Bridging the Gap between Software and Hardware Techniques
|
Abstract:
The paravirtualized I/O driver domain model, used in Xen, provides several advantages including device driver isolation in a safe execution environment, support for guest VM transparent services including live migration, and hardware independence for guests. However, these advantages currently come at the cost of high CPU overhead which can lead to low throughput for high bandwidth links such as 10 gigabit Ethernet. Direct I/O has been proposed as the solution to this performance problem but at the cost of removing the benefits of the driver domain model. In this paper we show how to significantly narrow the performance gap by improving the performance of the driver domain model. In particular, we reduce execution costs for conventional NICs by 56% on the receive path, and we achieve close to direct I/O performance for network devices supporting multiple hardware receive queues. These results make the Xen driver domain model an attractive solution for I/O virtualization for a wider range of scenarios.
Table 1: Classes grouping Linux functions
Class Description driver network device driver and netfront network general network functions bridge network bridge netfilter network filter netback netback mem memory management interrupt interrupt, softirq, & Xen events schedule process scheduling & idle loop syscall system call time time functions dma dma interface hypercall call into Xen grant issuing & revoking grant
Table 2: Classes grouping Xen Function
Class Description grant grant map unmap or copy operation schedule domain scheduling hypercall hypercall handling time time functions event Xen events mem memory interrupt interrupt entry enter/exit Xen (hypercall, interrupt, fault), traps fault handling (also system call intercept)
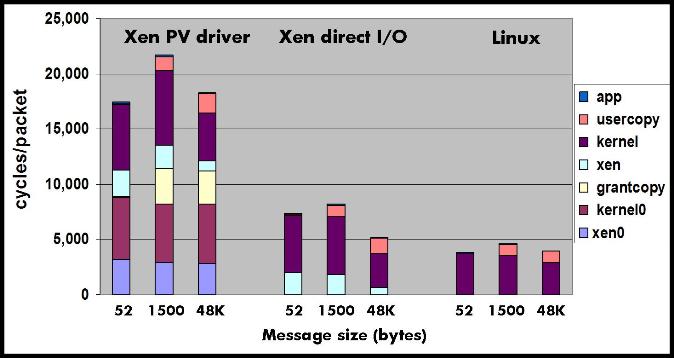
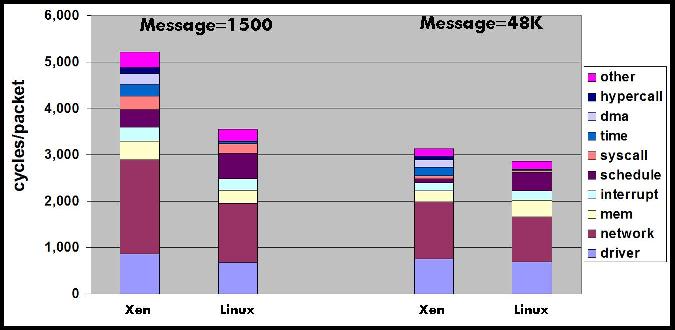
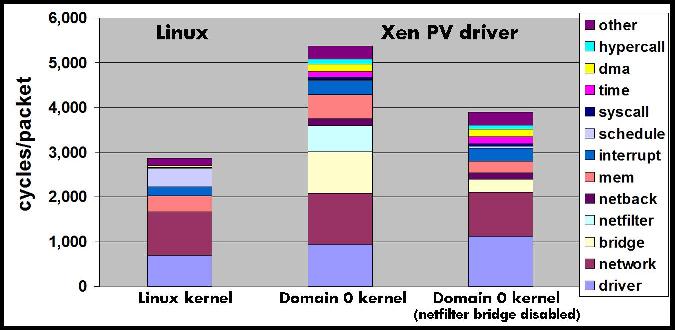
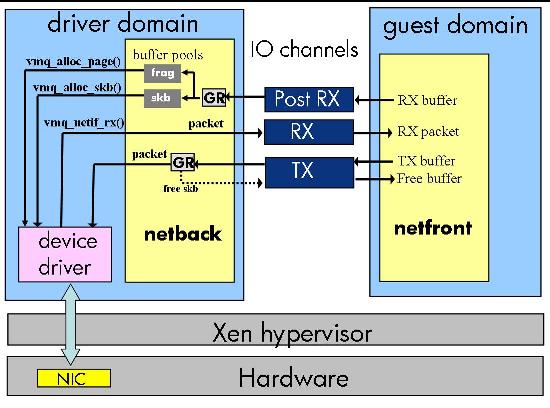
This section presents a detailed performance analysis of Xen network I/O virtualization. Our analysis focuses on the receive path, which has higher virtualization overhead than the transmit path and has received less attention in the literature. We quantify the cost of processing network packets in Xen and the distribution of cost among the various components of the system software. Our analysis compares the Xen driver domain model, the Xen direct I/O model, and native Linux. The analysis provides insight into the main sources of I/O virtualization overhead and guides the design changes and optimizations we present in Section 4.
