Francis M. David, Ellick M. Chan, Jeffrey C. Carlyle, Roy H. Campbell
University of Illinois at Urbana-Champaign
{fdavid,emchan,jcarlyle,rhc}@illinois.edu
In the past, designs for reliable computer systems have used redundancy in hardware and OS software to attempt recovery from errors [5,6]. Redundancy can mask transient and permanent hardware faults as well as some software faults [4]. However, it does not address the insidious problem of the propagation of undetected errors [34]. Additionally, these systems are extremely expensive to build and use [44].
Errors in a monolithic OS can easily propagate and corrupt other parts of the system [22,52], making recovery extremely difficult. Microkernel designs componentize the OS into servers managed by a minimal kernel. These servers provide functionality such as the file system, networking and timers. User applications and other OS components are modeled as clients of these servers. Inter-component error propagation is significantly reduced because, in many microkernel designs, servers usually execute in their own restricted address spaces similar to user processes [25,37].
Recovery from a microkernel server failure is typically attempted by restarting it. The intuition behind this approach is that reinitializing data structures from scratch by restarting a server usually fixes a transient fault. This is similar to microrebooting [10]. In Minix3 [25], for example, server restarts are performed by the Reincarnation Server [47]. If the server managing a printer crashes, it causes a temporary unavailability of the printer until it is restarted. Unfortunately, this approach to recovery does not always work. Many OS services maintain state related to clients. In such cases, a server restart results in the loss of this state information and affects all clients that depend on the server. For example, a failure of the file system server in Minix3 impacts all clients that were using the file system. Simply restarting the file system server does not prevent errors from occurring in these existing clients. Reads and writes to existing open files cannot be completed because the restarted server cannot recognize the file handles that are presented to it. Thus, while stateless servers such as some device drivers can be restarted to recover the system, this technique is not applicable for many important OS services that manage client-related state.
Writing clients to take into account OS service restarts and state loss is a possible solution. This requires clients to subscribe to server failure notifications and can result in increased code complexity. Another possible solution is to provide some form of persistence to the server's client-related state information. This allows a restarted server to continue processing requests from existing clients. Some microkernel operating systems like Chorus and Minix3 support the ability to persist state in memory through restarts; but they do not use this functionality for OS servers and, currently, only provide it as a service for user applications or device drivers.
Attempts to solve the state loss problem by simply persisting server state across a restart do not address the possible corruption of this state due to error propagation. An error that occurs in an OS server, like a typical software error, can potentially corrupt any part of its state [27] before being detected. This highlights yet another significant limitation of traditional microkernel systems. While such systems minimize inter-component error propagation, nothing prevents intra-component error propagation.
Checkpointing OS service state in order to mitigate the effects of error propagation is not a viable solution because rolling back to a consistent system state requires checkpointing of client state as well. Additionally, multiple checkpoints may have to be maintained in order to avoid rolling back to an incorrect state. This may be expensive in terms of memory and performance.
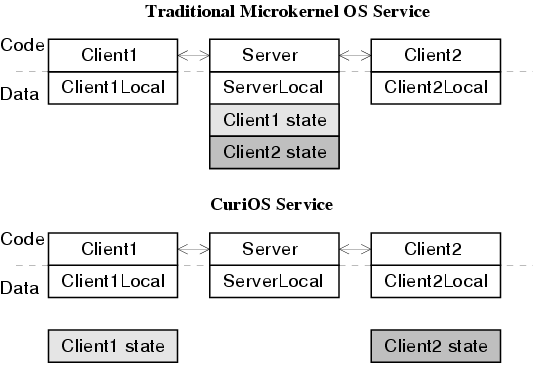
In this paper, we present CuriOS, which adopts an approach that significantly minimizes error propagation between as well as within OS services and recovers failed services transparently to clients. We accomplish this by lightweight distribution, isolation and persistence of client-specific state information used by OS servers. Client-specific state is stored in client-associated, but client-inaccessible memory and servers are only granted access to this information when servicing a request. Because this state is not associated with the server, it persists after a server restart. This distribution of state is illustrated in figure 1. A server failure that occurs when servicing a client can only affect that client and the restarted server can continue to process other requests normally.
