
Virtual machine monitors (VMMs) are a popular platform for Internet hosting centers and cloud-based compute services. By multiplexing hardware resources among virtual machines (VMs) running commodity operating systems, VMMs decrease both the capital outlay and management overhead of hosting centers. Appropriate placement and migration policies can take advantage of statistical multiplexing to effectively utilize available processors. However, main memory is not amenable to such multiplexing and is often the primary bottleneck in achieving higher degrees of consolidation.
Previous efforts have shown that content-based page sharing provides modest decreases in the memory footprint of VMs running similar operating systems and applications. Our studies show that significant additional gains can be had by leveraging both sub-page level sharing (through page patching) and in-core memory compression. We build Difference Engine, an extension to the Xen virtual machine monitor, to support each of these--in addition to standard copy-on-write full page sharing--and demonstrate substantial savings not only between VMs running similar applications and operating systems (up to 90%), but even across VMs running disparate workloads (up to 65%). In head-to-head memory-savings comparisons, Difference Engine outperforms VMware ESX server by a factor of 1.5 for homogeneous workloads and by a factor of 1.6-2.5 for heterogeneous workloads. In all cases, the performance overhead of Difference Engine is less than 7%.
Virtualization technology has improved dramatically over the past decade to become pervasive within the service-delivery industry. Virtual machines are particularly attractive for server consolidation. Their strong resource and fault isolation guarantees allow multiplexing of hardware among individual services, each with (potentially) distinct software configurations. Anecdotally, individual server machines often run at 5-10% CPU utilization. Operators' reasons are manifold: because of the need to over-provision for peak levels of demand, because fault isolation mandates that individual services run on individual machines, and because many services often run best on a particular operating system configuration. The promise of virtual machine technology for server consolidation is to run multiple services on a single physical machine while still allowing independent configuration and failure isolation.
While physical CPUs are frequently amenable to multiplexing, main memory is not. Many services run comfortably on a machine with 1 GB of RAM; multiplexing ten VMs on that same host, however, would allocate each just 100 MB of RAM. Increasing a machine's physical memory is often both difficult and expensive. Incremental upgrades in memory capacity are subject to both the availability of extra slots on the motherboard and the ability to support higher-capacity modules: such upgrades often involve replacing--as opposed to just adding--memory chips. Moreover, not only is high-density memory expensive, it also consumes significant power. Furthermore, as many-core processors become the norm, the bottleneck for VM multiplexing will increasingly be the memory, not the CPU. Finally, both applications and operating systems are becoming more and more resource intensive over time. As a result, commodity operating systems require significant physical memory to avoid frequent paging.
Not surprisingly, researchers and commercial VM software vendors have developed techniques to decrease the memory requirements for virtual machines. Notably, the VMware ESX server implements content-based page sharing, which has been shown to reduce the memory footprint of multiple, homogeneous virtual machines by 10-40% [24]. We find that these values depend greatly on the operating system and configuration of the guest VMs. We are not aware of any previously published sharing figures for mixed-OS ESX deployments. Our evaluation indicates, however, that the benefits of ESX-style page sharing decrease as the heterogeneity of the guest VMs increases, due in large part to the fact that page sharing requires the candidate pages to be identical.
The premise of this work is that there are significant additional benefits from sharing at a sub-page granularity, i.e., there are many pages that are nearly identical. We show that it is possible to efficiently find such similar pages and to coalesce them into a much smaller memory footprint. Among the set of similar pages, we are able to store most as patches relative to a single baseline page.
Finally, we also compress those pages that are unlikely to be accessed in the near future. Traditional stream-based compression algorithms typically do not have sufficient ``look-ahead'' to find commonality across a large number of pages or across large chunks of content, but they can exploit commonality within a local region, such as a single memory page. We show that an efficient implementation of compression nicely complements page sharing and patching.
In this paper, we present Difference Engine, an extension to the Xen VMM [6] that not only shares identical pages, but also supports sub-page sharing and in-memory compression of infrequently accessed pages. Our results show that Difference Engine can reduce the memory footprint of homogeneous workloads by up to 90%, a significant improvement over previously published systems [24]. For a heterogeneous setup (different operating systems hosting different applications), we can reduce memory usage by nearly 65%. In head-to-head comparisons against VMware's ESX server running the same workloads, Difference Engine delivers a factor of 1.5 more memory savings for a homogeneous workload and a factor of 1.6-2.5 more memory savings for heterogeneous workloads.
Critically, we demonstrate that these benefits can be obtained without negatively impacting application performance: in our experiments across a variety of workloads, Difference Engine imposes less than 7% overhead. We further show that Difference Engine can leverage improved memory efficiency to increase aggregate system performance by utilizing the free memory to create additional virtual machines in support of a target workload. For instance, one can improve the aggregate throughput available from multiplexing virtual machines running Web services onto a single physical machine.
Difference Engine builds upon substantial previous work in page sharing, delta encoding and memory compression. In each instance, we attempt to leverage existing approaches where appropriate.
Two common approaches in the literature for finding redundant pages are content-based page sharing, exemplified by VMWare's ESX server [24], and explicitly tracking page changes to build knowledge of identical pages, exemplified by ``transparent page sharing'' in Disco [9]. Transparent page sharing can be more efficient, but requires several modifications to the guest OS, in contrast to ESX server and Difference Engine which require no modifications.
To find sharing candidates, ESX hashes contents of each page and uses hash collisions to identify potential duplicates. To guard against false collisions, both ESX server and Difference Engine perform a byte-by-byte comparison before actually sharing the page.
Once shared, our system can manage page updates in a copy-on-write fashion, as in Disco and ESX server. We build upon earlier work on flash cloning [23] of VMs, which allows new VMs to be cloned from an existing VM in milliseconds; as the newly created VM writes to its memory, it is given private copies of the shared pages. An extension by Kloster et al. studied page sharing in Xen [13] and we build upon this experience, adding support for fully virtualized (HVM) guests, integrating the global clock, and improving the overall reliability and performance.
