
Figure 1 shows the number of PlanetLab nodes used by each slice active during our measurement period. We say a slice is ``using'' a node if the slice has at least one task in the node's process table (i.e., the slice has processes on that node, but they may be running or sleeping at the time the measurement is taken). More than half of PlanetLab slices run on at least 50 nodes, with the top 20% operating on 250 or more nodes. This is not to say, of course, that all of those applications ``need'' that many nodes to function; for example, if a platform like PlanetLab charged users per node they use, we expect that this distribution would shift towards somewhat lower numbers of nodes per slice. However, we expect that a desire to maximize realism in experimental evaluation, to stress-test application scalability, to share load among nodes for improved performance, and/or to maximize location diversity, will motivate wide-scale distribution even if such distribution comes at an economic cost. Therefore, based on the data we collected, we conclude that PlanetLab applications must time-share nodes, because it is unlikely that a platform like PlanetLab would ever grow to a size that could accommodate even a few applications each ``owning'' hundreds of nodes on an ongoing basis, not to mention allowing those large-scale applications to coexist with multiple smaller-scale experiments. And it is this best-effort time-sharing of node resources that leads to variable per-node resource availability over time on PlanetLab.
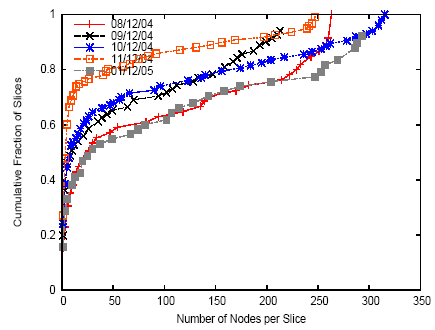
Figure 1: Cumulative distribution of nodes per slice averaged over the first day of each month.
At the same time, more than 70% of slices run on less than half of the nodes, suggesting significant flexibility in mapping slices to nodes. Of course, even applications that wish to run on all platform nodes may benefit from intelligent resource selection, by mapping their most resource-intensive slivers to the least utilized nodes and vice-versa.
Having argued for the necessity of time-sharing nodes, the remainder of this section quantifies resource variability across nodes and investigates the potential for real applications to exploit that heterogeneity by making informed node selection decisions at deployment time. We observe significant variability of available resources across nodes, and we find that in simulation, a simple load-sensitive sliver placement algorithm outperforms a random placement algorithm. These observations suggest that some applications are likely to benefit from informed placement at deployment time.