENIX '01 Tech Program Index]
Payload Caching: High-Speed Data Forwarding for Network Intermediaries
Ken Yocum and Jeff Chase
| ||||||||||||||||||||||||||||||||||||||||||||
| Payload Cache Operations (exported to network driver) | |
| pc_receive_bind(physaddr) | Invalidate old binding if present, and bind the replacement payload cache entry with a host physical frame. |
| pc_send_bind(physaddr) | If the buffer is cached on the adapter, use existing binding, else find replacement and create new binding. |
| pc_receive_complete(physaddr) | The cache entry is now valid/bound. |
| pc_send_complete(physaddr) | If this is the last outstanding send, the cache entry is now valid/bound. |
| Payload Cache Management (exported to operating system) | |
| pc_invalidate_binding(physaddr) | Invalidate the payload cache entry bound to this physical address; the entry is now host_unbound. |
| pc_advise(physaddr, options) | Advise the payload cache manager to increase or decrease the payload cache entries priority. |
This section describes a prototype implementation of payload caching using Myrinet, a programmable high-speed network interface. It extends the design overview in the previous section with details relating to the operating system buffering policies.
We implemented payload caching as an extension to Trapeze [1,4], a firmware program for Myrinet, and associated Trapeze driver software for the FreeBSD operating system. The host-side payload cache module is implemented by 1600 lines of new code alongside a Trapeze device support package below the driver itself. While our prototype implementation is Myrinet-specific, the payload caching idea applies to Gigabit Ethernet and other network interfaces.
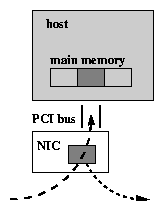
Our prototype integrates payload caching with FreeBSD extensions for zero-copy TCP/IP networking [5]. This system uses page remapping to move the data between applications and the operating system kernel through the socket interface, avoiding data copying in many common cases. This allows us to explore the benefit of payload caching for intermediaries whose performance is not dominated by superfluous copying overhead. Copy avoidance also simplifies the payload cache implementation because forwarded data is transmitted from the same physical host buffer used to receive it. Thus there is at most one host buffer bound to each payload cache entry.
The Trapeze network interface supports page remapping for TCP/IP networking by separating protocol headers from data payloads, and depositing payloads in page-aligned host payload buffers allocated from a pool of VM page frames by the driver. The payload caching prototype manages a simple one-to-one mapping of bound payload cache entries with cached host memory page frames; the buffer bound to each payload cache entry is identified by a simple physical address.
Any modification to a cached buffer page in the host invalidates the associated payload cache entry, if any. Page protections may be used to trap buffer updates in user space. Note, however, that changes or reconstruction of packet headers does not invalidate the cache entries for the packet payload. For example, a Web server accessing files from an NFS file server and sending them out over an HTTP connection may use the payload cache effectively.
Table 1 shows the interface exported by the payload cache module (pcache) to the Trapeze network driver and upper kernel layers. When the driver posts a transmit or receive, it invokes the pc_receive_bind or pc_send_bind routine in pcache to check the binding state of the target host buffer frames, and establish bindings to payload cache entries if necessary. The pcache module maintains a pcache entry table storing the physical address of the buffer bound to each entry, if any, and a binding table storing an entry ID for each frame of host memory. If a posted buffer frame is not yet bound to an entry, pcache finds a free entry or a suitable bound entry to evict.
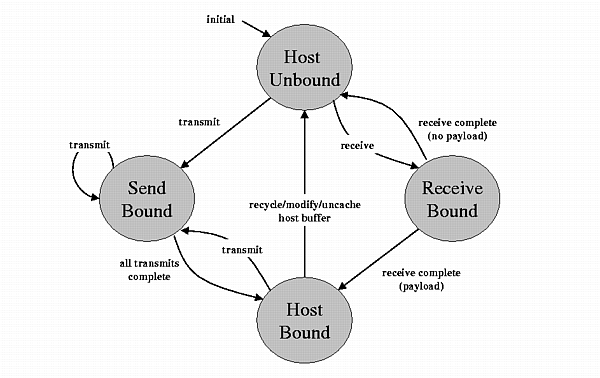
When a send or receive completes, the driver invokes the pcache pc_send_complete or pc_receive_complete routine. If there are no more pending I/O operations on an entry, and the recently completed I/O left the entry with valid data, then pcache transitions the entry to the host-bound state, shown earlier in Figure 3.