Our initial investigations into page similarity were inspired by research in leveraging similarity across files in large file systems. In GLIMPSE [18], Manber proposed computing Rabin fingerprints over fixed-size blocks at multiple offsets in a file. Similar files will then share some fingerprints. Thus the maximum number of common fingerprints is a strong indicator of similarity. However, in a dynamically evolving virtual memory system, this approach does not scale well since every time a page changes its fingerprints must be recomputed as well. Further, it is inefficient to find the maximal intersecting set from among a large number of candidate pages.
Broder adapted Manber's approach to the problem of identifying documents (in this case, Web pages) that are nearly identical using a combination of Rabin fingerprints and sampling based on minimum values under a set of random permutations [8]. His paper also contains a general discussion of how thresholds should be set for inferring document similarity based on the number of common fingerprints or sets of fingerprints.
While these techniques can be used to identify similar files, they do not address how to efficiently encode the differences. Douglis and Iyengar explored using Rabin fingerprints and delta encoding to compress similar files in the DERD system [12], but only considered whole files. Kulkarni et al. [14] extended the DERD scheme to exploit similarity at the block level. Difference Engine also tries to exploit memory redundancy at several different granularities.
|
In-memory compression is not a new idea. Douglis et al. [11] implemented memory compression in the Sprite operating system with mixed results. In their experience, memory compression was sometimes beneficial, but at other times the performance overhead outweighed the memory savings. Subsequently, Wilson et al. argued Douglis' mixed results were primarily due to slow hardware [25]. They also developed new compression algorithms (leveraged by Difference Engine) that exploited the inherent structure present in virtual memory, whereas earlier systems used general-purpose compression algorithms.
Despite its mixed history, several operating systems have dabbled with in-memory compression. In the early 90s, a Macintosh application, Ram Doubler, promised to ``double a machine's RAM'' [15]. Tuduce et al. [22] implemented a compressed cache for Linux that adaptively manages the amount of physical memory devoted to compressed pages using a simple algorithm shown to be effective across a wide variety of workloads.
Difference Engine uses three distinct mechanisms that work together to realize the benefits of memory sharing, as shown in Figure 1. In this example, two VMs have allocated five pages total, each initially backed by distinct pages in machine memory (Figure 1(a)). For brevity, we only show how the mapping from guest physical memory to machine memory changes; the guest virtual to guest physical mapping remains unaffected. First, for identical pages across the VMs, we store a single copy and create references that point to the original. In Figure 1(b), one page in VM-2 is identical to one in VM-1. For pages that are similar, but not identical, we store a patch against a reference page and discard the redundant copy. In Figure 1(c), the second page of VM-2 is stored as a patch to the second page of VM-1. Finally, for pages that are unique and infrequently accessed, we compress them in memory to save space. In Figure 1(d), the remaining private page in VM-1 is compressed. The actual machine memory footprint is now less than three pages, down from five pages originally.
In all three cases, efficiency concerns require us to select candidate pages that are unlikely to be accessed in the near future. We employ a global clock that scans memory in the background, identifying pages that have not been recently used. In addition, reference pages for sharing or patching must be found quickly without introducing performance overhead. Difference Engine uses full-page hashes and hash-based fingerprints to identify good candidates. Finally, we implement a demand paging mechanism that supplements main memory by writing VM pages to disk to support overcommitment, allowing the total memory required for all VMs to temporarily exceed the physical memory capacity.
Difference Engine's implementation of content-based page sharing is similar to those in earlier systems. We walk through memory looking for identical pages. As we scan memory, we hash each page and index it based on its hash value. Identical pages hash to the same value and a collision indicates that a potential matching page has been found. We perform a byte-by-byte comparison to ensure that the pages are indeed identical before sharing them.
Upon identifying target pages for sharing, we reclaim one of the pages and update the virtual memory to point at the shared copy. Both mappings are marked read-only, so that writes to a shared page cause a page fault that will be trapped by the VMM. The VMM returns a private copy of the shared page to the faulting VM and updates the virtual memory mappings appropriately. If no VM refers to a shared page, the VMM reclaims it and returns it to the free memory pool.
Traditionally, the goal of page sharing has been to eliminate redundant copies of identical pages. Difference Engine considers further reducing the memory required to store similar pages by constructing patches that represent a page as the difference relative to a reference page. To motivate this design decision, we provide an initial study into the potential savings due to sub-page sharing, both within and across virtual machines. First, we define the following two heterogeneous workloads, each involving three 512-MB virtual machines:
We designed these workloads to stress the memory-saving mechanisms since opportunities for identical page sharing are reduced. Our choice of applications was guided by the VMmark benchmark [17] and the vmbench suite [20]. In this first experiment, for a variety of configurations, we suspend the VMs after completing a benchmark, and consider a static snapshot of their memory to determine the number of pages required to store the images using various techniques. Table 1 shows the results of our analysis for the MIXED-1 workload.
The first column breaks down these 393,120 pages into three categories: 149,038 zero pages (i.e., the page contains all zeros), 52,436 sharable pages (the page is not all zeros, and there exists at least one other identical page), and 191,646 unique pages (no other page in memory is exactly the same). The second column shows the number of pages required to store these three categories of pages using traditional page sharing. Each unique page must be preserved; however, we only need to store one copy of a set of identical pages. Hence, the 52,436 non-unique pages contain only 3577 distinct pages--implying there are roughly fourteen copies of every non-unique page. Furthermore, only one copy of the zero page is needed. In total, the 393,120 original pages can be represented by 195,224 distinct pages--a 50% savings.
The third column depicts the additional savings available if we consider sub-page sharing. Using a cut-off of 2 KB for the patch size (i.e., we do not create a patch if it will take up more than half a page), we identify 144,497 distinct pages eligible for patching. We store the 50,727 remaining pages as is and use them as reference pages for the patched pages. For each of the similar pages, we compute a patch using Xdelta [16]. The average patch size is 1,070 bytes, allowing them to be stored in 37,695 4-KB pages, saving 106,802 pages. In sum, sub-page sharing requires only 88,422 pages to store the memory for all VMs instead of 195,224 for full-page sharing or 393,120 originally--an impressive 77% savings, or almost another 50% over full-page sharing. We note that this was the least savings in our experiments; the savings from patching are even higher in most cases. Further, a significant amount of page sharing actually comes from zero pages and, therefore, depends on their availability. For instance, the same workload when executed on 256-MB VMs yields far fewer zero pages. Alternative mechanisms to page sharing become even more important in such cases.
