| ||||||||||||||||||||||||||||||||||||||||||||||||||||
|
USITS '03 Paper
[USITS '03 Tech Program Index]
Using Random Subsets to Build Scalable Network ServicesDejan Kostic, Adolfo Rodriguez, Jeannie Albrecht, Abhijeet Bhirud, and Amin Vahdat1
Abstract:
In this paper, we argue that a broad range of large-scale network
services would benefit from a scalable mechanism for delivering state
about a random subset of global participants. Key to this approach is
ensuring that membership in the subset changes periodically and with
uniform representation over all participants. Random
subsets could help overcome inherent scaling limitations to services
that maintain global state and perform global network
probing. It could further improve the routing performance of
peer-to-peer distributed hash tables by locating topologically-close
nodes. This paper presents the design, implementation, and evaluation
of RanSub, a scalable protocol for delivering such state.
As a first demonstration of the RanSub utility, we construct SARO, a scalable and adaptive application-layer overlay tree. SARO uses RanSub state information to locate appropriate peers for meeting application-specific delay and bandwidth targets and to dynamically adapt to changing network conditions. A large-scale evaluation of 1000 overlay nodes participating in an emulated 20,000-node wide-area network topology demonstrate both the adaptivity and scalability (in terms of per-node state and network overhead) of both RanSub and SARO. Finally, we use an existing streaming media server to distribute content through SARO running on top of the PlanetLab Internet testbed.
Many distributed services must track the characteristics of a subset
of their peers. This information is used for failure detection,
routing, application-layer multicast, resource discovery, or update
propagation. Ideally, the size of this subset would equal the number
of all global participants to provide each node with the highest
quality information. Unfortunately, this approach breaks down beyond
a few tens of nodes across the wide-area, encountering scalability
limitations both in terms of per-node state and network overhead.
Recent work suggests building scalable distributed systems on top of a
location infrastructure where each node can quickly (in | ||||||||||||||||||||||||||||||||||||||||||||||
| ||||||||||||||||||||
Overall, the goal of the Collect message is for each node to: i) compose the collect sets for constructing the distribute set during the subsequent distribute phase, and ii) determine the total number of participants in its local subtree.
The collect phase begins at the leaves of the tree in response to the
reception of a Distribute message. Table 1
describes all the fields in Collect messages (in the left half of the
table). The Collect message has the same sequence number as the
triggering Distribute message. At the leaves, the number of
descendants is set to one and the collect set contains only the leaf
node itself. Once a parent receives all Collect messages from its
children, it further propagates a Collect message to its own parent.
The nodes in the collect set are selected randomly from the
collect sets received from its children to form a subset of
configurable size (![]() by default). Each node stores this
collect set to aid in the construction of distribute sets distributed
to its children during the subsequent distribute phase.
by default). Each node stores this
collect set to aid in the construction of distribute sets distributed
to its children during the subsequent distribute phase.
One key challenge is to ensure that membership in the collect set
propagated by a node, ![]() , to its parent is both random and uniformly
representative of all members of the sub-tree rooted at
, to its parent is both random and uniformly
representative of all members of the sub-tree rooted at ![]() . To
achieve this, RanSub makes use of a
. To
achieve this, RanSub makes use of a ![]() operation, which takes
as input multiple subsets and the total population represented by each
subset.
operation, which takes
as input multiple subsets and the total population represented by each
subset. ![]() outputs a new subset with two properties: i) group
membership randomly chosen over the input subsets and ii) a target
size constraint. This is achieved by building the output set
incrementally. We first randomly choose an input subset based on the
population that it represents. We then randomly choose a member of
this subset (not already selected) and add it to the output set.
Consider the case where
outputs a new subset with two properties: i) group
membership randomly chosen over the input subsets and ii) a target
size constraint. This is achieved by building the output set
incrementally. We first randomly choose an input subset based on the
population that it represents. We then randomly choose a member of
this subset (not already selected) and add it to the output set.
Consider the case where ![]() were performed over two subsets,
were performed over two subsets, ![]() and
and ![]() .
. ![]() and
and ![]() each contain 8 members,
each contain 8 members, ![]() represents a
population of 30 while
represents a
population of 30 while ![]() represents a population of 10.
represents a population of 10. ![]() would choose members of
would choose members of ![]() to add to the output set with probability
0.75. Thus, the output set of 8 members would uniformly represent a
population of 40, with an expected membership of 6 members from
to add to the output set with probability
0.75. Thus, the output set of 8 members would uniformly represent a
population of 40, with an expected membership of 6 members from
![]() and two members from
and two members from ![]() . Note that
. Note that ![]() is able to properly
weigh each subset because as part of collect/distribute, each node
learns the total number of nodes at the subtree rooted at each
of its children.
is able to properly
weigh each subset because as part of collect/distribute, each node
learns the total number of nodes at the subtree rooted at each
of its children.
A new epoch can begin once the root has received a Collect message from all of its children for the previous epoch. The actual length of an epoch is determined by individual application requirements. The right half of Table 1 describes the fields contained in the Distribute message.