The pcache module exports routines called pc_invalidate_binding and pc_advise to the upper layers of the operating system kernel. The kernel uses these to invalidate a payload cache entry when its bound buffer is modified, or to inform pcache that the cached data is or is not valuable. For example, the OS may call pc_advise to mark an entry as an eviction candidate if its payload will not be forwarded.

The prototype gives eviction priority to data that has been received but not yet transmitted. Any payload cache entry that is not pending resides on one of three replacement queues: unbound (free), priority, and victim. Figure 4 shows the movement of payload cache entries between these queues and the NIC send/receive queues. Entries for completed sends move to the victim queue, while entries for completed receives move to the priority queue. Entries on either victim or priority transition to the unbound queue if they are invalidated or demoted by pc_advise. An evicted entry may come from any of these queues, in the following preference order: unbound, victim, priority.
Note that pcache manages the payload cache entirely within the host, including invalidation and replacement. Support for payload caching on the NIC is trivial. The host piggybacks all payload cache directives on other commands to the NIC (transmit and post receive), so payload caching imposes no measurable device or I/O overhead.
In normal forwarding operation, a payload caching host receives control and payload from the NIC, but transmits only headers across the I/O bus, sending forwarded payloads from the cache. For intermediaries that do not access most payloads - such as protocol translators, multicast nodes, or content switches - a natural progression is to extend the separation of control and payload data paths. In this case the NIC only passes control headers to the host, not data payloads. We term this configuration direct forwarding (in contrast to pcache forwarding). Our prototype supports direct forwarding mode with a small extension to the NIC firmware and a small change to the pcache module and driver. Payload cache entry management does not change.
Experimental results in Section 5 show that direct enables forwarding at link speeds, limited only by the CPU overhead for the forwarding logic. However, a pure direct policy is appropriate only when the payload cache is adequately sized for the link or if the send rate is held below the level that overflows the cache. This is because evictions in a direct payload cache discard the packet data, forcing the driver to drop any packet that misses in the payload cache in direct mode.
Section 5.5 shows that TCP congestion control adapts to automatically deliver maximum allowable bandwidth through a direct forwarder with very low miss rates in the presence of these packet drops. Even so, direct is narrowly useful as implemented in our prototype. It would be possible to enhance its generality by extending the NIC to DMA direct-cached payloads to the host before eviction or on demand. Another alternative might be to extend the NIC to adaptively revert from direct to pcache as it comes under load. We have not implemented these extensions in our prototype, but our implementation is sufficient to show the potential performance benefit from these more general approaches.
| Packet Size | Point to Point | Forwarding | pcache | direct |
| 1.5 KB | 82.31ms | 153.86ms | 140.15ms | 131.5ms |
| 4 KB | 108.36ms | 224.68ms | 191.68ms | 173.71ms |
| 8 KB | 159.2ms | 326.88ms | 285.94ms | 260.74ms |
This section explores the effectiveness of the payload caching prototype for a simple kernel-based forwarding proxy. The results show the effect of payload caching on forwarding latency and bandwidth for TCP streams and UDP packet flows, varying the payload cache size, number of concurrent streams, packet size, and per-packet processing costs in the forwarding host CPU.
While the hit rate in the payload cache directly affects the increase in throughput and decrease in latency, it is not simply a function of cache size or replacement policy. Understanding the interplay between payload caching and forwarder behavior allows us to establish ``real-world'' performance under a variety of scenarios.
We ran all experiments using Dell PowerEdge 4400 systems on a Trapeze/Myrinet network. The Dell 4400 has a 733 MHz Intel Xeon CPU (32KB L1 cache, 256KB L2 cache), a ServerWorks ServerSet III LE chipset, and 2-way interleaved RAM. End systems use M2M-PCI64B Myrinet adapters with 66 MHz LANai-7 processors. The forwarder uses a more powerful pre-production prototype Myrinet 2000 NIC with a 132 MHz LANai-9 processor, which does not saturate at the forwarding bandwidths achieved with payload caching. The Myrinet 2000 NIC on the forwarder uses up to 1.4 MB of its onboard RAM as a payload cache in our experiments. All NICs, running Trapeze firmware enhanced for payload caching, are connected to PCI slots matched to the 1 Gb/s network speed. Since the links are bidirectional, the bus may constrain forwarding bandwidth.