One of the principal complications with sub-page sharing is identifying
candidate reference pages. Difference Engine uses a parameterized scheme to identify
similar pages based upon the hashes of several 64-byte portions of each page.
In particular, HashSimilarityDetector![]() hashes the contents of
hashes the contents of ![]() 64-byte blocks at randomly chosen locations on the page, and then groups
these hashes together into
64-byte blocks at randomly chosen locations on the page, and then groups
these hashes together into ![]() groups of
groups of ![]() hashes each. We use each group
as an index into a hash table. In other words, higher values of
hashes each. We use each group
as an index into a hash table. In other words, higher values of ![]() capture local similarity while higher
capture local similarity while higher ![]() values incorporate
global similarity. Hence, HashSimilarityDetector(1,1) will
choose one block on a page and index that block; pages are considered similar
if that block of data matches. HashSimilarityDetector(1,2) combines the
hashes from two different locations in the page into one index of length two.
HashSimilarityDetector(2,1) instead indexes each page twice: once based on
the contents of a first block, and again based on the contents of a second
block. Pages that match at least one of the two blocks are chosen as
candidates.
For each scheme, the number of candidates,
values incorporate
global similarity. Hence, HashSimilarityDetector(1,1) will
choose one block on a page and index that block; pages are considered similar
if that block of data matches. HashSimilarityDetector(1,2) combines the
hashes from two different locations in the page into one index of length two.
HashSimilarityDetector(2,1) instead indexes each page twice: once based on
the contents of a first block, and again based on the contents of a second
block. Pages that match at least one of the two blocks are chosen as
candidates.
For each scheme, the number of candidates, ![]() , specifies how many
different pages the hash table tracks for each signature. With
one candidate, we only store the first page found with each signature;
for larger values, we keep multiple pages in the hash table for each
index. When trying to build a patch, Difference Engine computes a patch
between all matching pages and chooses the best one.
, specifies how many
different pages the hash table tracks for each signature. With
one candidate, we only store the first page found with each signature;
for larger values, we keep multiple pages in the hash table for each
index. When trying to build a patch, Difference Engine computes a patch
between all matching pages and chooses the best one.
![\includegraphics[width=3in]{figures/patching-offline-analysis.eps}](img10.png)
|
Figure 2 shows the effectiveness of this
scheme for various parameter settings on the two workloads described
above. On the X-axis, we have
parameters in the format ![]() , and on the Y-axis we
plot the total savings from patching after all identical pages have
been shared. Throughout the paper, we use the following definition of
savings (we factor in the memory used to store the shared and
patched/compressed pages):
, and on the Y-axis we
plot the total savings from patching after all identical pages have
been shared. Throughout the paper, we use the following definition of
savings (we factor in the memory used to store the shared and
patched/compressed pages):

For both the workloads, HashSimilarityDetector(2,1) with one candidate does surprisingly well. There is a substantial gain due to hashing two distinct blocks in the page separately, but little additional gain by hashing more blocks. Combining blocks does not help much, at least for these workloads. Furthermore, storing more candidates in each hash bucket also produces little gain. Hence, Difference Engine indexes a page by hashing 64-byte blocks at two fixed locations in the page (chosen at random) and using each hash value as a separate index to store the page in the hash table. To find a candidate similar page, the system computes hashes at the same two locations, looks up those hash table entries, and chooses the better of the (at most) two pages found there.
Our current implementation uses 18-bit hashes to keep the hash table small to cope with the limited size of the Xen heap. In general though, larger hashes might be used for improved savings and fewer collisions. Our analysis indicates, however, that the benefits from increasing the hash size are modest. For example, using HashSimilarityDetector(2,1) with one candidate, a 32-bit hash yields a savings of 24.66% for MIXED-1, compared to a savings of 20.11% with 18-bit hashes.
Finally, for pages that are not significantly similar to other pages in memory, we consider compressing them to reduce the memory footprint. Compression is useful only if the compression ratio is reasonably high, and, like patching, if selected pages are accessed infrequently, otherwise the overhead of compression/decompression will outweigh the benefits. We identify candidate pages for compression using a global clock algorithm (Section 4.2), assuming that pages that have not been recently accessed are unlikely to be accessed in the near future.
Difference Engine supports multiple compression algorithms, currently LZO and WKdm as described in [25]; We invalidate compressed pages in the VM and save them in a dynamically allocated storage area in machine memory. When a VM accesses a compressed page, Difference Engine decompresses the page and returns it to the VM uncompressed. It remains there until it is again considered for compression.
While Difference Engine will deliver some (typically high) level of memory savings, in the worst case all VMs might actually require all of their allocated memory. Setting aside sufficient physical memory to account for this case prevents using the memory saved by Difference Engine to create additional VMs. Not doing so, however, may result in temporarily overshooting the physical memory capacity of the machine and cause a system crash. We therefore require a demand-paging mechanism to supplement main memory by writing pages out to disk in such cases.
A good candidate page for swapping out would likely not be accessed in the near future--the same requirement as compressed/patched pages. In fact, Difference Engine also considers compressed and patched pages as candidates for swapping out. Once the contents of the page are written to disk, the page can be reclaimed. When a VM accesses a swapped out page, Difference Engine fetches it from disk and copies the contents into a newly allocated page that is mapped appropriately in the VM's memory.
Since disk I/O is involved, swapping in/out is an expensive operation. Further, a swapped page is unavailable for sharing or as a reference page for patching. Therefore, swapping should be an infrequent operation. Difference Engine implements the core mechanisms for paging, and leaves policy decisions--such as when and how much to swap--to user space tools. We describe our reference implementation for swapping and the associated tools in Section 4.6.
We have implemented Difference Engine on top of Xen 3.0.4 in roughly 14,500 lines of code. An additional 20,000 lines come from ports of existing patching and compression algorithms (Xdelta, LZO, WKdm) to run inside Xen.