Distribution of state information from servers to clients for fault tolerance is not new. Researchers have exploited this technique to improve the reliability of file system services in distributed operating systems such as Sprite [53] and Chorus/MiX [33]. A more widely known example is Sun's stateless Network File System (NFS) [41]. But these designs do not protect the state information from being manipulated by clients and leads to various security problems such as those with NFS [51,32]. Our design supports safe distribution of state by protecting the state from modification by clients. Our implementation is also lightweight because we use virtual memory remapping instead of memory copying to grant access to state. Additionally, we provide a generic framework for implementing distributed state and recovery for any OS service, not just the file system.
CuriOS is written in C++ and is based on the Choices object-oriented operating system [8]. It is being developed to provide a highly reliable OS environment for mobile devices such as cellular phones powered by an ARM processor.
Our work is complementary to other research in OS error detection such as the language-based type-safety techniques used in SafeDrive [55] and software guards used in the XFI system [50]. Employing such techniques in CuriOS can improve error detection latency and further reduce error propagation.
A preliminary design for CuriOS is available in a previous publication [18]. The contributions of this paper include:
The remainder of this paper is organized as follows. We investigate several related operating systems in Section 2. In Section 3, we look at the results of our investigations and present our observations for an operating system design that supports transparent recovery. Section 4 presents a brief introduction to the CuriOS architecture and details the framework used to manage OS service state information. Section 5 describes the design and implementation of a few transparently restartable CuriOS components and drivers. We present an evaluation of several aspects of our current implementation in 6. We discuss a number of additional related topics in Section 7 and conclude in Section 8. In this paper, we limit our scope to the reliability aspects of CuriOS. A short discussion of some security issues is available in Section 7.
The dependability related terms used in this paper conform to the taxonomy suggested by Avizienis et al [3]. All names that use the font Class represent C++ classes.
Some microkernel operating systems that are closely related to our work are Minix3 [25], L4 [37], Chorus [40] and EROS [43]. For the evaluation of each of these microkernel-based operating systems, we manually inject memory access errors into different OS servers to explore the effect of an OS error on its reliability. A memory access error is the typical manifestation of a hardware or software fault in an OS [52].
| Failed Server | Immediate Effect | After Restart | |
| Minix3 | File System (fs) | System unusable. | Server is not restarted because the Reincarnation Server depends on the file system. Also, all current file system state information is lost. |
| Network (inet) | All existing network connections fail. | Restart does not help re-establish connections because state information is lost. | |
| Random Numbers (random) |
Temporary read failure. | Once the server is restarted, client reads begin working again. | |
| Printer Driver (printer) | Temporary printer access failure. | Print job completes successfully after spooler retries request to the restarted printer server. | |
| L4 | Timer (ig_timer) | System unusable. | All clients stop receiving timer interrupts. Restart does not help because clients waiting on interrupts can't re-register. |
| Name Server (ig_naming) | No immediate effect. | But many critical services inaccessible because lookup of registered names fail. Restart does not help because all registered clients need to re-register. | |
| Serial (ig_serial) | Serial port inaccessible. | Request retries will eventually work. | |
| Chorus | File System (vfs) | System unusable. | Restart does not help because file system state information is lost. |
| Network (netinet) | System unusable. | Restart does not help recover existing network connections. | |
| Timer (kern) | System unusable. | Restart does not address clients waiting on timeout. | |
| EROS | Memory allocator (spacebank) |
System unusable. | Restore from a previous checkpoint may fix this error. |
| Process Creator | System cannot create new processes. | Restore from a previous checkpoint may fix this error. |
In all our experiments, a memory access error results in the termination of the OS server. Table 1 shows the results of our experiments. The effect of server termination after encountering the memory access error is shown in the third column. The last column presents our analysis of whether a restarted server will continue serving existing clients correctly (if restartability support were included in the corresponding OS). Except for Minix3, which already implements restartable services, this observation is based purely on source code analysis. Brief explanations for our conclusions are provided in each row. The entries in the last column for Minix3 are actual experimental results.
The rest of this Section discusses reliability aspects of the previously mentioned systems and several other related operating systems in more detail.
Minix3 includes a data store server that can be used to store state that persists after a failure induced restart. The Minix3 data store provides some protection from errors in a server because it resides in a separate address space from the server. It has been used to implement failure resilience for device drivers [26]. A drawback of the data store approach is the additional communication and data copying overhead involved. This approach also does not restrict intra-component error propagation.
