
| ||||||||||||||||||||||||||||||||||||||||||||||||||||
WIESS 2000 Paper
[WIESS Tech Program Index]
Stub-Code Performance is Becoming Important
AbstractAs IPC mechanisms become faster, stub-code efficiency becomes a performance issue for local client/server RPCs and inter-component communication. Inefficient and unnecessary complex marshalling code can almost double communication costs. We have developed an experimental new IDL compiler that produces near-optimal stub code for gcc and the L4 microkernel. The current experimental IDL4 compiler cooperates with the gcc compiler and its x86 code generator. Other compilers or target machines would require different optimizations. In most cases, the generated stub code is approximately 3 times faster (and shorter) than the code generated by a commonly used portable IDL compiler. Benchmarks have shown that efficient stubs can increase application performance by more than 10 percent. The results are applied within IBM’s SawMill project that aims at technology for constructing multi-server operating systems.
1 MotivationMulti-server and component-based systems are promising architectural approaches for handling the ever-increasing complexity of operating and application systems. Components or servers (and clients) communicate with each other through cross-domain method invocations. Such interface method invocations, if crossing protection boundaries, are typically implemented through the inter-process communication (IPC) mechanisms offered by a microkernel.Firstly, component interaction in such systems has to be highly efficient. Therefore, for over a decade, performance-oriented research focused on microkernel construction, in particular IPC performance, finally resulting in acceptable IPC overheads (100...200 cycles) [6, 2]. Secondly, component interaction has to be conveniently usable from an application programmer’s perspective. This requirement led to the development of interface-definition languages (IDLs), e.g. Corba IDL [7], DCOM [3] and their corresponding IDL compilers. From interface procedure/method definitions, such compilers generate stub code that marshals parameters on the client side, communicates through IPC or RPC kernel primitives with the server, unmarshals the parameters on the server side, invokes the corresponding server procedure/method, etc. As a result, a programmer can specify and use remote interfaces as easily as internal ones. So far, IDL-compiler research has focused more on generating code in a portable and adaptable way than on producing efficient stubs. In fact, stub-code performance was insignificant for early microkernels that required multiple thousands of cycles per IPC. However, with high-performance IPC, stub-code efficiency becomes an issue. For example, when using the Flick IDL compiler [4] for the SawMill Linux file system [5], we found that the generated user-level stub code consumed about 260 instructions per read request. When reading a 4K block from the file system, the stub code adds an overhead of about 17% due to stub instructions. (The stub code may also generates further indirect costs through side effects such as cache pollution.) For an industrial system, such overheads can no longer be ignored. Hand coding of the aforementioned stub resulted in 80 instead of 260 instructions. Although this was a singular experiment, it gave us some evidence that improving stub-code generation might be worthwhile. The potentially achievable reductions justified a compiler-construction experiment to explore whether near-optimal stub code can be generated at reasonable costs. This paper describes the resulting IDL4 compiler that generates code for gcc on x86 and the L4 microkernel. The current IDL4 is a prototype that purely focuses on generating efficient code. Portability and adaptability are ignored and remain a topic for future work.
Structure of the paperThis paper reports on progress that has been made with IDL4, an experimental IDL compiler for the L4 microkernel. Section 2 sketches prerequisites for understanding the subsequent discussion such as IDL syntax, L4-IPC mechanisms, and our experiences using the Flick IDL compiler in the SawMill project. Section 3 describes the stub-code model that was designed for the IDL4 compiler, and Section 4 illustrates the code-generation principles. Finally, Section 5 reports on the achieved stub-code quality, Section 6 discusses the costs of adapting the system to other processor architectures and compilers, and Section 7 concludes.
2 Prerequisites2.1 L4/x86 IPCL4’s [6] basic communication paradigm is synchronous IPC. Typical operations are send, receive, call (atomic send&receive), and atomic reply&wait. Rich message types help to improve end-to-end IPC performance:Register messages consist of a small number of 32-bit words that are sent and received in general purpose registers. On the x86 platform, up to 3 words (plus sender id and message descriptor) can be transferred as a register message. As there is no need for copy operations across address space boundaries, register messages have the lowest IPC costs, e.g. 180 cycles on a Pentium III 450 MHz. Memory messages can be used to copy longer messages from the sender’s address space to the receiver. Message size can be up to 2MB; however, this mechanism is slower than a register message because it involves copying from/to memory, and the kernel might have to establish a temporary mapping to make both address spaces available at the same time.
Map messages map pages or larger parts of the sender’s address space into the receiver’s space. This feature enables user-level pagers and main-memory management on top of the microkernel. Special communication mechanisms based on shared regions can also be constructed.