All nodes run FreeBSD 4.0 kernels. The forwarding proxy software used in these experiments consists of a set of extensions to an IP firewall module in the FreeBSD network stack. The forwarder intercepts TCP traffic to a designated virtual IP address and port, and queues it for a kernel thread that relays the traffic for each connection to a selected end node. Note that the forwarder acts as an intermediary for the TCP connection between the end nodes, rather than maintaining separate connections to each end node. In particular, the forwarder does no high-level protocol processing for TCP or UDP other than basic header recognition and header rewriting to hide the identity of the endpoints from each other using Network Address Translation (NAT). This software provides a basic forwarding mechanism for an efficient host-based content switch or load-balancing cluster front end. It is equivalent to the kernel-based forwarding supported for application-level proxies by TCP splicing [8].
To generate network traffic through the forwarder we used netperf version 2.1pl3, a standard tool for benchmarking TCP/IP networking performance, and Flowgen, a network traffic generator from the DiRT project at UNC.
Table 2 gives the latency for one-way UDP transfers with packet sizes of 1500 bytes, 4KB, and 8KB. Interposing a forwarding intermediary imposes latency penalties ranging from 86% for 1500-byte packets to 105% for 8KB packets. Payload caching ( pcache) reduces this latency penalty modestly, reducing forwarding latency by 8% for 1500-byte packets, 14% for 4KB packets, and 12% for 8KB packets. Direct forwarding ( direct) reduces forwarding latency further: the total latency improvement for direct is 14% for 1500-byte packets, 22% for 4KB packets, and 20% for 8KB packets.
This experiment yields a payload cache hit for every forwarded packet, regardless of cache size. The resulting latency savings stems from reduced I/O bus crossings in the forwarder. Pcache eliminates the I/O bus crossing on transmit, and direct eliminates bus crossings on both transmit and receive. For all experiments the NIC uses a store-and-forward buffering policy, so I/O bus latencies are additive.
Propagation delays are higher in wide-area networks, so the relative latency penalty of a forwarding intermediary is lower. Therefore, the relative latency benefit from payload caching is also lower.
The next experiment explores the role of the forwarder's packet processing overhead on payload cache hit rates across a range of cache sizes. It yields insight into the amount of NIC memory needed to achieve good payload cache hit rates under various conditions.
The NIC deposits incoming packets into host memory as fast as the I/O bus and NIC resources allow, generating interrupts to notify the host CPU of packet arrival. In FreeBSD, the NIC driver's receiver interrupt handler directly invokes the IP input processing routine for all new incoming packets; this runs the protocol and places the received data on an input queue for delivery to an application. Incoming packets may accumulate on these input queues if the forwarder CPU cannot keep up with the incoming traffic, or if the incoming traffic is bursty. This is because the NIC may interrupt the application for service from the driver as more packets arrive.
The behavior of these queues largely determines the hit rates in the payload cache. Consider our simple forwarder example. The forwarder application runs as a thread within the kernel, and the network driver's incoming packet handler may interrupt it. As the driver consumes each incoming packet accepted by the NIC, it allocates a new host buffer and payload cache entry to post a new receive so the NIC may accept another incoming packet. Under ideal conditions the driver simply allocates from unused entries released as the forwarder consumes packets from its input queue and forwards their payloads. However, suppose traffic bursts or processing delays cause packets to accumulate on the input queue, awaiting forwarding. Since each buffered packet consumes space in the payload cache, this forces pcache to replace payload cache entries for packets that have not yet been forwarded, reducing the hit rate.
It is easy to see that under MRU replacement the payload cache hit rate for the forwarder will roughly equal the percentage of the buffered packet payloads that fit in the payload cache. Once an MRU cache is full, any new entries are immediately evicted. With FIFO forwarding, every buffered payload that found space in the cache on arrival ultimately yields one hit when it is forwarded; every other buffered payload ultimately yields one miss. Thus the average hit rate can be found by determining the average forwarder queue length - the number of payloads buffered for forwarding in the host - and dividing into the payload cache size. Note that MRU is the optimal behavior in this case because there can be no benefit to replacing an older cached payload with a newer one until the older one has been forwarded.
Queuing theory predicts these forwarder queue lengths under common conditions, as a function of forwarder CPU overhead (per-packet CPU service demand) or CPU utilization. This experiment illustrates this behavior empirically, and also shows an interesting feedback effect of payload caching. We added a configurable per-packet CPU demand to the forwarder thread, and measured forwarder queue lengths and payload cache hit rate under a 25 MB/s (200 Mb/s) load of 4KB UDP packets. We used the UNC Flowgen tool to generate poisson-distributed interarrival gaps for even queue behavior. This allows us to explore the basic relationship between CPU demand and payload cache hit rate without the ``noise'' of the burstier packet arrivals common in practice.