More complex functionality such as a file system is part of the L4Linux [23] suite, which implements a complete Linux system as a user-mode server. Since most of the functionality required by Linux applications is implemented in this server, the reliability of all L4Linux applications depends on the reliability of this server, and thus, this design is not any more reliable than the normal monolithic Linux OS. This has been improved to some extent by isolating device drivers in separate virtual L4Linux servers [36].
The Singularity system [28] adopts a radically different approach to security and reliability by using software enforcement of address spaces. CuriOS relies on hardware support to enforce memory protection.
From our study of the operating systems in the previous Section, we are able to
make several observations about how the design of an operating system can impact its
ability to transparently recover in the event of the failure and restart of an OS service.
Transparency of addressing:
Clients should be able to use the same address to access the OS service after it is restarted.
In EROS, since the whole system is restored to a previous checkpoint, this property is true.
This is not supported by Chorus, whose hot restart algorithm restarts servers with
a new address. Nor is this supported by L4 or Minix3 since a restarted server would
be assigned a different address. A name server can be used to ameliorate this problem by
maintaining a consistent name for the server across a restart. The restarted server would
register its new address with the name server to provide continued availability.
Minix3 achieves transparency of addressing to some degree by using the file
system server as a name server. A server can register itself as the handler
for a device entry on the file system. For instance, the Minix3 random server
mentioned in table 1 handles requests for the
/dev/random file system entry. In our experiment, we opened
/dev/random using the open system call and used the
returned file handle to read a stream of random numbers from the server. If the
random server crashed, reads using this file handle failed; however, once the
server was restarted, reads using the same handle began
to work once again.
Suspension of clients for duration of recovery:
Clients should not time out or initiate new requests during the recovery phase.
This property is supported by Chorus. In Minix3, clients are allowed to run when the
server is restarting, and this results in errors when a client attempts to
communicate with it. This is also the case in L4; the client will receive
an error when it tries to communicate with a server that may be restarting.
The whole system is restored to a previous checkpoint in EROS and therefore,
this property is not applicable.
Persistence of client-related state:
When a service is restarted, requests from clients must not fail because the server lost
client-related state. Client-related state must be preserved and made available to
the restarted server. Chorus and Minix3 have some
support for in-memory state preservation, but this is not exploited by
any of the OS services they support. An alternative is to save this information
to stable storage. In EROS, all computation since the last saved checkpoint is lost.
Isolation of client-related state:
Designs of existing microkernel operating systems provide unrestricted access to client-related state
within a server. An error that occurs in the server can potentially corrupt state
related to all clients. This intra-component error propagation problem exists in a large number
of important microkernel OS services. In EROS, error propagation may lead
to inconsistent data being checkpointed.
In the next Section, we describe how CuriOS fulfills all of these requirements
and enables transparently-restartable OS components.
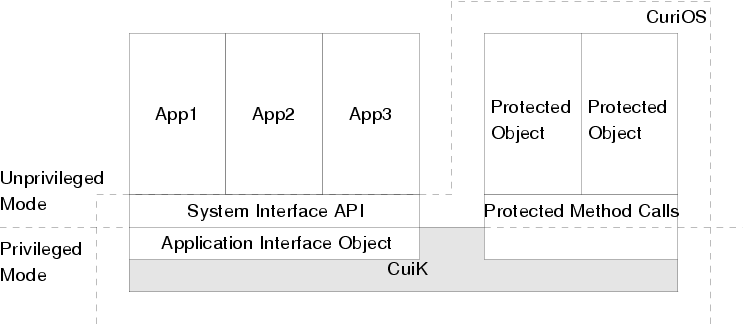
A protected object in CuriOS is analogous to a ``server'' in a traditional microkernel system. Our implementation of protected objects on the ARM platform only enforces restrictions on memory access. Implementations of protected objects on other platforms such as the x86 can additionally exploit architectural features to provide access control for other resources such as IO ports.
Protected objects work together with a small kernel, known as CuiK, in order to provide standard OS services as shown in figure 2. CuiK is a thin layer of the OS that runs with the highest privileges. It is composed of a small set of objects that manage low level architecture specific functionality such as interrupt dispatching and context switching. Communication between protected objects is managed by CuiK.