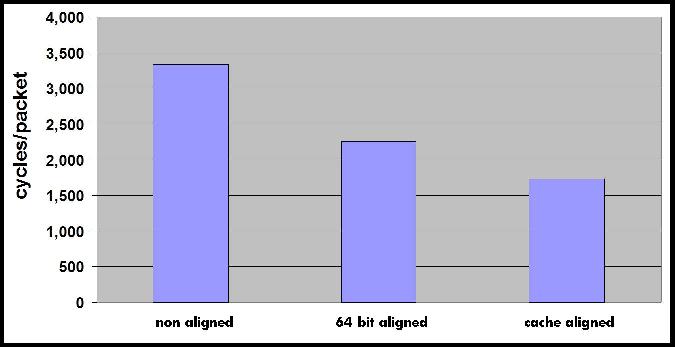
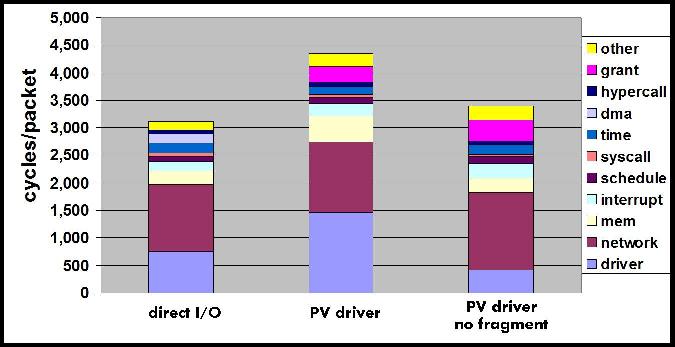
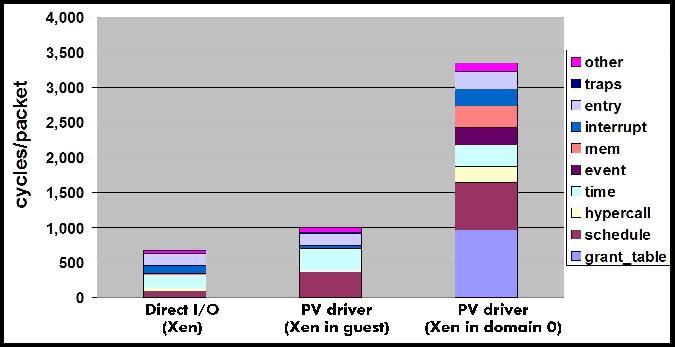
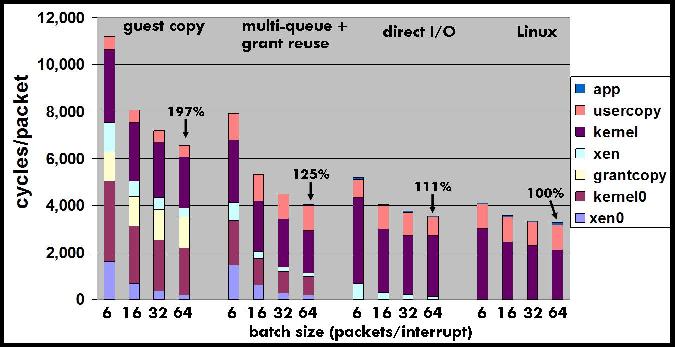
We start by looking at the overheads when running guests with direct I/O access. It is surprising that for small message sizes Xen with direct I/O uses twice the number of CPU cycles to process received packets compared to non-virtualized Linux. This is a consequence of memory protection limitations of the 64-bit x86 architecture that are not present in the 32-bit X86 architecture. The 64-bit x86 architecture does not support memory segmentation, which is used for protecting Xen memory in the 32-bit architecture. To overcome this limitation Xen uses different page tables for kernel and user level memory and needs to intercept every system call to switch between the two page tables. In our results, the overhead of intercepting system calls is negligible when using large message sizes (48000 bytes), since each system call consumes data from many received packets (32 packets with 1500 bytes). For more details on system call overheads the reader is referred to an extended version of this paper[26]. System call interception is an artifact of current hardware limitations which will be eliminated over time as CPU hardware support for virtualization [20][5] improves. Therefore, we ignore its effect in the rest of this paper and discuss only results for large message sizes (48000 bytes).