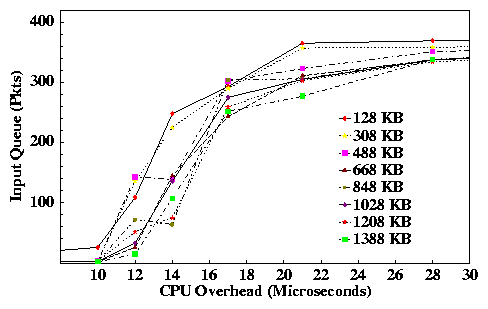
The left-hand graph of Figure 5 shows the average number of packets queued in the intermediary as a function of the CPU demand. We ran several experiments varying the effective payload cache size, the number of payload cache entries not reserved for pending receives. As expected, the queues grow rapidly as the CPU approaches saturation. In this case, the OS kernel bounds the input packet queue length at 400 packets; beyond this point the IP input routine drops incoming packets at the input queue. This figure also shows that the queues grow more slowly for large payload cache sizes. Queuing theory also predicts this effect: hits in the payload cache reduce the effective service demand for each packet by freeing up cycles in the I/O bus and memory system.
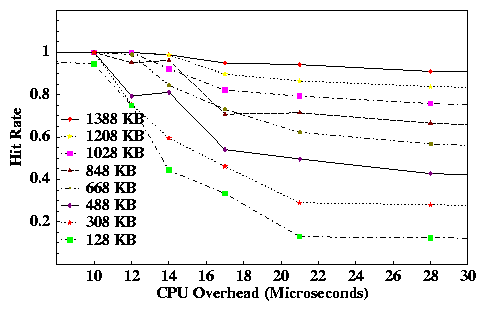
The right-hand graph of Figure 5 shows the average payload cache hit rate for the same runs. At low service demands, all packets buffered in the forwarder fit in the payload cache, yielding hit rates near 100%. As the forwarder queue lengths increase, a smaller share of the packet queue fits in the payload cache, and hit rates fall rapidly. As expected, the hit rate for each experiment is approximated by the portion of the packet queue that fits in the payload cache.
This experiment shows that a megabyte-range payload cache yields good hit rates if the CPU is powerful enough to handle its forwarding load without approaching saturation. As it turns out, this property is independent of bandwidth; if CPU power scales with link rates then payload caching will yield similar hit rates at much higher bandwidths. On the other hand, payload caching is not effective if the CPU runs close to its capacity, but this case is undesirable anyway because queueing delays in the intermediary impose high latency.
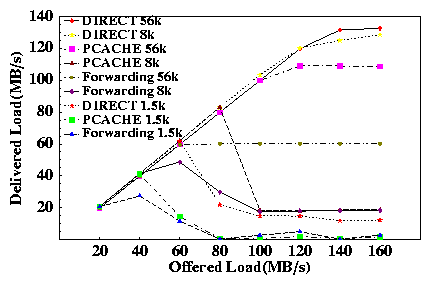
The next experiment shows the bandwidth benefits of payload caching for netperf UDP packet flows. Figure 6 shows delivered UDP forwarding bandwidth as a function of input traffic rate for packet sizes of 1500 bytes, 8KB, and 56KB. The payload cache size is fixed at 1.4 MB. Bandwidth is measured as the number of bytes arriving at the receiver per unit of time. For these experiments, smaller packet sizes saturate the CPU at modest bandwidths; since UDP has no congestion control, the saturated intermediary drops many packets off of its input queues, but only after consuming resources to accept them. This livelock causes a significant drop in delivered bandwidth beyond saturation.
With 1500-byte packets, packet handling costs quickly saturate the forwarder's CPU, limiting forwarding bandwidth to 29 MB/s. pcache improves peak forwarding bandwidth by 35% to 40 MB/s. In this case, the benefit from pcache stems primarily from reduced memory bandwidth demand to forward each packet, as hits in the payload cache reduce the number of bytes transmitted from host memory.
The 8KB packets reduce packet handling costs per byte of data transferred, easing the load on the CPU. In this case, the CPU and the I/O bus are roughly in balance, and both are close to saturation at the peak forwarding rate of 48 MB/s. pcache improves the peak forwarding bandwidth by 75% to 84 MB/s due to reduced load on the I/O bus and on the forwarder's memory.