A parent constructs distribute sets for each child in the following
manner. Recall that each node stores the collect set received from
each child during the previous collect phase. Thus, for each of ![]() children, a particular node maintains
children, a particular node maintains
![]() . Also recall that
each collect set,
. Also recall that
each collect set, ![]() , consists of nodes selected uniformly randomly from
the subtree rooted at node
, consists of nodes selected uniformly randomly from
the subtree rooted at node ![]() . A parent node
. A parent node ![]() constructs a
distribute set
for each child from this information saved during the preceding
collect phase. This information includes the collect set for each
child, the node
constructs a
distribute set
for each child from this information saved during the preceding
collect phase. This information includes the collect set for each
child, the node ![]() itself, as well as
itself, as well as ![]() ,
, ![]() 's own distribute set.
's own distribute set.
To the application using it, RanSub offers three choices regarding the contents of distribute sets:
 |
 |
Our sample application, an adaptive application-layer multicast overlay, uses Ransub-ordered to ensure that simultaneous transformations to the tree structure do not introduce loops (as discussed in Section 3). Thus, we assume RanSub-ordered for the remainder of this paper.
A limitation of RanSub-ordered is that the first child of a particular
node will always have a smaller set of potential nodes to choose from
than the ![]() th. In fact, the first child's distribute set would
always be restricted to a relatively small subset of global nodes.
For RanSub-ordered, this violates our goal of distributing random
subsets to all nodes that are uniformly chosen across all global
participants in a single epoch. We take the following step to ensure
that every node still receives a uniformly random subset across
multiple invocations of RanSub-ordered. Every configurable
th. In fact, the first child's distribute set would
always be restricted to a relatively small subset of global nodes.
For RanSub-ordered, this violates our goal of distributing random
subsets to all nodes that are uniformly chosen across all global
participants in a single epoch. We take the following step to ensure
that every node still receives a uniformly random subset across
multiple invocations of RanSub-ordered. Every configurable ![]() epochs, the root of the overlay periodically sets the reshuffle flag
in its Distribute message, signaling overlay participants to randomly
reshuffle children lists. This allows children that were at the
beginning of the total ordering (and hence received few nodes in
distribute sets) a chance to move toward the end of the total ordering
and receive information about more nodes.
epochs, the root of the overlay periodically sets the reshuffle flag
in its Distribute message, signaling overlay participants to randomly
reshuffle children lists. This allows children that were at the
beginning of the total ordering (and hence received few nodes in
distribute sets) a chance to move toward the end of the total ordering
and receive information about more nodes.
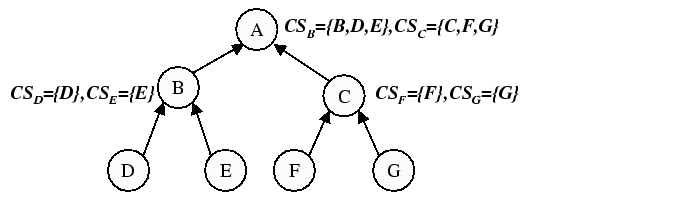
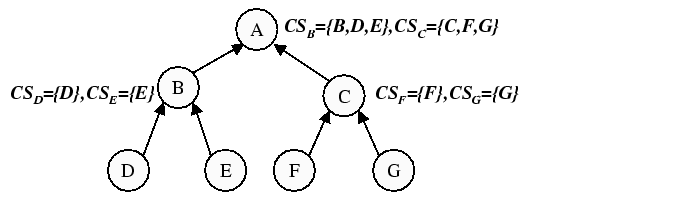 |
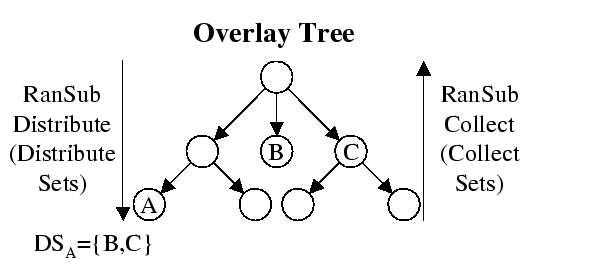
Figure 2 summarizes the operation of the
two phases of the RanSub protocol. For simplicity, we do not include
the results of ![]() , which would appropriately reduce the size of
all subsets
to the application-specified
size constraint. In the collect phase for this example, each node
constructs a collect set (
, which would appropriately reduce the size of
all subsets
to the application-specified
size constraint. In the collect phase for this example, each node
constructs a collect set (![]() ) composed of the union of itself and
all members of the collect sets it received from its children. Thus,
) composed of the union of itself and
all members of the collect sets it received from its children. Thus,
![]() receives a collect set from each of its children,
receives a collect set from each of its children, ![]() and
and ![]() ,
that are uniformly representative of the subtrees rooted at
,
that are uniformly representative of the subtrees rooted at ![]() and
and
![]() respectively. Each node determines
which of its collect sets should be used to compose the distribute set (
respectively. Each node determines
which of its collect sets should be used to compose the distribute set (![]() )
for each of its children.
