
Before considering the potential benefits of migration, we must first determine the typical lifetime of individual slivers. If most slivers are short-lived, then a complex migration infrastructure is unnecessary since per-node resource availability and per-sliver resource demand are unlikely to change significantly over very short time scales. In that case making sliver-to-node mapping decisions only when slivers are instantiated, i.e., when the application is initially deployed and when an existing sliver dies and must be re-started, should suffice. Figure 11 shows the average sliver lifetime for each slice in our trace. We see that slivers are generally long-lived: 75% of slices have average sliver lifetimes of at least 6 hours, 50% of slices have average sliver lifetimes of at least two days, and 25% of slices have average sliver lifetimes of at least one week. As before, we say that a sliver is ``alive'' on a node if it appears in the process table for that node.
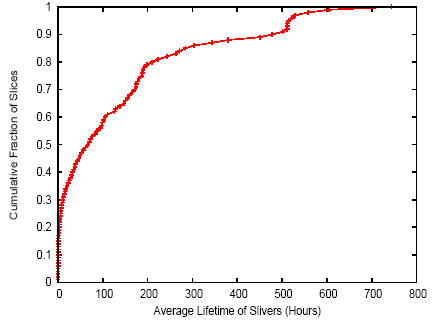
Figure 11: CDF of fraction of slices vs. average sliver lifetime for that slice. A sliver may die due to software failure or node crash; when the sliver comes back up, we count it as a new sliver.
To investigate the potential usefulness of migration, we next examine the rate of change of available node resources. If per-node resource availability varies rapidly relative to our measurements of sliver lifetimes, we can hypothesize that sliver migration may be beneficial.