CuiK uses protected method calls to invoke operations on protected objects. Each protected object is assigned a private heap. A private stack is reserved for every thread that accesses the protected object. This stack is allocated at the first invocation of a protected method, contributing to a small delay in processing the first call to a protected object. Subsequent invocations of protected methods on the same protected object by the same thread reuse this stack. A protected method call results in a switch to a reduced privilege execution mode and constrained access rights to memory. The private stack and the heap are mapped in with read-write privileges. The rest of CuriOS is mapped in with read-only privileges. Permissions to write to any additional memory has to be explicitly granted by CuiK.
Our current implementation of protected method calls uses a wrapper object that intercepts method calls to a protected object and manages memory access control, processor mode switching and recovery. The combination of protected objects and CuiK results in a single address space operating system [11], where virtual addresses are identical across various components, but access permissions differ.
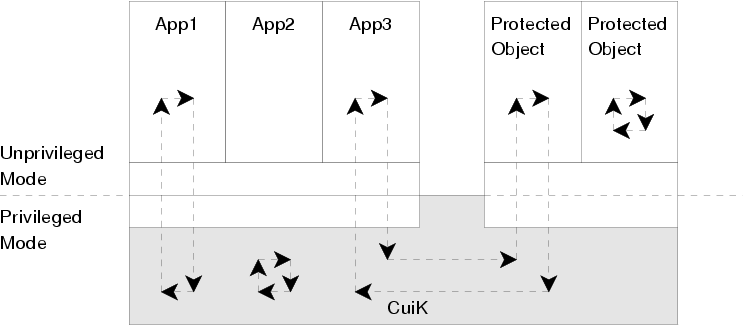
Threads in CuriOS are managed by CuiK. Using defined interfaces, a thread executing in CuriOS can cross user-space application, kernel, and protected object boundaries. For example, a system call in an application causes the thread to cross from user-space into the CuiK kernel. This same thread can cross from CuiK into a protected object using a protected method call. Some example threads are illustrated in figure 3.
CuriOS is written in C++ and uses object-oriented techniques to minimize code duplication and improve portability. Wrapper classes, for example, inherit from a common base class that provides the support functions used to switch protection domains and manage private heaps and stacks. In our current implementation, wrapper classes use multiple inheritance and also inherit from the class representing the object being wrapped. This allows the wrapper to exploit polymorphism and substitute the protected object anywhere in the system.
C++ exception handling is used as the error signaling mechanism in CuriOS [17]. Exceptions are raised for both processor signaled errors such as invalid memory accesses and for externally signaled errors such as OS infinite loop lockups (signaled by a watchdog timer) [16].
Exceptions are raised when errors are detected while executing code within a protected object. Exceptions that are not handled within the object are intercepted at the wrapper which attempts to destroy and re-create the protected object. The wrapper maintains a copy of the constructor arguments (if any) in order to re-create the protected object. This is similar to microrebooting or server restarts in Minix3 and can be used to fix transient hardware or software faults. The protected object is re-created in-place in memory ensuring that external references to it remain valid. This provides transparency of addressing. The method call is immediately retried on the newly constructed protected object. Multiple retry failures cause an exception to be returned to the caller. All normal system activity is suspended until the recovery is completed. Thus clients are suspended for the duration of recovery.
A server that needs to maintain state information about clients uses state management functionality provided by CuiK to distribute, isolate, and persist client-related state. Servers that are completely stateless can be easily restarted and do not require this functionality.
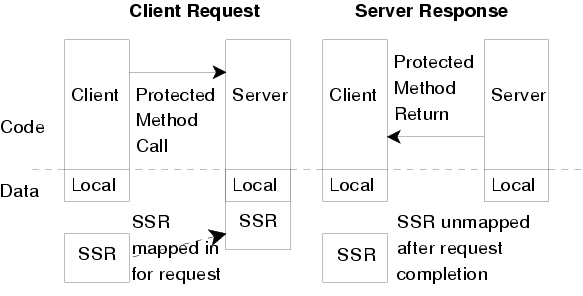
A Server State Region (SSR) is an object representing a region of memory that is allocated to store an OS server's client-related information. An SSR is created when a client establishes a connection to the server. For accounting purposes, the memory associated with the SSR is charged to the client. SSRs are protected from both the server and the client through hardware-supported virtual memory protection mechanisms. A client is never granted access to its SSR. A server is only granted write access to a client's SSR when it is processing a request from that client (see figure 4). The SSR is passed as an argument to the server's protected method call. The server can then use the SSR to store client-related information. It has full control over management of the memory within the SSR. Write permissions to the SSR are revoked when the protected method call returns. SSRs are implemented using a C++ object that holds a pointer to a hardware-protectable region of memory.