Xen and other platforms that support fully virtualized guests use a mechanism called ``shadow page tables'' to manage guest OS memory [24]. The guest OS has its own copy of the page table that it manages believing that they are the hardware page tables, though in reality it is just a map from the guest's virtual memory to its notion of physical memory (V2P map). In addition, Xen maintains a map from the guest's notion of physical memory to the machine memory (P2M map). The shadow page table is a cache of the results of composing the V2P map with the P2M map, mapping guest virtual memory directly to machine memory. Loosely, it is the virtualized analog to a software TLB. The shadow page table enables quick page translation and look-ups, and more importantly, can be used directly by the CPU.
Difference Engine relies on manipulating P2M maps and the shadow page tables to interpose on page accesses. For simplicity, we do not consider any pages mapped by Domain-0 (the privileged, control domain in Xen), which, among other things, avoids the potential for circular page faults. Our implementation method gives rise to two slight complications.
On x86 hardware, the booting-on-bare-metal process disables the x86 real-mode paging. This configuration is required because the OS needs to obtain some information from the BIOS for the boot sequence to proceed. When executing under Xen, this requirement means that paging is disabled during the initial stages of the boot process, and shadow page tables are not used until paging is turned on. Instead, the guest employs a direct P2M map as the page table. Hence, a VM's memory is not available for consideration by Difference Engine until paging has been turned on within the guest OS.
To support unmodified operating system requirements for I/O access, the Xen hypervisor must emulate much of the underlying hardware that the OS expects (such as the BIOS and the display device). Xen has a software I/O emulator based on Qemu [7]. A per-VM user-space process in Domain-0 known as ioemu performs all necessary I/O emulation. The ioemu must be able to read and write directly into the guest memory, primarily for efficiency. For instance, this enables the ioemu process to DMA directly into pages of the VM. By virtue of executing in Domain-0, the ioemu may map any pages of the guest OS in its address space.
By default, ioemu maps the entire memory of the guest into its address space for simplicity. Recall, however, that Difference Engine explicitly excludes pages mapped by Domain-0. Thus, ioemu will nominally prevent us from saving any memory at all, since every VM's address space will be mapped by its ioemu into Domain-0. Our initial prototype addressed this issue by modifying ioemu to map a small, fixed number (16) of pages from each VM at any given time. While simple to implement, this scheme suffered from the drawback that, for I/O-intensive workloads, the ioemu process would constantly have to map VM pages into its address space on demand, leading to undesirable performance degradation. To address this limitation, we implemented a dynamic aging mechanism in ioemu--VM pages are mapped into Domain-0 on demand, but not immediately unmapped. Every ten seconds, we unmap VM pages which were not accessed during the previous interval.
Patching and compression may result in compact representations of a page that are much smaller than the page size. We wrote a custom block allocator for Difference Engine to efficiently manage storage for patched and compressed pages. The allocator acquires pages from the domain heap (from which memory for new VMs is allocated) on demand, and returns pages to the heap when no longer required.
Difference Engine implements a not-recently-used (NRU) policy [21] to select candidate pages for sharing, patching, compression and swapping out. On each invocation, the clock scans a portion of the memory, checking and clearing the referenced (R) and modified (M) bits on pages. Thus, pages with the R/M bits set must have been referenced/modified since the last scan. We ensure that successive scans of memory are separated by at least four seconds in the current implementation to give domains a chance to set the R/M bits on frequently accessed pages. In the presence of multiple VMs, the clock scans a small portion of each VM's memory in turn for fairness. The external API exported by the clock is simple: return a list of pages (of some maximum size) that have not been accessed in some time.
In OSes running on bare metal, the R/M bits on page-table entries are typically updated by the processor. Xen structures the P2M map exactly like the page tables used by the hardware. However, since the processor does not actually use the P2M map as a page table, the R/M bits are not updated automatically. We modify Xen's shadow page table code to set these bits when creating readable or writable page mappings. Unlike conventional operating systems, where there may be multiple sets of page tables that refer to the same set of pages, in Xen there is only one P2M map per domain. Hence, each guest page corresponds unambiguously to one P2M entry and one set of R/M bits.
Using the R/M bits, we can annotate each page with its ``freshness'':
Note that the existing two R/M bits are not sufficient to classify C4 pages--we extend the clock's ``memory'' by leveraging two additional bits in the page table entries to identify such pages. We update these bits when a page is classified as C3 in consecutive scans. Together, these four annotations enable a clean separation between mechanism and policy, allowing us to explore different techniques to determine when and what to share, patch, and compress. By default, we employ the following policy. C1 pages are ignored; C2 pages are considered for sharing and to be reference pages for patching, but cannot be patched or compressed themselves; C3 pages can be shared or patched; C4 pages are eligible for everything, including compression and swapping.
We consider sharing first since it delivers the most memory savings in exchange for a small amount of meta data. We consider compression last because once a page is compressed, there is no opportunity to benefit from future sharing or patching of that page. An alternate, more aggressive policy might treat all pages as if they were in state C4 (not accessed in a long time)--in other words, proactively patch and compress pages. Initial experimentation indicates that while the contribution of patched and compressed pages does increase slightly, it does not yield a significant net savings. We also considered a policy that selects pages for compression before patching. Initial experimentation with the workloads in Section 5.4.2 shows that this policy performs slightly worse than the default in terms of savings, but incurs less performance overhead since patching is more resource intensive. We suspect that it may be a good candidate policy for heterogeneous workloads with infrequently changing working sets, but do not explore it further here.
Difference Engine uses the SuperFastHash [4] function to compute digests
for each scanned page and inserts them along with the page-frame number into a
hash table.
Ideally, the hash table should be sized so that it can hold entries for all of
physical memory. The hash table is allocated out of Xen's heap space, which
is quite limited in size: the code, data, and heap segments in Xen must all
fit in a 12-MB region of memory. Changing the heap size requires pervasive
code changes in Xen, and will likely break the application binary interface
(ABI) for some OSes. We therefore restrict the size of the page-sharing hash
table so that it can hold entries for only ![]() of physical memory. Hence
Difference Engine processes memory in five passes, as described by Kloster et al.