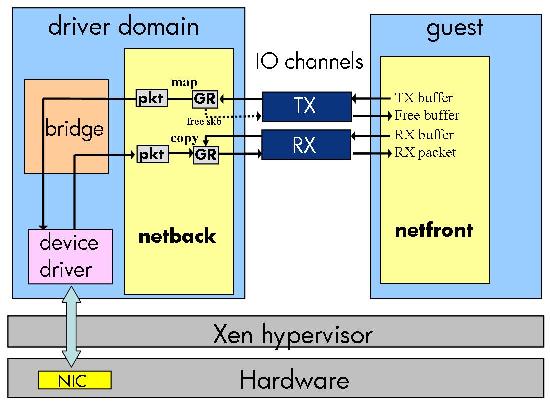
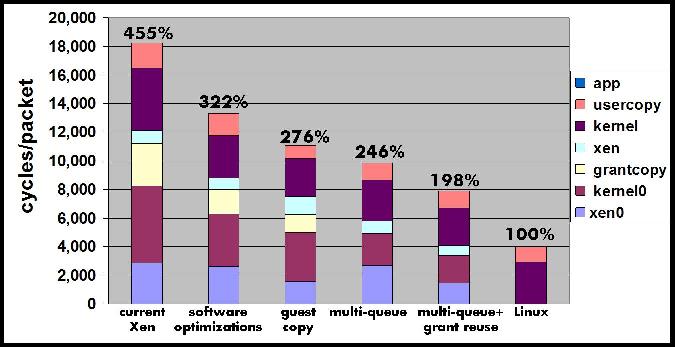
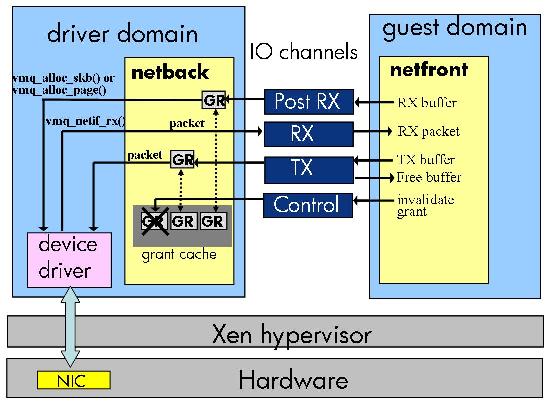
Figure 9 illustrates how the Xen PV network driver model can be modified to support multi-queue devices. Netfront posts grants to I/O buffers for use by the multi-queue device drivers using the I/O channel. For multi-queue devices the driver domain must validate if the page belongs to the (untrusted) guest and needs to pin the page for the I/O duration to prevent the page being reassigned to the hypervisor or other guests. The grant map and unmap operations accomplish these tasks in addition to mapping the page in the driver domain. Mapping the page is needed for guest to guest traffic which traverses the driver domain network stack (bridge). Experimental results not presented here due to space limitations show that the additional cost of mapping the page is small compared to the overall cost of the grant operation.
The number of grant operations performed in the driver domain can be reduced if we relax the memory isolation property slightly and allow the driver domain to keep guest I/O buffers mapped in its address space even after the I/O is completed. If the guest recycles I/O memory and reuses previously used I/O pages for new I/O operations, the cost of mapping the guest pages using the grant mechanism is amortized over multiple I/O operations. Fortunately, most operating systems tend to recycle I/O buffers. For example, the Linux slab allocator used to allocate socket buffers keeps previously used buffers in a cache which is then used to allocate new I/O buffers. In practice, keeping I/O buffer mappings for longer times does not compromise the fault isolation properties of driver domains, as the driver domain still can only access the same set of I/O pages and no pages containing any other guest data or code.
This document was translated from LATEX by HEVEA.