2.2 SawMillIBM’s SawMill project aims at addressing the complexity of developing and maintaining a variety of custom operating systems. With the emergence of embedded and personal systems, the need to create operating systems customized to device and application requirements has increased significantly. The development and maintenance of these operating systems is quite unwieldy. As a first step, the SawMill project is developing an approach and tools to decompose existing operating systems into flexibly reusable components. The next step is to define an architecture upon which efficient and robust operating systems can be composed. This framework is being applied to Linux to create SawMill Linux which consists of Linux-based components running on top of the L4 microkernel. It provides typical system services through multiple user-level servers, such as file systems, device drivers and network systems. Further general components such as memory servers, task servers, and access control managers enable the composition of a coherent Linux system.
2.3 FlickIDL Compilers such as Flick [4] are relatively easy to port to a new OS or middleware kernel, and they are extensible through new data types. The output of an IDL compiler is typically used as input for a general-purpose compiler, e.g. gcc, that a programmer uses for code development. Easy adaptation of the IDL compiler to new general-purpose compilers is a further relevant property.Flick tries to generate efficient stub code by using inline functions and macros for the generated stubs whenever possible. Nevertheless, at least when combined with gcc, this results in huge amounts of data transfer operations that are logically superfluous. In theory, a compiler should be able to remove all of them. In practice, the required data flow analysis is too complicated; consequently, inefficient code is generated.
3 Designing a Stub Model3.1 A Simple Stub ModelWe first describe a simple stub model to illustrate the tasks performed by stub code on the client side and on the server side. For this simple model, we assume that a client invokes a procedure or method M that is supplied by the server. Synchronization and concurrency are ignored in this simple model. M has in parameters (values passed from the client to the server), out parameters (result values passed from the server back to the client), and inout parameters that are first passed to the server and then overwritten by results coming back from the server.The IDL compiler generates a client stub procedure M_client for each function M in the interface definition. The client stub is called locally by the client application. The fact remains hidden that the service function does not run locally, but rather in another address space or even on another computer thousands of miles away. The client stub assembles a message with all the information the server requires to complete the task, including all the parameters (marshalling). The message is then sent to the server, and the client waits for the server’s reply. The reply message contains all out and inout result values. The client stub unpacks these values from the message and stores them in the appropriate client parameters (unmarshalling). In detail, the client stub M_client
The server programmer implements a procedure M_server on the server side for each method M of the interface definition. The IDL compiler generates a central code pattern that handles communication, decoding, marshalling, and unmarshalling of parameters. This central server code typically includes a main loop that receives requests from clients and distributes them to the corresponding server procedures M_server. For each M_server, the IDL compiler generates a server stub that examines the request packet and retrieves the input data (unmarshalling). The stub then invokes the routine itself and finally creates a reply for the client. An IDL compiler should generate both the main loop and the stubs automatically. Users should be able to easily modify the loop code, because they might want to implement additional features, e.g. load balancing. In detail, a thread that waits for client requests
Steps C2, S0, and S4 are basically determined by the underlying IPC system, in our case by the L4 microkernel. Steps C4 and S2 are determined by the general-purpose compiler used, in our case gcc. Marshalling and unmarshalling, steps C1+S1 and S3+C3, are less restricted and more crucial. As our experience with Flick shows, a less optimal model can easily result in significant copy overhead for marshalling and unmarshalling.
3.2 Marshalling Through Direct Stack Transfer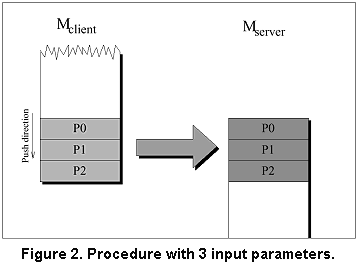 To get an idea of how parameters can be communicated
most efficiently between M_client and M_server, we
first look at a local procedure call. Gcc and many other
C compilers push input-parameter values on the stack
prior to procedure invocation. Figure 2 shows the stack
layout for a procedure called with 3 input parameters.
Now look at the remote case. Three parameter values
have just been pushed on to the client stack (left,
M_client). On the server side (right), M_server
would ideally expect a stack of exactly the same content since
M_server has exactly the same parameters as M_client.
Basically, the stub code had to copy the stack frame one-to-one
from the client to the server stack. No additional
operations would be required for parameter marshalling/unmarshalling.
To get an idea of how parameters can be communicated
most efficiently between M_client and M_server, we
first look at a local procedure call. Gcc and many other
C compilers push input-parameter values on the stack
prior to procedure invocation. Figure 2 shows the stack
layout for a procedure called with 3 input parameters.