[13]. In our test configuration, this partitioning results in a
1.76-MB hash table. We divide the space of hash function values into five
intervals, and only insert a page into the table if its hash value falls into
the current interval. A complete cycle of five passes covering all the hash
value intervals is required to identify all identical pages.
of physical memory. Hence
Difference Engine processes memory in five passes, as described by Kloster et al.
[13]. In our test configuration, this partitioning results in a
1.76-MB hash table. We divide the space of hash function values into five
intervals, and only insert a page into the table if its hash value falls into
the current interval. A complete cycle of five passes covering all the hash
value intervals is required to identify all identical pages.
The goal of the page-similarity component is to find pairs of pages with similar content, and, hence, make candidates for patching. We implement a simple strategy for finding similar pages based on hashing short blocks within a page, as described in Section 3.2. Specifically, we use the HashSimilarityDetector(2,1) described there, which hashes short data blocks from two locations on each page, and indexes the page at each of those two locations in a separate page-similarity hash table, distinct from the page-sharing hash table described above. We use the 1-candidate variation, where at most one page is indexed for each block hash value.
Recall that the clock makes a complete scan through memory in five passes. The page-sharing hash table is cleared after each pass, since only pages within a pass are considered for sharing. However, two similar pages may appear in different passes if their hash values fall in different intervals. Since we want to only consider pages that have not been shared in a full cycle for patching, the page-similarity hash table is not cleared on every pass. This approach also increases the chances of finding better candidate pages to act as the reference for a patch.
The page-similarity hash table may be cleared after considering every page in memory--that is, at the end of each cycle of the global clock. We do so to prevent stale data from accumulating: if a page changes after it has been indexed, we should remove old pointers to it. Since we do not trap on write operations, it is simpler to just discard and rebuild the similarity hash table.
Only the last step of patching--building the patch and replacing the page with it--requires a lock. We perform all earlier steps (indexing and lookups to find similar pages) without pausing any domains. Thus, the page contents may change after Difference Engine indexes the page, or after it makes an initial estimate of patch size. This is fine since the goal of these steps is to find pairs of pages that will likely patch well. An intervening page modification will not cause a correctness problem, only a patch that is larger than originally intended.
Compression operates similarly to patching--in both cases the goal is to replace a page with a shorter representation of the same data. The primary difference is that patching makes use of a reference page, while a compressed representation is self contained.
There is one important interaction between compression and patching: once we compress a page, the page can no longer be used as a reference for a later patched page. A naive implementation that compresses all non-identical pages as it goes along will almost entirely prevent page patches from being built. Compression of a page should be postponed at least until all pages have been checked for similarity against it. A complete cycle of a page sharing scan will identify similar pages, so a sufficient condition for compression is that no page should be compressed until a complete cycle of the page sharing code finishes. We make the definition of ``not accessed for an extended period'' in the clock algorithm coincide with this condition (state C4). As mentioned in Section 4.2, this is our default policy for page compression.
Recall that any memory freed by Difference Engine cannot be used reliably without supplementing main memory with secondary storage. That is, when the total allocated memory of all VMs exceeds the system memory capacity, some pages will have to be swapped to disk. Note that this ability to overcommit memory is useful in Xen independent of other Difference Engine functionality, and has been designed accordingly.
The Xen VMM does not perform any I/O (delegating all I/O to Domain-0) and is not aware of any devices. Thus, it is not possible to build swap support directly in the VMM. Further, since Difference Engine supports unmodified OSes, we cannot expect any support from the guest OS. Figure 3 shows the design of our swap implementation guided by these constraints. A single swap daemon (swapd) running as a user process in Domain-0 manages the swap space. For each VM in the system, swapd creates a separate thread to handle swap-in requests. Swapping out is initiated by swapd, when one of the following occurs:
Note that swapd always treats a swap-out request as a hint. It will try to free pages, but if that is not possible--if no suitable candidate page was available, for instance, or if the swap space became full--it continues silently. A single flat file of configurable size is used as storage for the swap space.
To swap out a page, swapd makes a hypercall into Xen, where a victim
page is chosen by invoking the global clock. If the victim is a compressed or
patched page, we first reconstruct it. We pause the VM that owns the page
and copy the contents of the page to a page in Domain-0's address space
(supplied by swapd). Next, we remove all entries pointing to the
victim page in the P2M and M2P maps, and in the shadow page tables.
We then mark the page as swapped out in the corresponding page table
entry. Meanwhile, swapd writes the page contents to the swap
file and inserts the corresponding byte offset in a hash table keyed
by ![]() Domain ID, guest page-frame number
Domain ID, guest page-frame number![]() . Finally, we free the
page, return it to the domain heap, and reschedule the VM.
. Finally, we free the
page, return it to the domain heap, and reschedule the VM.
When a VM tries to access a swapped page, it incurs a page fault and traps into Xen. We pause the VM and allocate a fresh page to hold the swapped in data. We populate the P2M and M2P maps appropriately to accommodate the new page. Xen dispatches a swap-in request to swapd containing the domain ID and the faulting page-frame number. The handler thread for the faulting domain in swapd receives the request and fetches the location of the page in the swap file from the hash table. It then copies the page contents into the newly allocated page frame within Xen via another hypercall. At this point, swapd notifies Xen, and Xen restarts the VM at the faulting instruction.
This implementation leads to two interesting interactions between ioemu and swapd. First, recall that ioemu can directly write to a VM page mapped in its address space. Mapped pages might not be accessed until later, so a swapped page can get mapped or a mapped page can get swapped out without immediate detection. To avoid unnecessary subsequent swap ins, we modify ioemu to ensure that pages to be mapped will be first swapped in if necessary and that mapped pages become ineligible for swapping. Also note that control must be transferred from Xen to swapd for a swap in to complete. This asynchrony allows a race condition where ioemu tries to map a swapped out page (so Xen initiates a swap in on its behest) and proceeds with the access before the swap in has finished. This race can happen because both processes must run in Domain-0 in the Xen architecture. As a work around, we modify ioemu to block if a swap in is still in progress inside swapd using shared memory between the processes for the required synchronization.
