OSDI '06 Paper
Pp. 177–190 of the Proceedings
HQ Replication: A Hybrid Quorum Protocol for Byzantine Fault Tolerance
James Cowling1, Daniel Myers1, Barbara Liskov1, Rodrigo Rodrigues2, and Liuba Shrira3
1MIT CSAIL,
2INESC-ID and Instituto Superior Técnico,
3Brandeis University
{cowling, dsm, liskov, rodrigo, liuba}@csail.mit.edu
|
Abstract
There are currently two approaches to
providing Byzantine-fault-tolerant state machine
replication: a replica-based approach, e.g., BFT,
that uses communication between replicas to agree on
a proposed ordering of requests, and a quorum-based approach, such as Q/U, in
which clients contact replicas directly to optimistically execute
operations. Both approaches have shortcomings: the
quadratic cost of inter-replica communication is unnecessary when
there is no contention, and Q/U requires a large number of replicas and
performs poorly under contention.
We present HQ, a hybrid Byzantine-fault-tolerant state machine
replication protocol that overcomes these problems. HQ employs a
lightweight quorum-based protocol when there is no contention, but
uses BFT to resolve contention when it arises. Furthermore,
HQ uses only 3f+1 replicas to tolerate f faults, providing optimal
resilience to node failures.
We implemented a prototype of HQ, and we compare its
performance to BFT and Q/U
analytically and experimentally. Additionally, in this
work we use a new implementation of BFT designed to scale as the
number of faults increases. Our results show that both HQ and our
new implementation of BFT scale as f increases;
additionally our hybrid approach of using BFT to handle contention
works well.
1 Introduction
Byzantine fault tolerance enhances the availability and reliability of
replicated services in which faulty nodes may behave arbitrarily. In
particular, state machine replication
protocols [9, 19] that tolerate Byzantine faults
allow for the replication of any deterministic service.
Initial proposals for Byzantine-fault-tolerant state machine
replication [18, 2] relied on all-to-all
communication among replicas to agree on the order
in which to execute operations. This can pose a scalability problem
as the number of faults tolerated by the system (and thus the number
of replicas) increases.
In their recent paper describing the Q/U protocol [1],
Abd-El-Malek et al. note this weakness of agreement approaches and
show how to adapt Byzantine quorum protocols, which had previously
been mostly limited to a restricted read/write
interface [12], to implement Byzantine-fault-tolerant
state machine replication. This is achieved through a client-directed
process that requires one round of communication between the client
and the replicas when there is no contention and no failures.
However, Q/U has two
shortcomings that prevent the full benefit of quorum-based systems
from being realized. First, it requires a large number
of replicas: 5f+1 are needed to tolerate f failures, considerably
higher than the theoretical minimum of 3f+1. This increase in the
replica set size not only places additional requirements on the number
of physical machines and the interconnection fabric, but it also
increases the number of possible points of failure in the system.
Second, Q/U performs poorly when there is contention among concurrent
write operations: it resorts to exponential back-off to resolve contention,
leading to greatly reduced throughput. Performance under write contention
is of particular concern, given that such workloads are generated by many
applications of interest (e.g. transactional systems).
This paper presents the Hybrid Quorum (HQ) replication protocol, a new
quorum-based protocol for Byzantine fault tolerant systems that
overcomes these limitations. HQ requires only 3f+1 replicas and
combines quorum and agreement-based state machine replication
techniques to provide scalable performance as f increases. In the
absence of contention, HQ uses a new, lightweight Byzantine quorum
protocol in which reads require one round trip of communication
between the client and the replicas, and writes require two round
trips. When contention occurs, it uses the BFT state machine
replication algorithm [2] to efficiently order the
contending operations. A further point is that, like
Q/U and BFT, HQ handles Byzantine clients as well as
servers.
The paper additionally presents a new implementation of BFT.
The original implementation of BFT [2] was designed
to work well at small f; our new implementation is designed
to scale as f grows.
