



Next: Netperf Results
Up: Microbenchmarking Tools
Previous: Microbenchmarking Tools
In order to publish lmbench results in a public forum, the lmbench
license requires that the benchmark code must be compiled with a
``standard'' level of optimization (-O only) and that all the
results produced by the lmbench suite must be published. These two
rules together ensure that the results produced compare as fairly as
possible apples to apples when considering multiple platforms, and
prevents vendors or overzealous computer scientists from seeking "magic"
combinations of optimizations that improve one result (which they then
selectively publish) at the expense of others.
Accordingly, on the following page is a full set of lmbench results
generated for ``lucifer'', the primary server node for my home
(primarily development) beowulf [Eden]. The mean values and error
estimates were generated from averaging ten independent runs of the full
benchmark. lucifer is a 466 MHz dual Celeron system, permitting
it to function (in principle) simultaneously as a master node and as a
participant node. The cpu-rate results are also included on this page
for completeness although they may be superseded by Carl Staelin's
superior hardware instruction latency measures in the future.
Table 1:
Lucifer System Description
| HOST |
lucifer |
| CPU |
Celeron (Mendocino) (x2) |
| CPU Family |
i686 |
| MHz |
467 |
| L1 Cache Size |
16 KB (code)/16 KB (data) |
| L2 Cache Size |
128 KB |
| Motherboard |
Abit BP6 |
| Memory |
128 MB of PC100 SDRAM |
| OS Kernel |
Linux 2.2.14-5.0smp |
| Network (100BT) |
Lite-On 82c168 PNIC rev 32 |
| Network Switch |
Netgear FS108 |
|
Table 2:
lmbench latencies for selected processor/process activities.
The values are all times in microseconds averaged over ten independent
runs (with error estimates provided by an unbiased standard deviation),
so ``smaller is better''.
| null call |
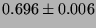 |
| null I/O |
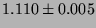 |
| stat |
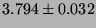 |
| open/close |
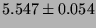 |
| select |
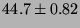 |
| signal install |
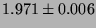 |
| signal catch |
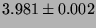 |
| fork proc |
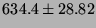 |
| exec proc |
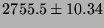 |
| shell proc |
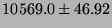 |
|
Table 3:
Lmbench latencies for context switches, in microseconds
(smaller is better).
| 2p/0K |
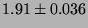 |
| 2p/16K |
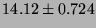 |
| 2p/64K |
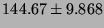 |
| 8p/0K |
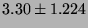 |
| 8p/16K |
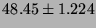 |
| 8p/64K |
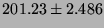 |
| 16p/0K |
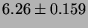 |
| 16p/16K |
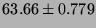 |
| 16p/64K |
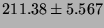 |
|
Table 4:
Lmbench local communication latencies, in microseconds
(smaller is better).
| pipe |
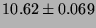 |
| AF UNIX |
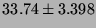 |
| UDP |
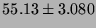 |
| TCP |
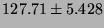 |
| TCP Connect |
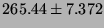 |
| RPC/UDP |
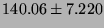 |
| RPC/TCP |
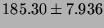 |
|
Table 5:
Lmbench network communication latencies, in microseconds
(smaller is better).
| UDP |
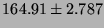 |
| TCP |
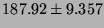 |
| TCP Connect |
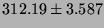 |
| RPC/UDP |
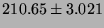 |
| RPC/TCP |
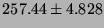 |
|
Table 6:
Lmbench memory latencies in nanoseconds (smaller is
better). Also see graphs for more complete picture.
| L1 Cache |
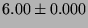 |
| L2 Cache |
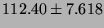 |
| Main mem |
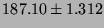 |
|
Table 7:
Lmbench local communication bandwidths, in  bytes/second (bigger is better).
bytes/second (bigger is better).
| pipe |
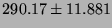 |
| AF UNIX |
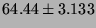 |
| TCP |
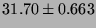 |
| UDP |
(not available) |
| bcopy (libc) |
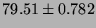 |
| bcopy (hand) |
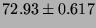 |
| mem read |
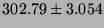 |
| mem write |
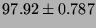 |
|
Table 8:
Lmbench network communication bandwidths, in
bytes/second (bigger is better).
| TCP |
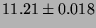 |
| UDP |
(not available) |
|
Table 9:
CPU-rates in BOGOMFLOPS - simple arithmetic
operations/second, in L1 cache (bigger is better). Also see graph for
out-of-cache performance.
| Single precision |
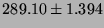 |
| Double precision |
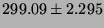 |
|
lmbench clearly produces an extremely detailed picture of
microscopic systems performance. Many of these numbers are of obvious
interest to beowulf designers and have indeed been discussed (in many
cases without a sound quantitative basis) on the beowulf list
[beowulf]. We must focus in order to conduct a sane discussion in
the allotted space. In the following subsections on we will consider
the network, the memory, and the cpu-rates as primary contributors to
beowulf and parallel code design.
These are not at all independent. The rate at which the system does
floating point arithmetic on streaming vectors of numbers is very
strongly determined by the relative size of the L1 and L2 cache and the
size of the vector(s) in question. Significant (and somewhat
unexpected) structure is also revealed in network performance as a
function of packet size, which suggests ``interesting'' interactions
between the network, the memory subsystem, and the operating system that
are worthy of further study.
Next: Netperf Results
Up: Microbenchmarking Tools
Previous: Microbenchmarking Tools
Robert G. Brown
2000-08-28