Now look at the remote case. Three parameter values
have just been pushed on to the client stack (left,
M_client). On the server side (right), M_server
would ideally expect a stack of exactly the same content since
M_server has exactly the same parameters as M_client.
Basically, the stub code had to copy the stack frame one-to-one
from the client to the server stack. No additional
operations would be required for parameter marshalling/unmarshalling.Since out parameters in C are typically implemented through pointers (which are passed as in parameters), we have to extend the parameter set by pointers that point to those variables that are later sent back to the client as out parameters. Figure 3 illustrates the three basic layouts:
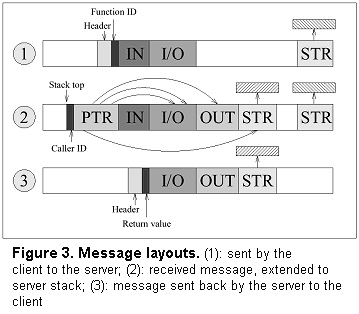
¹ A similar sorting mechanism is used to
collect string parameters and pages to be mapped
3.3 Complex Data TypesAt this time, the only data types IDL4 handles are 32-bit words and strings (up to 2 MB). It will be extended by pages to also handle mapping through IDL functions. Any other data type can be implemented through those basic types. Large objects like arrays or structs can be transferred as strings, while small objects (characters, short integers) may safely be extended to 32-bit words. Extending smaller objects to words has no additional costs since gcc maps such objects to words anyhow when generating local function calls. Implementing large data types as indirect strings is beneficial since it avoids copying them into the message buffer.
4 Generated Code - An ExampleTo further illustrate details, we analyze the output that the compiler generates for the function pfs_write of the physical file system (pfs): int pfs_write([in] int handle,
[in, out] int *pos,
[in] int len,
[in] int data_size,
[in, size_is(data_size)] int *data);
IDL4 generates three files which contain the client stubs,
the server stubs and the main server loop. Client and
server stubs are generated as asm functions for gcc. The
server loop is in C so that it can easily be modified by an
application programmer. It is common to all functions and decodes
incoming requests, i.e. selects the appropriate server function and
invokes it through the server stub:
setupNewBuffer();
ipcReceive();
do {
unpackQuery();
callStub();
packResponse();
setupNewBuffer();
ipcReplyWait();
} while (1);
Client stubTable 1 shows the output IDL4 creates for the pfs_write() call on the client side. Assuming it hands over two parameters in registers, this stub consists of 17 instructions. In detail, the code sections (referring to the numbers in the code) work as follows:
Server stubThe stub (see Table 2) is called from the server loop. It converts the request message from the client into a stack frame for the server function:
5 Performance5.1 Measurement Environment - SawMill LinuxIDL4 is used in the SawMill project for component communications. SawMill Linux is a Linux-derived multiserver OS where physical file systems (PFS), file and buffer cache, device drivers, network stack, VM subsystems such as anonymous memory, etc. are all implemented as user-level servers that communicate through L4 IPC and IDL4 stubs.For SawMill, we analyze the stubs that are required to let a normal Linux process execute file-system operations such as open, read, and write. The physical file system we used in the experiments is compatible to Linux’ ext2. In fact, the ext2 code was extracted from Linux and then combined with IDL4-generated server templates. The resulting ext2-compliant PFS runs as a user-level server in its own address space. Libraries have been modified such that now IDL4 stubs and L4 IPC communicate with SawMill servers. An open request is always sent first to the virtual file system (VFS) which propagates it to the corresponding PFS server. Subsequent read/write requests, however, are handled through direct communication between the user application and that PFS server, i.e., need only one RPC (two IPCs). The normal SawMill Linux has all stubs generated by the IDL4 compiler. In addition, we generated a second version of SawMill Linux whose stubs were all generated by the Flick compiler. For both versions, we measured stub instructions and application performance. For our measurements, we used a Pentium III running at 500 MHz with 64 MB of main memory and a 540 MB IDE disk drive (IBM DALA-3540).
5.2 Effects On IOzone ThroughputThe IOzone benchmark [1] begins by writing a file of 64kB, then it reads the contents twice. In the second read phase, all requests can be backed by the page cache. The performance of the second phase is completely determined by processor operations, basically for communication and for copying data into the user program’s buffer, and not by disk accesses.We measured reread throughput where IOzone read 4 KB² of file data per read request. Table 3 presents the overall performance results reported by IOzone (ten consecutive iterations). IDL4 improves the IOzone throughput by approximately 13%. The time for a 4-KB read request decreases from 8.0 µs to 7.0 µs. Since reread costs are dominated by the data copy costs this result can only be explained by significant improvements in stub code.
in the IOzone benchmark.