With 56KB packets, forwarding performance is limited only by the I/O bus. The base forwarding rate is roughly one-half the I/O bus bandwidth at 60 MB/s, since each payload crosses the bus twice. With pcache, the forwarding bandwidth doubles to 110 MB/s, approaching the full I/O bus bandwidth. This shows that payload caching yields the largest benefit when the I/O bus is the bottleneck resource, since it cuts bus utilization by half under ideal conditions. A faster CPU would show a similar result at smaller packet sizes. Note that for 56KB packets the forwarding rate never falls from its peak. This is because the CPU is not saturated; since the I/O bus is the bottleneck resource, the input rate at the forwarder is limited by link-level flow control on the Myrinet network. This is the only significant respect in which our experiments are not representative of more typical IP networking technologies.
The direct policy reduces memory and I/O bus bandwidth demands further, and sustains much higher bandwidth across all packet sizes. At 1500 bytes, direct reduces CPU load further than pcache, yielding a peak forwarding bandwidth of 60 MB/s. Direct can forward at a full 1 Gb/s for a 56KB packet size, with the CPU load at 20% and the I/O bus mostly idle for use by other devices. However, a payload cache miss affects bandwidth much more for direct than for pcache, since a miss results in a packet drop. In these experiments, direct suffered a 22% miss rate for a 100 MB/s input rate with 8KB MTU. The next section shows that TCP congestion control adapts to throttle the send rate when packets are dropped, yielding the best bandwidth and high hit rates for direct.
We now show the effectiveness of payload caching for fast forwarding of TCP streams. For this experiment, we used netperf on four clients to initiate sixteen simultaneous TCP streams to a single server through a forwarding intermediary, with the interface Maximum Transmission Unit (MTU) configured to 1500 bytes or 8KB (Jumbo frames).
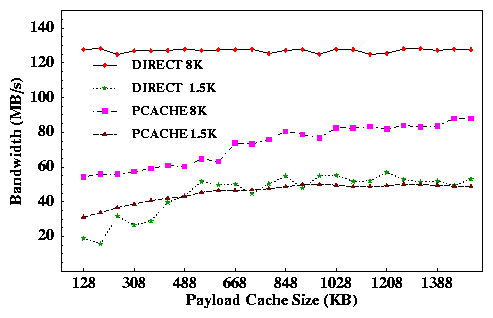
Figure 7 shows the resulting aggregate bandwidth and payload cache hit rate as a function of effective payload cache size. The graph does not show forwarding bandwidths without payload caching, since they are constant at the throughputs achieved with the smallest payload cache sizes. These base throughputs are 30 MB/s (240 Mb/s) with 1500-byte MTUs and 55 MB/s (440 Mb/s) with 8KB MTUs.
Using pcache, aggregate TCP bandwidth through the forwarder rises steadily as the payload cache size increases. With 1500-byte MTUs, payload caching improves bandwidth by 56% from 30 MB/s to a peak rate of 47 MB/s. With 8KB MTUs, payload caching improves bandwidth by 60% from 55 MB/s to 88 MB/s at the 1.4 MB payload cache size. It is interesting to note that these bandwidths are slightly higher than the peak bandwidths measured with UDP flows. This is because TCP's congestion control policy throttles the sender on packet drops. We measured slightly lower peak bandwidths for a single TCP stream; for example, a single stream with 8KB MTUs yields a peak bandwidth of 85 MB/s through a payload caching forwarder.
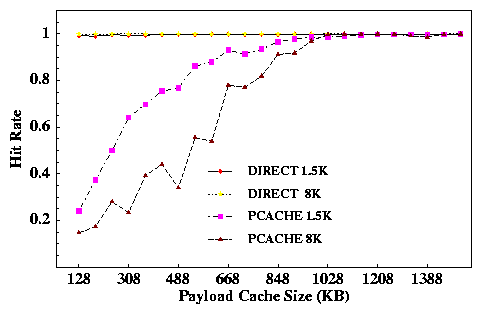
The right-hand graph in Figure 7 shows the payload cache hit rates for the same runs. Hit rates for the pcache runs rise steadily as the payload cache size increases, driving forwarding bandwidth up. For this experiment a megabyte of payload cache is sufficient to yield 100% hit ratios for all experiments.
Using direct forwarding ( direct) yields even higher peak bandwidths. A direct forwarder handles traffic at a full gigabit per second with 8KB MTUs, despite its I/O bus limitation. It might seem anomalous that bandwidth rises with larger cache sizes, even as the hit rate appears to be pegged at 100% even with small sizes. This effect occurs because all payload cache misses under direct result in packet drops. Although a very small number of misses actually occur, they are sufficient to allow TCP's congestion control policy to quickly converge on the peak bandwidth achievable for a given cache size. With pcache, a payload cache miss only increases forwarding cost for an individual packet, which alone is not sufficient to cause TCP to throttle back until a queue overflows, forcing a packet drop. In all of our experiments, TCP congestion control policies automatically adjusted the send rate to induce peak performance from a payload caching forwarder.