)
for each of its children.
For the distribute phase, node ![]() constructs
constructs ![]() by taking the union of
itself (
by taking the union of
itself (![]() ) with
) with ![]() . Node
. Node ![]() in turn constructs
in turn constructs ![]() by
taking the union of itself (
by
taking the union of itself (![]() ) with its own distribute set
(
) with its own distribute set
(
![]() ) and
) and
![]() from the previous collect phase.
from the previous collect phase.
![]() gets ``lucky'' in this ordering (it is actually the last node in
this total ordering) and receives a distribute set representative of
the entire topology (once again, recall that we are omitting the
compact operation that would throw out appropriate set elements to
maintain size-constrained sets). Node
gets ``lucky'' in this ordering (it is actually the last node in
this total ordering) and receives a distribute set representative of
the entire topology (once again, recall that we are omitting the
compact operation that would throw out appropriate set elements to
maintain size-constrained sets). Node ![]() would get ``unlucky'' and
only receive a distribute set consisting of itself (it is the first
node in this total ordering). However, once the children lists are
reshuffled, the resulting total ordering would be a random walk of the
tree in which each node is only visited once yielding an entirely
different new total ordering. Finally, note that the complexity of
reshuffling children is only needed if a total ordering is required.
would get ``unlucky'' and
only receive a distribute set consisting of itself (it is the first
node in this total ordering). However, once the children lists are
reshuffled, the resulting total ordering would be a random walk of the
tree in which each node is only visited once yielding an entirely
different new total ordering. Finally, note that the complexity of
reshuffling children is only needed if a total ordering is required.
We believe that RanSub closely approximates the ideal properties outlined at the beginning of this section. Since it uses a tree to propagate sublinear-sized collect and distribute sets between parents and children, it imposes low overhead on the underlying network. Using an efficient overlay structure further ensures that epochs can be short. For instance, we find that for a 1000-node system (in a network with a diameter less than 500 ms), epochs can be as short as five seconds.
In the absence of node failure, RanSub delivers random subsets that are close to uniformly distributed. The key behind achieving uniformity is accounting for nodes that are represented by a random sample at any given time during the protocol execution. We achieve this by running the protocol over a tree, where it is straightforward for a node to have an estimate of the number of its descendants. Future work includes adapting RanSub to function over meshed overlays, not just trees.
RanSub uniformity might suffer as nodes join and leave the system. We do not provide the guarantee that nodes in the random subset will be active when considered by other nodes. RanSub is a mechanism for taking a snapshot of ``live'' tree participants and then taking uniformly random samples of it. This is a strength of our approach since we do not require a separate group membership mechanism. If the node is alive when it receives a Collect message, it may be included in distribute sets given to other nodes. If that node fails soon after the snapshot, it may be unavailable when considered by other nodes. If a node joins after the collect phase of a previous epoch has completed, it will not be present in the snapshot.
In RanSub, the time for node failure detection can be on the order of a small number of seconds. Nodes below a point of failure rejoin the tree at current participants using previously received distribute sets. The node failure detection interval can be further reduced if the underlying tree is used to support application-layer multicast. In this case, absence of data for a few hundreds of milliseconds might signify disconnection from the parent. In essence, application-layer data may serve as a heartbeat mechanism for failure detection.
RanSub assumes trust between overlay participants, and therefore is not resilient to internal attacks. For example, a malicious node might alter the contents of collect and distribute sets. We are investigating several techniques to address this limitation. For instance, one approach involves sending subsets over multiple tree ``cross-links'' to allow identification and confinement of damage caused by malicious users. These ``cross-links'' would also help with the overall reliability of the tree. Multiple paths through the tree means that a single failure may not disconnect nodes in the tree.
As discussed earlier, distributing uniformly random subsets of global participants is applicable to a broad range of important services. This section describes SARO, a Scalable Adaptive Randomized Overlay, one such application of RanSub. The use of RanSub for SARO is circular in this example. SARO uses random subsets to probe peers to locate neighbors that meet performance targets and to adapt to dynamically changing network conditions. At the same time, RanSub uses the SARO overlay for efficient distribution of Collect and Distribute messages.
The goal of SARO is to construct overlays that are: i) scalable, ii) degree-constrained, iii) delay- and bandwidth-constrained, iv) adaptive, and v) self-organizing. For scalability, we enforce the following rules:
We achieve the first two goals using the distribute sets that RanSub
transmits to each node every epoch. Each SARO node ![]() performs
probes to members of this subset to determine if a remote node
performs
probes to members of this subset to determine if a remote node ![]() exists that would deliver better delay or bandwidth to
exists that would deliver better delay or bandwidth to ![]() and its
descendants. If so,
and its
descendants. If so, ![]() attempts to move under
attempts to move under ![]() .
.