We first present micro-benchmarks to evaluate the cost of individual operations, the performance of the global clock and the behavior of each of the three mechanisms in isolation. Next, we evaluate whole system performance: for a range of workloads, we measure memory savings and the impact on application performance. We quantify the contributions of each Difference Engine mechanism, and also present head-to-head comparisons with the VMware ESX server. Finally, we demonstrate how our memory savings can be used to boost the aggregate system performance. Unless otherwise mentioned, all experiments are run on dual-processor, dual-core 2.33-GHz Intel Xeon machines and the page size is 4 KB.
|
Before quantifying the memory savings provide by Difference Engine, we measure the overhead of various functions involved. We obtain these numbers by enabling each mechanism in isolation, and running the custom micro-benchmark described in Section 5.3. To benchmark paging, we disabled all three mechanisms and forced eviction of 10,000 pages from a single 512-MB VM. We then ran a simple program in the VM that touches all memory to force pages to be swapped in.
Table 2 shows the overhead imposed by the major
Difference Engine operations. As expected, collapsing identical pages into a
copy-on-write shared page (share_page) and recreating
private copies (cow_break) are relatively cheap operations,
taking approximately 6 and 25 ![]() s, respectively. Perhaps more
surprising, however, is that compressing a page on our hardware is
fast, requiring slightly less than 30
s, respectively. Perhaps more
surprising, however, is that compressing a page on our hardware is
fast, requiring slightly less than 30 ![]() s on average. Patching, on
the other hand, is almost an order of magnitude slower: creating a
patch (patch_page) takes over 300
s on average. Patching, on
the other hand, is almost an order of magnitude slower: creating a
patch (patch_page) takes over 300 ![]() s. This time is
primarily due to the overhead of finding a good candidate base page
and constructing the patch. Both decompressing a page and
re-constructing a patched page are also fairly fast, taking 10 and 18
s. This time is
primarily due to the overhead of finding a good candidate base page
and constructing the patch. Both decompressing a page and
re-constructing a patched page are also fairly fast, taking 10 and 18
![]() s respectively.
s respectively.
Swapping out takes approximately 50 ![]() s. However, this does not include
the time to actually write the page to disk. This is intentional: once
the page contents have been copied to user space, they are
immediately available for being swapped in; and the actual write to
the disk might be delayed because of file system and OS buffering in
Domain-0.
Swapping in, on the other hand, is the most expensive operation, taking
approximately
7 ms. There are a few caveats, however. First, swapping in is an asynchronous operation and
might be affected by several factors, including process scheduling within
Domain-0; it is not a tight bound. Second, swapping in might require
reading the page from disk, and the seek time will depend on the
size of the swap file, among other things.
s. However, this does not include
the time to actually write the page to disk. This is intentional: once
the page contents have been copied to user space, they are
immediately available for being swapped in; and the actual write to
the disk might be delayed because of file system and OS buffering in
Domain-0.
Swapping in, on the other hand, is the most expensive operation, taking
approximately
7 ms. There are a few caveats, however. First, swapping in is an asynchronous operation and
might be affected by several factors, including process scheduling within
Domain-0; it is not a tight bound. Second, swapping in might require
reading the page from disk, and the seek time will depend on the
size of the swap file, among other things.
The performance of applications running with Difference Engine depends upon how effectively we choose idle pages to compress or patch. Patching and compression are computationally intensive, and the benefits of this overhead last only until the next access to the page. Reads are free for shared pages, but not so for compressed or patched pages. The clock algorithm is intended to only consider pages for compression/patching that are not likely to be accessed again soon; here we evaluate how well it achieves that goal.
![\includegraphics[width=2.5in]{figures/lifetime.eps}](img18.png)
|
For three different workloads, we trace the lifetime of each patched and compressed page. The lifetime of a page is the time between when it was patched/compressed, and the time of the first subsequent access (read or write). The workloads range from best case homogeneous configurations (same OS, same applications) to a worst case, highly heterogeneous mix (different OSes, different applications). The RUBiS and kernel compile workloads use four VMs each (Section 5.4.1). We use the MIXED-1 workload described earlier (Section 3.2) as the heterogeneous workload.
Figure 4 plots the cumulative distribution of the lifetime of a page: the X-axis shows the lifetime (in ms) in log scale, and the Y-axis shows the fraction of compressed/patched pages. A good clock algorithm should give us high lifetimes, since we would like to patch/compress only those pages which will not be accessed in the near future. As the figure shows, almost 80% of the victim pages have a lifetime of at least 10 seconds, and roughly 50% have a lifetime greater than 100 seconds. This is true for both the homogeneous and the mixed workloads, indicating that our NRU implementation works well in practice.
|
|
|
To understand the individual contribution of the three techniques, we first quantify the performance of each in isolation. We deployed Difference Engine on three machines running Debian 3.1 on a VM. Each machine is configured to use a single mechanism--one machine uses just page sharing, one uses just compression, and one just patching. We then subject all the machines to the same workload and profile the memory utilization.
To help distinguish the applicability of each technique to various page contents, we choose a custom workload generator that manipulates memory in a repeatable, predictable manner over off-the-shelf benchmarks. Our workload generator runs in four phases. First it allocates pages of a certain type. To exercise the different mechanisms in predictable ways, we consider four distinct page types: zero pages, random pages, identical pages and similar-but-not-identical pages. Second, it reads all the allocated pages. Third, it makes several small writes to all the pages. Finally, it frees all allocated pages and exits. After each step, the workload generator idles for some time, allowing the memory to stabilize. For each run of the benchmark, we spawn a new VM and start the workload generator within it. At the end of each run, we destroy the container VM and again give memory some time to stabilize before the next run. We ran benchmarks with varying degrees of similarity, where similarity is defined as follows: a similarity of 90% means all pages differ from a base page by 10%, and so any two pages will differ from each other by at most 20%. Here, we present the results for 95%-similar pages, but the results for other values are similar.