This section sets payload caching in context with complementary work sharing similar goals. Related techniques include peer-to-peer DMA, TCP splicing, and copy avoidance.
Like payload caching, peer-to-peer DMA is a technique that reduces data movement across the I/O bus for forwarding intermediaries. Data moves directly from the input device to the output device without indirecting through the host memory. Peer-to-peer DMA has been used to construct scalable host-based IP routers in the Atomic project at USC/ISI [18], the Suez router at SUNYSB [16], and Spine at UW [11]. The Spine project also explores transferring the forwarded payload directly from the ingress NIC to the egress NIC across an internal Myrinet interconnect in a scalable router. Like direct payload caching, this avoids both I/O bus crossings on each NIC's host, reducing CPU load as well. In contrast to peer-to-peer DMA, payload caching assumes that the ingress link and the egress link share device buffers, i.e., they are the same link or they reside on the same NIC. While payload caching and peer-to-peer DMA both forward each payload with a single bus crossing, payload caching allows the host to examine the data and possibly modify the headers. Peer-to-peer DMA assumes that the host does not examine the data; if this is the case then direct payload caching can eliminate all bus crossings.
TCP splicing [8] is used in user-level forwarding intermediaries such as TCP gateways, proxies [17], and host-based redirecting switches [6]. A TCP splice efficiently bridges separate TCP connections held by the intermediary to the data producer and consumer. Typically, the splicing forwarder performs minimal processing beyond the IP layer, and simply modifies the source, destination, sequence numbers, and checksum fields in each TCP header before forwarding it. A similar technique has also been used in content switches [3], in which the port controller performs the sequence number translation. Once a TCP splice is performed, the data movement is similar to the NAT forwarding intermediary used in our experiments.
The primary goal of TCP splicing is to avoid copying forwarded data within the host. Similarly, many other techniques reduce copy overhead for network communication (e.g., Fbufs [7], I/O-Lite [15], and other approaches surveyed in [5]). These techniques are complementary to payload caching, which is designed to reduce overhead from unnecessary I/O bus transfers.
Data in the Internet is often forwarded through intermediaries as it travels from server to client. As network speeds advance, the trend in Web architecture and other large-scale data delivery systems is towards increasing redirection through network intermediaries, including firewalls, protocol translators, caching proxies, redirecting switches, multicasting overlay networks, and servers backed by network storage.
Payload caching is a technique that reduces the overhead of data forwarding, while retaining the flexibility of host-based architectures for network intermediaries. By intelligently managing a cache of data payloads on the network adapter (NIC), the host can improve forwarding bandwidth and latency.
This paper shows how to incorporate payload caching into Unix-based frameworks for high-speed TCP/IP networking. It shows the interface between the host and the NIC and the new host functions to manage the payload cache. A key feature of our system is that the host controls all aspects of payload cache management and replacement, simplifying the NIC and allowing the host to use application knowledge to derive the best benefit from the cache. The NIC support for our payload caching architecture is straightforward, and we hope that future commercial NICs will support it.
Experimental results from the prototype show that payload caching and the direct forwarding extension improve forwarding bandwidth through host-based intermediaries by 40% to 60% under realistic scenarios, or up to 100% under ideal conditions. TCP congestion control automatically induces peak forwarding bandwidth from payload caching intermediaries. These bandwidth improvements were measured using effective payload cache sizes in the one-megabyte range on a gigabit-per-second network.
Over the years many people have contributed to the development and success of the Trapeze project. Most notably Andrew Gallatin for his FreeBSD expertise and Bob Felderman at Myricom for his timely help. We thank the anonymous reviewers and our shepherd, Mohit Aron, for helpful critiques and suggestions.
1 Author's address:
Department of Computer Science, Duke University, Durham, NC 27708-0129
USA. This work is supported by the National Science Foundation
(through EIA-9870724 and EIA-9972879), Intel Corporation, and Myricom.
File translated from TEX by TTH, version 1.50.
|
This paper was originally published in the
Proceedings of the 2001 USENIX Annual Technical Conference, June
25Đ30, 2001, Boston, Massachusetts, USA.
Last changed: 3 Jan. 2002 ml |
|