To motivate the third requirement, consider a node ![]() that decides to
move underneath a remote node
that decides to
move underneath a remote node ![]() . The system would introduce a loop
if some ancestor of
. The system would introduce a loop
if some ancestor of ![]() simultaneously decides to move under some
descendant of
simultaneously decides to move under some
descendant of ![]() . The naive approach to avoiding loops requires
locking a number of nodes across the wide area to avoid such
simultaneous overlay transformations. While this may be appropriate
for a small number of nodes or for LAN settings, this process will not
scale to large overlays. Thus, we impose a total ordering among nodes
provided by the ordered flavor of RanSub to ensure that no two
simultaneous moves in the same epoch can introduce a SARO loop.
During any epoch, each node's distribute set contains only remote
nodes that come before it in the current total order.
. The naive approach to avoiding loops requires
locking a number of nodes across the wide area to avoid such
simultaneous overlay transformations. While this may be appropriate
for a small number of nodes or for LAN settings, this process will not
scale to large overlays. Thus, we impose a total ordering among nodes
provided by the ordered flavor of RanSub to ensure that no two
simultaneous moves in the same epoch can introduce a SARO loop.
During any epoch, each node's distribute set contains only remote
nodes that come before it in the current total order.
Recall that RanSub periodically changes the total ordering of nodes and
random membership in delivered
distribute sets. Thus, while each node only
tracks and probes ![]() remote nodes during
any one epoch, RanSub ensures that
the makeup of the distribute set changes probabilistically
such that, over time, each node quickly probes all potential parents.
The size of the random subset effects a tradeoff between
scalability (measured by per-node state and network probing
overhead) and convergence time (the amount of time it takes to build
an overlay that achieves delay and bandwidth targets even under
changing network conditions).
remote nodes during
any one epoch, RanSub ensures that
the makeup of the distribute set changes probabilistically
such that, over time, each node quickly probes all potential parents.
The size of the random subset effects a tradeoff between
scalability (measured by per-node state and network probing
overhead) and convergence time (the amount of time it takes to build
an overlay that achieves delay and bandwidth targets even under
changing network conditions).
| ||||||||||||
SARO requires additional information beyond that distributed by RanSub (see Table 1). In general, applications may wish to piggyback different state information with the existing Collect and Distribute messages. Our RanSub layer is designed in a manner to make such extensibility straightforward, though a detailed description is beyond the scope of this paper. Table 2 describes the additional information transmitted by SARO in Collect and Distribute messages.
Recall that the length of an epoch (random subsets are distributed once per epoch) is determined by application-specific requirements. Shorter epochs provide more information, while longer epochs incur less overhead. For SARO, our goal is to quickly converge to an overlay that matches the underlying topology and adapts to dynamically changing network characteristics. The implementation and evaluation in this paper is pessimistic in that we run with a constant epoch length of 10 seconds in all cases. In the future, we plan to investigate setting the epoch length adaptively based on both overlay characteristics and network conditions. For example, if SARO has already matched the underlying topology and if network characteristics are not changing rapidly (likely the common case in the Internet), then the system can afford a longer epoch length. Thus, we envision reducing overall system overhead by running SARO with a short epoch length during initial self-organization and in response to large changes in network conditions, but running with a long epoch in the common case.
A key to SARO's ability to converge to bandwidth and delay (maximum delay from root to all other overlay participants) targets lies in localized tree transformations. During each epoch, nodes measure the delay and bandwidth between themselves and all members of their distribute set. These probes consist of a small number of packets inter-spaced by the target application bandwidth2. If the loss rate of the probes is below a specified threshold, the probing node calculates the average round trip time. The goal is to locate a new parent that will deliver better delay, better bandwidth, or both to itself and all of its descendants. If a better parent is located, the child attempts to move under it. The migrating node issues the add request to the potential parent and waits for the response. If the request is accepted, it notifies its old parent, communicates its new delay from root to all its children, and notifies the new parent of its furthest descendant (updating the parent's state for the next epoch).
In general, the goal of SARO is to achieve the lowest delay configuration that still maintains the target bandwidth to the root. Thus, during each epoch, nodes use information from their probes to perform two types of transformations: BANDWIDTH_ONLY and DELAY_AND_BANDWIDTH. Nodes that have not yet reached their bandwidth target may perform BANDWIDTH_ONLY transformation to improve their bandwidth to root, even if it means increasing their delay. DELAY_AND_BANDWIDTH transformations allow nodes to rotate under a new parent that improves the nodes' delay to root while maintaining (or improving) bandwidth.
To this point, our discussion assumes a static set of nodes dynamically self-configuring to match changing network conditions. In general however, the set of overlay participants will also be changing. A node performing a SARO join simply needs to contact any existing member of the overlay. The initial bootstrapping parent may be sub-optimal from the perspective of bandwidth or delay. However, the node will begin receiving random subsets as part of the collect/distribute process, and it can use the associated random subsets to probe for superior parents using the process described above.