Each VM image is configured with 256 MB of memory. Our workload generator allocates pages filling 75% (192 MB) of the VM's memory. The stabilization period is a function of several factors, particularly the period of the global clock. For these experiments, we used a sleep time of 80 seconds between each phase. During the write step, the workload generator writes a single constant byte at 16 fixed offsets in the page. On each of the time series graphs, the significant events during the run are marked with a vertical line. These events are: (1) begin and (2) end of the allocation phase, (3) begin and (4) end of the read phase, (5) begin and (6) end of the write phase, (7) begin and (8) end of the free phase, and (9) VM destruction.
Figure 5 shows the memory savings as a function of time for each mechanism for identical pages (for brevity, we omit results with zero pages--they are essentially the same as identical pages). Note that while each mechanism achieves similar savings, the crucial difference is that reads are free for page sharing. With compression/patching, even a read requires the page to be reconstructed, leading to the sharp decline in savings around event (3) and (5).
At the other extreme are random pages. Intuitively, none of the mechanisms should work well since the opportunity to share memory is scarce. Figure 6 agrees: once the pages have been allocated, none of the mechanisms are able to share more than 15-20% memory. Page sharing does the worst, managing 5% at best.
From the perspective of page sharing, similar pages are no better than random pages. However, patching should take advantage of sub-page similarity across pages. Figure 7 shows the memory savings for the workload with pages of 95% similarity. Note how similar the graphs for sharing and compression look for similar and random pages. Patching, on the other hand, does substantially better, extracting up to 55% savings.
We now present the performance of Difference Engine on a variety of workloads. We seek to answer two questions. First, how effective are the memory-saving mechanisms at reducing memory usage for real-world applications? Second, what is the impact of those memory-sharing mechanisms on system performance? Since the degree of possible sharing depends on the software configuration, we consider several different cases of application mixes.
To put our numbers in perspective, we conduct head-to-head comparisons with VMware ESX server for three different workload mixes. We run ESX Server 3.0.1 build 32039 on a Dell PowerEdge 1950 system. Note that even though this system has two 2.3-GHz Intel Xeon processors, our VMware license limits our usage to a single CPU. We therefore restrict Xen (and, hence, Difference Engine) to use a single CPU for fairness. We also ensure that the OS images used with ESX match those used with Xen, especially the file system and disk layout. Note that we are only concerned with the effectiveness of the memory sharing mechanisms--not in comparing the application performance across the two hypervisors. Further, we configure ESX to use its most aggressive page sharing settings where it scans 10,000 pages/second (default 200); we configure Difference Engine similarly.
|
|
|
|
In our first set of benchmarks, we test the base scenario where all VMs on a machine run the same OS and applications. This scenario is common in cluster-based systems where several services are replicated to provide fault tolerance or load balancing. Our expectation is that significant memory savings are available and that most of the savings will come from page sharing.
On a machine running standard Xen, we start from 1 to 6 VMs, each with 256 MB of memory and running RUBiS [10]--an e-commerce application designed to evaluate application server performance--on Debian 3.1. We use the PHP implementation of RUBiS; each instance consists of a Web server (Apache) and a database server (MySQL). Two distinct client machines generate the workload, each running the standard RUBiS workload generator simulating 100 user sessions. The benchmark runs for roughly 20 minutes. The workload generator reports several metrics at the end of the benchmark, in particular the average response time and the total number of requests served.
We then run the same set of VMs with Difference Engine enabled. Figures 8(a) and 8(b) show that both the total number of requests and the average response time remain unaffected while delivering 65-75% memory savings in all cases. In Figure 8(c), the bars indicate the average memory savings over the duration of the benchmark. Each bar also shows the individual contribution of each mechanism. Note that in this case, the bulk of memory savings comes from page sharing. Recall that Difference Engine tries to share as many pages as it can before considering pages for patching and compression, so sharing is expected to be the largest contributor in most cases, particularly in homogeneous workloads.
Next, we conduct a similar experiment where each VM compiles the Linux kernel (version 2.6.18). Since the working set of VMs changes much more rapidly in a kernel compile, we expect less memory savings compared to the RUBiS workload. As before, we measure the time taken to finish the compile and the memory savings for varying number of virtual machines. We summarize the results here for brevity: in each case, the performance under Difference Engine is within 5% of the baseline, and on average Difference Engine delivers around 40% savings with four or more VMs.
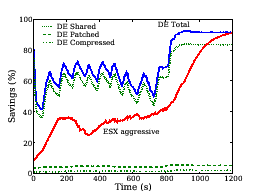
We next compare Difference Engine performance with the VMware ESX server. We set up four 512-MB virtual machines running Debian 3.1. Each VM executes dbench [2] for ten minutes followed by a stabilization period of 20 minutes. Figure 9 shows the amount of memory saved as a function of time. First, note that eventually both ESX and Difference Engine reclaim roughly the same amount of memory (the graph for ESX plateaus beyond 1,200 seconds). However, while dbench is executing, Difference Engine delivers approximately 1.5 times the memory savings achieved by ESX. As before, the bulk of Difference Engine savings come from page sharing for the homogeneous workload case.
Given the increasing trend towards virtualization, both on the desktop and in the data center, we envision that a single physical machine will host significantly different types of operating systems and workloads. While smarter VM placement and scheduling will mitigate some of these differences, there will still be a diverse and heterogeneous mix of applications and environments, underscoring the need for mechanisms other than page sharing. We now examine the utility of Difference Engine in such scenarios, and demonstrate that significant additional memory savings result from employing patching and compression in these settings.
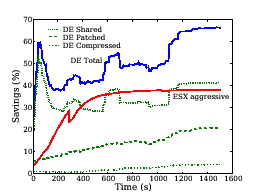
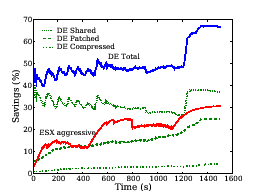
Figures 10 and 11 show the memory savings as a function of time for the two heterogeneous workloads--MIXED-1 and MIXED-2 described in Section 3.2. We make the following observations. First, in steady state, Difference Engine delivers a factor of 1.6-2.5 more memory savings than ESX. For instance, for the MIXED-2 workload, Difference Engine could host the three VMs allocated 512 MB of physical memory each in approximately 760 MB of machine memory; ESX would require roughly 1100 MB of machine memory. The remaining, significant, savings come from patching and compression. And these savings come at a small cost. Table 3 summarizes the performance of the three benchmarks in the MIXED-1 workload. The baseline configuration is regular Xen without Difference Engine. In all cases, performance overhead of Difference Engine is within 7% of the baseline. For the same workload, we find that performance under ESX with aggressive page sharing is also within 5% of the ESX baseline with no page sharing.
|
Difference Engine goes to great lengths to reclaim memory in a system, but eventually this extra memory needs to actually get used in a productive manner. One can certainly use the saved memory to create more VMs, but does that increase the aggregate system performance?