² Longer read requests effectively
decrease application performance, independently of whether pure monolithic
Linux or SawMill/Flick or SawMill/IDL4 is used: The Pentium L1 cache has
a size of 16 KB. If, e.g., 8 KB of data are copied from the page cache
to the user buffer, this operation already floods the entire cache. So every
other application or file system data access leads at first to a cache
miss. Furthermore, since some further cache lines are also used for the
data copy, the first part of the user buffer will be flushed from L1 at the
end of the copy operation. Effectively, most application accesses to
the data read will thus also lead to L1 cache miss except if a clever application
would read its data or if the OS would copy its data in reverse
direction.
5.3 Stub-Code InstructionsTo analyze the stub-code performance, we counted the executed instructions for the Flick-generated and the IDL4-generated stubs. Table 4 compares the results for three SawMill file-system functions, pfs_open, pfs_write, and pfs_get_direntries. The numbers include all instructions that are executed in stubs and in the central server loop. For comparison, the number of instructions the L4 microkernel executes for the corresponding IPCs is also included. (Note that complex operations such as block transfer operations are counted per iteration.) The effective communication costs are then given by adding the stub costs - either Flick or IDL4 - to the IPC costs.
Flick stubs take almost as many instructions as the microkernel needs for the IPC system call (including the message copy). Current IDL4 stubs use only half as many instructions.
6 Portability Versus SpecializationThe IDL4 experiment gave us some evidence that specialization in stub-code generation pays and is perhaps even necessary for industrial acceptance of component-based system construction. However, the obvious questions are (1) how portable can an optimizing IDL code generator be made, and (2) what efforts are required to port a specific code generator to a different compiler or machine architecture?Currently, the IDL4 code generation is specialized for the gcc compiler and x86 processors. From our current experience, we can give some raw estimates about the costs to adapt IDL4 to other architectures:
7 ConclusionsIDL4 shows that efficient stub code can be generated with reasonable effort. With the availability of fast IPC, the gains achievable through optimized stub code are becoming relevant for component-based systems. Multiserver operating systems can probably not be built efficiently without such optimized stubs.We have shown that significant performance improvements are possible. Nevertheless, it is still open, how far the current IDL4-generated stubs are from the optimum. The optimized stub-code generation requires specialization of the IDL compiler’s code generator in two dimensions, firstly, toward the target programming language and compiler, secondly, toward the target machine. In this area, two questions are still open: (1) How specialized (with respect to acceptable efficiency) must an optimizing IDL compiler be? (2) Can we find a small set of templates and/or methods that permit easy and low-cost specialization of an optimizing IDL compiler for most existing programming-language compilers and hardware architectures? An obvious next step therefore is to determine whether and how the current results can be generalized. An ideal solution would permit extension of the portable Flick compiler with the presented code-generation techniques. References
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
This paper was originally published by the USENIX Association in the
Proceedings of the First WIESS Workshop,
October 22, 2000, San Diego, California, USA
Last changed: 23 Jan. 2002 ml |
|

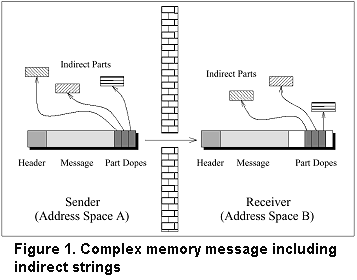 Indirect strings avoid unnecessary copy operations
to/from the message buffer. Up to 31 strings can be
included in a memory message. On the receiver side,
buffers for such strings can be specified so that the IPC
can copy directly from server object to client object or
vice versa. Scatter/gather permits strings to be gathered
on the sender side and/or scattered on the receiver
side. Thus multiple blocks can be directly transferred to
a single receive buffer; a single send buffer can be split
into multiple blocks. Figure 1 illustrates how a complex
memory message is transferred.
Indirect strings avoid unnecessary copy operations
to/from the message buffer. Up to 31 strings can be
included in a memory message. On the receiver side,
buffers for such strings can be specified so that the IPC
can copy directly from server object to client object or
vice versa. Scatter/gather permits strings to be gathered
on the sender side and/or scattered on the receiver
side. Thus multiple blocks can be directly transferred to
a single receive buffer; a single send buffer can be split
into multiple blocks. Figure 1 illustrates how a complex
memory message is transferred.