Since the bootstrapping parent node might fail, we make an additional assumption that every node is aware of the root of the tree. Therefore, an incoming node will always have at least one bootstrapping parent (similar to Overcast [16], we can replicate the root to improve root availability). For the sake of scalability, we allow nodes to contact the root only if it is absolutely necessary (i.e., its original bootstrapping parent failed).
If a bootstrapping parent does not have enough slots in its children list to accept a joining node, it redirects the incoming node randomly to either its parent or one of its children. Similarly, if the incoming node would violate the delay bound, the bootstrapping parent redirects it to its parent. If the node is redirected too many times, it joins the tree at the first available point, and tries to improve its position later.
Handling node failure is simplified by our periodic distribution of
Collect and Distribute messages, which implicitly act as heartbeat
messages. Each parent waits for Collect messages from all of its
children. If a message is not received within some multiple of the
subtree height3, the parent assumes that one of its
children has failed and excludes it from participating in the next
epoch by not sending a Distribute message to that child. However, the
node does proceed with a Collect message to its own parent when it
detects the failure to ensure that a failure low in the tree does not
cascade all the way back up the tree. A node, ![]() , can similarly
detect the failure of its parent when it does not receive a Distribute
message within a multiple of the delay target. In this case,
, can similarly
detect the failure of its parent when it does not receive a Distribute
message within a multiple of the delay target. In this case, ![]() will
send a dummy Distribute message (with an empty distribute set) to all
of its children. This empty Distribute message signals
will
send a dummy Distribute message (with an empty distribute set) to all
of its children. This empty Distribute message signals ![]() 's
descendants that no probing or overlay transformations should be
performed during this epoch.
's
descendants that no probing or overlay transformations should be
performed during this epoch. ![]() then attempts to locate a new parent
using information from previous distribute sets where appropriate.
Thus, upon a failure, the entire subtree rooted at
then attempts to locate a new parent
using information from previous distribute sets where appropriate.
Thus, upon a failure, the entire subtree rooted at ![]() is able to
rejoin the overlay with a single transformation, rather than forcing
all nodes below
is able to
rejoin the overlay with a single transformation, rather than forcing
all nodes below ![]() to rejoin separately.
to rejoin separately.
Under certain circumstances, the greedy nature of SARO
can lead to sub-optimal overlays. Consider the following situation.
A node ![]() with a particular degree bound has a full complement of
children. However, a node
with a particular degree bound has a full complement of
children. However, a node ![]() somewhere else in the overlay can only
achieve its bandwidth target by becoming a child of
somewhere else in the overlay can only
achieve its bandwidth target by becoming a child of ![]() . Finally, one
of
. Finally, one
of ![]() 's children,
's children, ![]() , is best served by
, is best served by ![]() but would still be able
to achieve its bandwidth target as a child of some fourth node
but would still be able
to achieve its bandwidth target as a child of some fourth node ![]() .
As described thus far, SARO will become stuck in a ``local minimum''
in this situation.
.
As described thus far, SARO will become stuck in a ``local minimum''
in this situation.
We address this situation by introducing wean operations. At a high level, the goal is to ensure that each parent leaves a number of slots open whenever possible to address the above condition. Thus, as a node approaches its degree limit, it will send a wean message to one of its children. In subsequent epochs, that child will move to a new parent if it can find a suitable location that still meets its bandwidth requirement (though its delay may be increased). A wean may or may not succeed (an appropriate alternate parent may not exist) and the wean operation expires after a configurable number of epochs.
One difficulty is choosing the child to wean. Ideally, a parent would wean the child that would lose the least in delay and bandwidth while still achieving its targets. We approximate this in the following manner. During each epoch, all nodes maintain information on the best alternate parent with respect to both delay and bandwidth. This information is propagated to parents in the collect phase (see Table 2) and is used by parents to determine the wean target.
For our ModelNet experiments, SARO runs on 35 1.4Ghz Pentium-III's running Linux 2.4.18 and interconnected with both 100 Mbps and 1 Gbps Ethernet switches. We multiplex 28-29 instances of SARO on each of the Linux nodes, for a total of one thousand nodes self-organizing to form overlays. We validated our ModelNet results with ns experiments using identical topologies and communication patterns. In ModelNet, all packet transmissions are routed through a core responsible for emulating the hop-by-hop delay, bandwidth, and congestion of a target network topology. For our experiments, we use a single 1Ghz Pentium III running FreeBSD-4.5 as the core. The core has a 1 Gbps connection to the rest of the cluster. The core was never a bottleneck either in CPU or bandwidth for any of our experiments. Our earlier work [28] shows that, for a given wide-area topology, ModelNet is accurate to within 1 ms of the target end-to-end packet transmission time up to and including 100% CPU utilization, and 120,000 packets/sec (1 Gbps assuming packets are 1000 bytes on average). ModelNet can scale its capacity with additional core nodes, though this was not necessary for our experiments here. ModelNet emulates packet transmission hop-by-hop (including per-hop queue sizes and queuing disciplines) through a target network. Thus, a packet's end-to-end delay accounts for congestion and for per-hop queuing, propagation, and transmission delay.