To answer this question, we created four VMs with 650 MB of RAM each on a physical machine with 2.8 GB of free memory (excluding memory allocated to Domain-0). For the baseline (without Difference Engine), Xen allocates memory statically. Upon creating all the VMs, there is clearly not enough memory left to create another VM of the same configuration. Each VM hosts a RUBiS instance. For this experiment, we used the Java Servlets implementation of RUBiS. There are two distinct client machines per VM to act as workload generators.
The goal is to increase the load on the system to saturation. The solid lines in Figures 12(a) and 12(b) show the total requests served and the average response time for the baseline, with the total offered load marked on the X-axis. Note that beyond 960 clients, the total number of requests served plateaus at around 180,000 while the average response time increases sharply. Upon investigation, we find that for higher loads all of the VMs have more than 95% memory utilization and some VMs actually start swapping to disk (within the guest OS). Using fewer VMs with more memory (for example, 2 VMs with 1.2 GB RAM each) did not improve the baseline performance for this workload.
|
Next, we repeat the same experiment with Difference Engine, except this time we utilize reclaimed memory to create additional VMs. As a result, for each data point on the X-axis, the per VM load decreases, while the aggregate offered load remains the same. We expect that since each VM individually has lower load compared to the baseline, the system will deliver better aggregate performance. The remaining lines in Figures 12(a) and 12(b) show the performance with up to three extra VMs. Clearly, Difference Engine enables higher aggregate performance and better response time compared to the baseline. However, beyond a certain point (two additional VMs in this case), the overhead of managing the extra VMs begins to offset the performance benefits: Difference Engine has to effectively manage 4.5 GB of memory on a system with 2.8 GB of RAM to support seven VMs. In each case, beyond 1400 clients, the VMs working set becomes large enough to invoke the paging mechanism: we observe between 5,000 pages (for one extra VM) to around 20,000 pages (for three extra VMs) being swapped out, of which roughly a fourth get swapped back in.
One of the primary bottlenecks to higher degrees of virtual machine multiplexing is main memory. Earlier work shows that substantial memory savings are available from harvesting identical pages across virtual machines when running homogeneous workloads. The premise of this work is that there are significant additional memory savings available from locating and patching similar pages and in-memory page compression. We present the design and evaluation of Difference Engine to demonstrate the potential memory savings available from leveraging a combination of whole page sharing, page patching, and compression. We discuss our experience addressing a number of technical challenges, including: i) algorithms to quickly identify candidate pages for patching, ii) demand paging to support over-subscription of total assigned physical memory, and iii) a clock mechanism to identify appropriate target machine pages for sharing, patching, compression and paging. Our performance evaluation shows that Difference Engine delivers an additional factor of 1.6-2.5 more memory savings than VMware ESX Server for a variety of workloads, with minimal performance overhead. Difference Engine mechanisms might also be leveraged to improve single OS memory management; we leave such exploration to future work.
This document was generated using the LaTeX2HTML translator Version 2002-2-1 (1.71)
Copyright © 1993, 1994, 1995, 1996,
Nikos Drakos,
Computer Based Learning Unit, University of Leeds.
Copyright © 1997, 1998, 1999,
Ross Moore,
Mathematics Department, Macquarie University, Sydney.
The command line arguments were:
latex2html -split 0 -white -html_version 4.0 -dir latex2html -show_section_numbers -local_icons -no_navigation main.tex
The translation was initiated by Diwaker Gupta on 2008-10-03
![\includegraphics[height=1.6in]{figures/de-initial-mapping.eps}](img1.png)
![\includegraphics[height=1.6in]{figures/de-sharing}](img2.png)
![\includegraphics[height=1.6in]{figures/de-patching}](img3.png)
![\includegraphics[height=1.6in]{figures/de-compression}](img4.png)
![\includegraphics[width=2in]{figures/swap-arch.eps}](img14.png)
![\includegraphics[width=2.15in]{figures/dewg-de_mode-S-identical.eps}](img19.png)
![\includegraphics[width=2.15in]{figures/dewg-de_mode-P-identical.eps}](img20.png)
![\includegraphics[width=2.15in]{figures/dewg-de_mode-C-identical.eps}](img21.png)
![\includegraphics[width=2.15in]{figures/dewg-de_mode-S-random.eps}](img22.png)
![\includegraphics[width=2.15in]{figures/dewg-de_mode-P-random.eps}](img23.png)
![\includegraphics[width=2.15in]{figures/dewg-de_mode-C-random.eps}](img24.png)
![\includegraphics[width=2.15in]{figures/dewg-de_mode-S-similar95.eps}](img25.png)
![\includegraphics[width=2.15in]{figures/dewg-de_mode-P-similar95.eps}](img26.png)
![\includegraphics[width=2.15in]{figures/dewg-de_mode-C-similar95.eps}](img27.png)
![\includegraphics[width=2.15in]{figures/rubis-2007-11-20-sysnet129-x3-clients100-lru100-timer20-de_mode-requests}](img28.png)
![\includegraphics[width=2.15in]{figures/rubis-2007-11-20-sysnet129-x3-clients100-lru100-timer20-de_mode-rtimes}](img29.png)
![\includegraphics[width=2.15in]{figures/rubis-2007-11-20-sysnet129-x3-clients100-lru100-timer20-de_mode-savings}](img30.png)
![\includegraphics[width=2.8in]{figures/wdr-rubis-final-requests.eps}](img34.png)
![\includegraphics[width=2.8in]{figures/wdr-rubis-final-rtimes.eps}](img35.png)