All SSRs in CuriOS are managed by a singleton object called the SSRManager. The SSRManager provides the functions used to register a new server, bind a client to a server (resulting in the creation of an SSR), undo a client-server binding (deletion of the associated SSR) and enumerate all the SSRs associated with a server. Each server using SSRs is required to provide a recovery routine that is invoked immediately after the server object is re-created upon a failure. This routine can query the SSRManager to obtain all associated SSRs in order to re-create the internal state of the restarted server.
The SSR-based state management framework provides persistence and isolation of client-related state.
The second type is a server that requires knowledge about all of its clients in order to service a request. Examples of this type are OS services like the scheduler and timer managers. Such servers can store client related information in SSRs and can redundantly cache this information locally to process requests. Upon a restart, such a server should be able to re-create its internal state from its distributed SSRs.
Many CuriOS components and drivers are stateless or structured as one of these two types of servers. When restarting, the server's recovery routine re-creates internal state from all SSRs. It is possible that the SSR that was in use at the time an error occurs is corrupted. The recovery routine can check the consistency of the objects in SSRs using simple heuristics before using them. CuriOS uses magic numbers in objects and these can be checked for corruption. We also use server-specific checks to ensure that pointers and numbers are within expected ranges. Unlike EROS which does consistency checks of all state during normal running time, these SSR consistency checks in CuriOS are only performed on exceptional conditions that require server recovery.
CuriOS servers can be multi-threaded and our current implementation shares the same virtual memory mappings for all threads. Thus, it is possible that multiple SSRs are mapped in when an error occurs. In this case, the error propagation is limited to the SSRs that are currently mapped in. This can be further improved by including support for thread-level protection.
Restarting a service that has visible external effects may not always result in correct behavior. For example, restarting a printer driver due to a failure may cause another copy of the print job to be dispatched. This problem may be ameliorated to some degree by writing code that is restart-aware. This is achieved by incorporating some means of recording the progress made in servicing a request. This limitation has also been acknowledged for device driver restarts in Minix3 [26]. Similar to the approach taken by Minix3, we advocate notification of possible non-transparent recovery to applications or users.
Each SSR is associated with a client Socket object and is mapped into the TCP PO's address space when interacting with it. When there is an incoming packet, the corresponding SSR is located and mapped in before sending it through the stack. A similar approach is used to provide access to SSRs for the TCP PO's timer driven events.
All the assert code in LWIP was converted to throw exceptions instead of halting
the stack. This comprehensive error detection in LWIP helps reduce error propagation and
improves recovery rates.
File Systems:
CuriOS currently supports two different file systems.
CramFSFileObject is a class that provides access to a compressed
file on the read-only CramFS file system [14]. When a file is opened, an instance
of this class is created as a PO. This instance only has
information about its backing storage and does not maintain any state regarding
clients. Hence it does not require usage of the server state management
functionality. The method call to read a file provides both the offset into the file
and the required number of bytes. The PO is only granted privileges to modify
its own data and the destination buffer. Calls to other objects like the
backing storage are mediated by CuiK. Using a PO for each file has several
reliability benefits. An error that occurs when processing one file is contained
within the PO and cannot corrupt arbitrary memory in the system. If the error were
transient, a restarted PO can continue serving clients. If there is an error in a
compressed file stored on the disk that causes the
decompression routines to fail, it only causes an error in the clients that were reading
that particular file.
CuriOS also includes support for the Linux ext2 file system. An Ext2Container PO is created for every ext2 file system on disk. This manages the inode and free space bitmaps. If this PO crashes and restarts, it can re-read this information from disk. An Ext2Inode PO is tasked with managing all interaction with a file. This PO only has privileges to modify the inode it represents, which, in turn, has all the pointers to disk blocks comprising the file. This has similar reliability benefits as the CramFSFileObject protected object. Since POs are re-created in-place, the same objects can be used to access the file after the service is restarted.