By default, the core emulates the characteristics of a random 20,000-node INET-generated topology [6]. We randomly assign 1,000 nodes to act as clients connected to one-degree stub nodes in the topology. One of these participants is randomly selected to act as the root of the SARO tree. We classify network links as being Client-Stub, Stub-Stub (both with bandwidth between 1-10 Mbps), Transit-Stub (bandwidth between 10-100 Mbps) and Transit-Transit (100-155 Mbps). We calculate propagation delays among nodes from the relative placement of the nodes in the plane by INET. The baseline diameter of the network is approximately 200 ms. While the presented results are restricted to a single topology, the results of additional experiments and simulations all show qualitatively similar behavior.
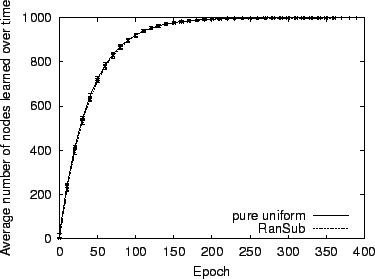 |
To verify that RanSub distributes uniformly random subsets to all nodes, we used our complete RanSub prototype to create a SARO overlay of 1000 emulated nodes as described above. After convergence, we let our experiment run for a total of 360 epochs and tracked the cumulative number of unique remote peers that RanSub distributes to each node over time. We configured RanSub to distribute 25 random participants each epoch. Figure 3 plots the average number of peers each node is exposed to on the y-axis as a function of time progressing in epochs on the x-axis. The vertical bars represent the standard deviation. We also show the best case in which we simulate pure uniform random subsets (using the same random number generator as the one used by our RanSub implementation). RanSub delivers random subsets with essentially optimal uniformity.
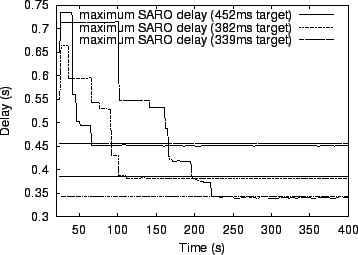
Figure 4 shows the convergence time of three SARO overlays running with a maximum degree of 10 and random subsets of size 15. The 1000 nodes join the overlay sequentially at a random point in the network over the first 20 seconds of the experiment (50 nodes/second) and then use random subsets to probe for parents that will deliver the appropriate delay target (bandwidth targets of 64Kbps were easily achieved for this experiment). In effect, at the beginning of the experiment we pessimistically create an overlay with random interconnectivity. We observe the behavior of the system for three different delay targets, 339 ms, 382 ms, and 452 ms. The 339 ms delay target is quite difficult to achieve for our topology and degree bound. The figure plots the achieved worst-case delay relative to the delay target as a function of time progressing on the x axis. SARO uses random subsets to converge to the specified delay target in all cases, with convergence time varying from 60 seconds to 220 seconds in the three cases depending on the tightness of the delay target. We note that our convergence times using random subsets are comparable to a number of smaller-scale overlay construction techniques that maintain global state information and that perform global probing.
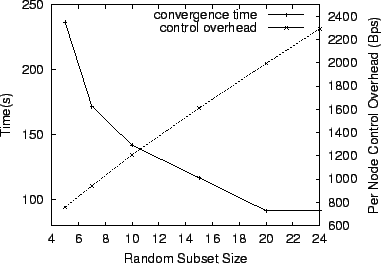 |
We now quantify the effects of the size of the random subsets on SARO convergence time. In general, less information in the random subset increases convergence time as nodes have to spend more time to find an appropriate parent. More information will likely decrease the convergence time, but at the cost of increased network probing overhead. With a maximum per-node degree of 10, we measure the time for the 1,000 node SARO tree to converge to a 382 ms delay target as a function of the size of the random subsets. As shown in Figure 5, we increase the size of the random subset from 5 to 24 on the x-axis and plot the resulting convergence time on the left-hand y-axis. The convergence time decreases from approximately 240 seconds to 90 seconds. Figure 5 also plots the associated tradeoff with per-node control overhead, accounting for both RanSub Collect/Distribute messages and probing overhead. As expected, probing overhead on the right-hand y-axis grows linearly with the size of the random subset, but only to a manageable 2300 bytes/sec even when the random subset size grows to 24, most of which is probing overhead. Note that the benefits of increasing the random subset size beyond 20 diminishes rapidly. Of course, this point of diminishing returns will vary with the topology and delay target. We have experimented with dynamically increasing or decreasing the random subset size by taking real-time measurements of the overlay's convergence, but we leave this to future work.
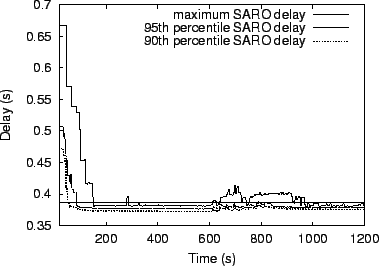
One of the most important aspects of SARO is its ability to dynamically react to changing network conditions. To evaluate this ability, we subject a steady-state 1000-node SARO tree to widespread and sustained change in network characteristics. Every 25 seconds, we increase the propagation delay of a randomly chosen 14% of all network links by between 0-25% of the link's original delay. The idea behind this experiment is to determine what happens to the overlay as the network continuously degrades under conditions much worse than those typically found on the Internet. Figure 6 shows the results of this experiment, plotting delay as a function of time for the 90th percentile, 95th percentile, and worst case node in the overlay as a function of time progressing the x-axis. Note that the 90th percentile indicates that 90% of SARO nodes have delay better than the indicated value. We set the delay target to 382 ms for this experiment, the degree bound to 10 and the size of the random subset to 15.
We intentionally set our target delay to a value that is relatively
difficult to achieve for our degree bound in the face of highly
variable network conditions. Thus, the overlay initially takes
approximately 150 seconds to converge to the delay target. We perturb
network conditions in the manner described above beginning at time
![]() and continuing for 200 seconds. While 95% of nodes are able
to maintain their delay target during most of the
network perturbation, it takes
SARO another 180 seconds after the network perturbation subsides (though
link delays remain at their elevated levels) to once again bring all
nodes within delay bounds. We include the results of this experiment
to quantify the level of adaptivity that SARO can deliver. Additional
experiments indicate that if network conditions were perturbed for a
longer period of time
(with same number of links, magnitude of change, and frequency of
change), SARO would be unable to once again achieve the delay
target. With less perturbation or a more relaxed delay target, SARO
typically quickly recovers from changes to network conditions.
and continuing for 200 seconds. While 95% of nodes are able
to maintain their delay target during most of the
network perturbation, it takes
SARO another 180 seconds after the network perturbation subsides (though
link delays remain at their elevated levels) to once again bring all
nodes within delay bounds. We include the results of this experiment
to quantify the level of adaptivity that SARO can deliver. Additional
experiments indicate that if network conditions were perturbed for a
longer period of time
(with same number of links, magnitude of change, and frequency of
change), SARO would be unable to once again achieve the delay
target. With less perturbation or a more relaxed delay target, SARO
typically quickly recovers from changes to network conditions.
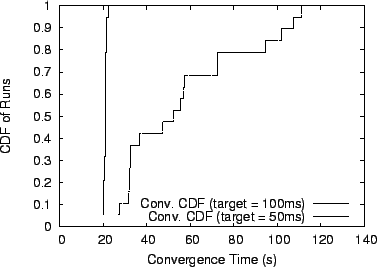 |
To further evaluate the utility of our approach, we evaluated the behavior of SARO running on a subset of 19 PlanetLab nodes [20] during September 2002. We ran SARO over PlanetLab 19 times with each separate run using a different PlanetLab node as the root of the overlay. We then measure the convergence time for each of two different delay targets: 50ms and 100ms. We set the maximum per-node degree to 5 and the random subset size to 5. Figure 7 plots the result of this experiment. We find that for a relatively relaxed delay target of 100ms, all nodes converge within 20 seconds. Tightening the delay bound to 50 ms increases the typical convergence time to approximately a minute with worst case convergence taking up to two minutes. Note that all reported values are once again for the worst-case convergence time of the last node to meet its delay target.
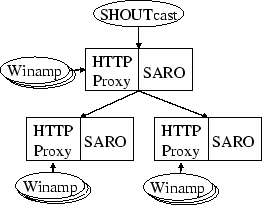
Next, we streamed live audio over SARO by integrating an HTTP proxy as a separate thread in the SARO address space, as depicted in Figure 8. We use a publicly available SHOUTCast server [25], to stream MP3 encoded over HTTP. We then instantiate a SARO/HTTP process on the same node as the SHOUTCast server to act as the root of the overlay tree. Each SARO node below the root instructs its associated HTTP proxy to establish a connection to its parent to receive streaming data. The node is then able to stream content to local Winamp players and to its own children in the overlay. Each time a SARO node locates a better parent, it also instructs is HTTP proxy to reestablish a connection to this new parent.
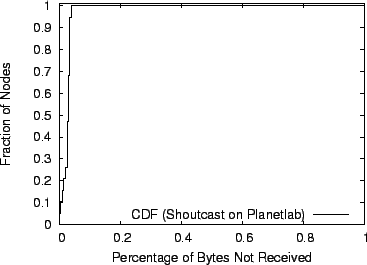 |
We use this configuration to successfully stream MP3 files at 256Kbps from an existing SHOUTcast servers over 1000 nodes in our emulation environment and the PlanetLab testbed. Figure 9 shows the results of a 5-minute experiment of SHOUTcast streaming over 19 SARO nodes spread across the PlanetLab testbed. We set the delay target to 75ms, the size of the random subsets to 5 and the maximum per-node degree to 5. The figure plots a CDF of the percent of bytes received by each of the 19 nodes. Byte loss rates vary from 0-5%. However, we note that we measure the loss rate while SARO was still self-organizing at the beginning of the experiment. The vast majority of the losses came at this time. We verified the correctness of our experiment by connecting to individual HTTP/SARO nodes using the Winamp media player to playback the stream.