It is important to realize that when we refer to file system service recovery, we are
not dealing with recovering corrupted file system state on disk. There are many other programs
that are designed to handle corrupted data on disk and this is an orthogonal problem with
recovering the state information maintained in a live file system server.
Device Drivers:
The serial port driver in CuriOS is implemented as a PO with complete
access to the memory mapped registers of the serial port controller. This PO is stateless
and only has one client: the CuriOS console object. Errors that occur when reading
or writing to the serial port are handled by restarting this PO and retrying the request.
CuriOS has a NOR flash driver that is implemented as a stateless
PO. This PO is created with read/write access rights to physical memory regions that
map to NOR flash chips. An error that occurs in this PO can lead to potential corruption
of arbitrary data stored in NOR flash, but cannot easily corrupt read-only mapped
system memory. Protected objects are also used to encapsulate
drivers for interacting with the hardware timers. These are used to start,
query and stop the hardware timers. Interrupts from the hardware timers are also dispatched to them.
These are currently stateless and can be restarted. The PeriodicTimerManager
service depends on the correct functioning of these driver objects.
Our fault injection tool is used to inject two types of faults. The first type of fault is a memory access fault (an ARM processor ``data abort''). These virtual memory faults are instantaneously detected at the injected instruction and immediately cause an error. The fault latency is zero in this case and error propagation is limited. The other type of fault that we inject is a register bit-flip. The tool randomly flips a bit in one of the register operands for the selected instruction. Register bit-flips do not always lead to errors (a corrupted register can be overwritten). They can, however, lead to latent errors which may not be detected immediately. This has been used to emulate several common programming errors such as incorrect assignment statements and pointer corruptions [38]. After recovery, we terminate experiments once we are able to verify that the OS is still functional (ability to schedule processes and access the disk).
We present error recovery results for the timer manager, system scheduler, networking stack
and file system. In all of our experiments, we
consider the system to be usable and successfully recovered if, at the
end of the experiment, CuriOS can schedule new processes and can access the disk.
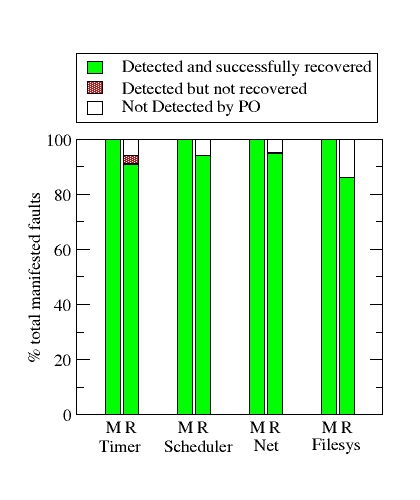
We perform between 250 and 600 fault injection experiments per server and the results are shown in
figure 5. The ``M'' columns present results for the memory access fault
experiments and the ``R'' columns present results for the register bit-flip experiments.
The Y axis represents the percentage of faults
that had some visible manifestation (errors). Note that all of these manifested
faults would result in a service or system failure in most existing operating systems,
which do not implement restart recovery with state management as used in CuriOS.
An error is reported as successfully recovered if the system is usable after
recovery. In some cases, a client's connection to a server is terminated because
of a corrupted SSR or repeated errors while the system, as well as other clients
using the restarted service, still remain usable. We
count such cases as successful system recovery in the figure shown. In the
face of arbitrary errors that corrupt a client's SSR or request, there is no
possibility of maintaining the unfortunate client's connection.
Timer Manager: This experiment is set up
so that a couple of processes that use the timer are started before
faults are injected into the server. These are applications like
a clock that displays the time of day. While the
memory abort errors are fully recovered by reconstructing the internal
timer queue, in the register bit-flip injections we see a few cases (3%)
where errors are detected but are not recovered. These happen when
the recovery procedure itself encounters an error and is unable to
complete. We are working on eliminating such cases by improving
the robustness of the recovery routines. 6% of the register-bit
flips evade detection by the protected object mechanism and cause
unrecoverable errors in other parts of CuriOS.