RanSub shares some design goals with gossip-based dissemination protocols such as SCAMP [1] and LBPCAST [11]. However, because it operates over a tree, RanSub offers uniformly random subsets relative to these earlier efforts. RanSub does not require a minimum random subset size for correct operation. Finally, in combination with SARO, RanSub allows more predictable time between updates (one epoch).
Our work on SARO builds upon a number of recent efforts into
``application-layer'' multicast, where nodes spread across the
Internet cooperate to deliver content to end hosts. Edges in this
overlay are TCP connections, ensuring congestion control and
reliability in a hop-by-hop manner. Perhaps most closely related to
our effort in this space is Narada [14,15], which builds a
mesh interconnecting all participating nodes and then runs a standard
routing protocol on top of the overlay mesh. Relative to our work, Narada nodes maintain global knowledge about all
group participants. In comparison, we use the RanSub layer to
maintain information about a probabilistic ![]() subset of global
participants, making applications built on top of RanSub, including
SARO, more scalable.
subset of global
participants, making applications built on top of RanSub, including
SARO, more scalable.
SARO bears some similarity to the Banana Tree Protocol
(BTP) [13], and Host Multicast Tree Protocol
(HMTP) [29]. However, neither of these approaches attempt to
provide delay or bandwidth guarantees and neither considers a
two-metric network design. All three protocols use the idea of tree
transformations based on local knowledge (obtained through limited
network probing) to improve overall tree quality. However, BTP
implements a more restrictive policy for choosing a potential parent,
called ``switch-one-hop'', which considers only
grandparents and immediate siblings. HMTP can introduce loops and
thus requires loop detection that requires knowledge of all of one's
ancestors. Since HMTP offers no bounds on tree height, message size
and required state are also unbounded (![]() ), rendering this
approach potentially unscalable. Finally, HMTP is not evaluated under
changing network conditions.
), rendering this
approach potentially unscalable. Finally, HMTP is not evaluated under
changing network conditions.
Yoid [12] shares the design philosophy that a tree can be built directly among participating nodes without the need to first build an underlying mesh. Yoid does not describe any scalable mechanism for conforming to the topology of the underlying network, has not been subjected to a detailed performance evaluation, and contains loop detection code as opposed to our approach of avoiding loops.
ALMI [19] uses all-pairs probing at a cost of ![]() and transmits this changing connectivity information to a centralized
node that calculates an appropriate topology for the overlay.
RMX [7] faces similar scalability limitations. In
Overcast [16], all nodes join at the root and migrate
down to the point in the tree where they are still able to maintain
some minimum level of bandwidth. Relative to our effort, Overcast
does not focus on providing delay guarantees (given its focus on
bandwidth-intensive applications). Its convergence time is also
limited by probes to immediate siblings and ancestors.
NICE [3] uses hierarchical clustering to build overlays
that match the underlying network topology. Relative to our approach,
NICE focuses on low-bandwidth (i.e., single-metric, delay-optimized)
applications and requires loop detection code. We believe that a
variety of existing overlay construction techniques, including Yoid,
ALMI, RMX, Overcast, and NICE could benefit from the availability of
our RanSub layer.
and transmits this changing connectivity information to a centralized
node that calculates an appropriate topology for the overlay.
RMX [7] faces similar scalability limitations. In
Overcast [16], all nodes join at the root and migrate
down to the point in the tree where they are still able to maintain
some minimum level of bandwidth. Relative to our effort, Overcast
does not focus on providing delay guarantees (given its focus on
bandwidth-intensive applications). Its convergence time is also
limited by probes to immediate siblings and ancestors.
NICE [3] uses hierarchical clustering to build overlays
that match the underlying network topology. Relative to our approach,
NICE focuses on low-bandwidth (i.e., single-metric, delay-optimized)
applications and requires loop detection code. We believe that a
variety of existing overlay construction techniques, including Yoid,
ALMI, RMX, Overcast, and NICE could benefit from the availability of
our RanSub layer.
Finally, a number of recent efforts [21,23,31] propose building application-layer multicast on top of scalable peer-to-peer lookup infrastructures [8,22,24,30]. While these projects demonstrate that it is possible to probabilistically achieve good delay relative to native IP multicast, they are unable to provide any performance bounds because of the probabilistic nature of the underlying peer-to-peer system. Further, these systems do not focus on two-metric network optimization (e.g., delay and bandwidth). Finally, to the best of our knowledge, these approaches, have largely been evaluated through simulation and have not been subjected to live Internet conditions.
We thank our shepherd, Steve Gribble, for helping us refine the paper and David Becker for his help with ModelNet. We also thank Rebecca Braynard and anonymous reviewers for their helpful comments.
|
This paper was originally published in the
Proceedings of the
4th USENIX Symposium on Internet Technologies and Systems,
March 26-28, 2003,
Seattle, WA, USA
Last changed: 18 March 2003 aw |
|