This is because register bit-flip errors can propagate to other
CuriOS subsystems through invalid method call arguments and results.
We do not yet perform an exhaustive check of the validity of all
method call arguments and results. This is a work in progress and
we expect it to significantly reduce this inter-component error propagation.
System Scheduler: This experiment is set up similar
to the timer manager experiment with several processes in the system.
The goal of this experiment is to examine if a failure in the scheduler
can be recovered and if CuiK can continue scheduling processes.
For the memory abort experiments, re-creation of the internal linked list
is always successful. In the case of the register bit-flip experiments,
6% of the errors are not detected by the PO mechanism and cause CuriOS
to crash.
Network: We run a simple web server and an echo server
in CuriOS while also running an HTTP client that fetches a half-megabyte file
from an external host. Faults are injected into the LWIP code for TCP
processing of IP packets on both the send and receive paths. If an error
is detected, the TCP stack PO is restarted and the request is retried. If
multiple attempts at executing a protected method fail, an exception is thrown.
If this exception is thrown when processing an incoming IP packet, the
packet is silently dropped by the IP layer. This has no effect on the
correctness of TCP because this is similar to packet loss on the network
and is recovered by the TCP stack. If an exception is thrown back to
a client with a TCP connection handle, the TCP connection for that client
is terminated. We verify that the network stack is still usable and other
connections are unaffected in spite of a single connection failure.
For the network stack, 5% of the manifested register-bit flip faults
are not detected and consequently, not recovered. While the system is
recovered in 95% of the cases, 45% of these recoveries were at the
cost of a single client's TCP connection termination due to state
corruption.
File System: We inject faults into the code for the ext2
file system that is used when accessing a file on disk (in Ext2Inode).
The memory abort faults are always completely recovered after a retry. 13% of
the manifested register bit-flip faults are not detected by the protected
object mechanism and are therefore not recovered. Again, this is due
to error propagation via corrupted method call arguments and results.
| Protected Call | Instruction | Time Overhead |
|---|---|---|
| Overhead | (microseconds) | |
| Without SSR | ||
| With SSR |
Apart from the extra code implementing the protected object mechanism, a major source of overhead is the need to flush the TLB when switching between page tables. While the ARM architecture allows for selective flushing of TLB entries, our current implementation does not support this feature. The single address space design of CuriOS helps to keep the costs of protected method calls down by obviating the need to flush the virtually tagged caches on the OMAP1610 ARM processor.
How fast does recovery happen? When an error is detected, the exception handling framework signals the error and the C++ library unwinds the stack and destroys stack objects. Restarting the server requires re-running the constructor for the PO and code to recover information from SSRs (if required). Altogether, the time from error detection to a recovered system is usually on the order of a few hundred microseconds.
VINO [42] used transactions to roll-back changes made by misbehaving kernel extensions. We have also investigated the use of software transactional memory techniques to protect component state in Choices [15]. The use of transactional semantics alone to recover complete component state is only effective when errors are detected before commits. When this property cannot be enforced, there are no constraints on error propagation within the component. However, when used together with our SSR-based approach that reduces error propagation, transactions can provide an additional layer of protection to SSRs while they are being manipulated by a service.
In addition to some of the operating systems discussed in Section 2, many other system designs incorporate virtual memory protection to improve reliability. In the Rio project [12], virtual memory was used to protect the file cache from corruption by errors occurring elsewhere in the system. The protected object concept is similar to a virtual memory protected region in Nooks [46]. However, unlike Nooks, a protected object executes in an unprivileged processor mode. More importantly, while Nooks is designed to wrap OS extensions such as device drivers, a protected object can encapsulate core OS components. Unlike the shadow driver mechanism [45] used by Nooks, the SSR-based recovery mechanisms can isolate requests that cause crashes because of a software bug and continue servicing requests that do not trigger the bug. This is possible because of the rigorous partitioning of per-client state in CuriOS. When using the shadow driver approach, the bug will be triggered in the shadow driver just as it was in the original driver since the same code is used.
OS service design using SSRs is closely related to the principle of crash-only software [9]. Similar to crash-only components, recovery involves a component restart and component crashes are masked from end users using transparent component-level retries.
The source code for our CuriOS implementation and the code for the QEMU-based fault injector can be found on our website at https://choices.cs.uiuc.edu/.