The paper presents analytic results for HQ, Q/U, and BFT,
and performance results for HQ and BFT. Our results indicate
that both HQ and the new implementation of BFT
scale acceptably in the region studied (up to f=5)
and that our approach to resolving contention provides a gradual
degradation in performance as contention rises.
The paper is organized as follows. Section 2 describes
our assumptions about the replicas and the network connecting
them. Section 3 describes HQ, while
Section 4 describes a number of optimizations and
our new implementation of BFT.
Section 5 presents analytic results for
HQ, BFT, and Q/U performance in the absence of contention,
and Section 6
provides performance results for
HQ and BFT under various
workloads. Section 7 discusses related work, and
we conclude in
Section 8.
2 Model
The system consists of a set C = { c1, ..., cn} of client
processes and a set R = { r1, ..., r3f+1} of
server processes (or replicas).
Client and server processes are classified as either
correct or faulty. Correct processes are constrained to obey their
specification, i.e., they follow the prescribed algorithms. Faulty
processes may deviate arbitrarily from their specification: we
assume a Byzantine failure model [8]. Note
that faulty processes include those that fail benignly as well as
those suffering from Byzantine failures.
We assume an asynchronous distributed system where nodes are connected
by a network that may fail to deliver messages, delay them, duplicate
them, corrupt them, or deliver them out of order, and there are no known
bounds on message delays or on the time to execute operations. We
assume the network is fully connected, i.e., given a node identifier,
any other node can (attempt to) contact the former directly
by sending it a message.
For liveness, we require only that if a client keeps retransmitting
a request to a correct server, the reply to that request will
eventually be received, plus the conditions required
for liveness of the BFT algorithm [2] that we use
as a separate module.
We assume nodes can use unforgeable digital signatures to authenticate
communication. We denote message m signed by node n as ⟨
m⟩σn. No node can send ⟨ m⟩σn
(either directly or as part of another message) on the network for any
value of m, unless it is repeating a message that has been sent
before or it knows n's private key. We discuss how to avoid the use
of computationally expensive digital signatures in
Section 3.3. Message Authentication Codes (MACs) are used to
establish secure communication between pairs of nodes, with the
notation ⟨ m⟩μxy indicating a message
authenticated using the symmetric key shared by x and y. We assume
a trusted key distribution mechanism that provides each
node with the public key of any other node in the system, thus allowing
establishment of symmetric session keys for use in MACs.
We assume the existence of a collision-resistant hash function,
h, such that any node can compute a digest h(m) of message m
and it is impossible to find two distinct
messages m and m' such that h(m) = h(m').
To avoid replay attacks we tag certain messages with nonces that are
signed in replies. We assume that when
clients pick nonces they will not choose a repeated value.
3 HQ Replication
HQ is a state machine replication protocol that can handle arbitrary
(deterministic) operations. We classify operations as reads
and writes. (Note that the operations are not restricted to
simple reads or writes of portions of the service state; the distinction
made here is that read operations do not modify the service state whereas
write operations do.) In the normal case of no failures and no
contention, write operations require two phases to complete
(we call the phases write-1 and write-2) while
reads require just one phase. Each phase consists of the client
issuing an RPC call to all replicas and collecting a quorum of replies.
The HQ protocol requires 3f+1 replicas to survive f failures and
uses quorums of size 2f+1.
It makes use of certificates to ensure that write operations are
properly ordered. A certificate is a quorum of authenticated messages
from different replicas all vouching for some fact. The purpose of
the write-1 phase is to obtain a timestamp that determines
the ordering of this write relative to others. Successful completion
of this phase provides the client with a certificate proving that it
can execute its operation at timestamp t. The client then
uses this certificate to convince replicas to execute its operation at this
timestamp in the write-2 phase. A write concludes when
2f+1 replicas have processed the write-2 phase request, and
the client has collected the respective replies.
In the absence of contention, a client will obtain a usable
certificate at the end of the write-1 phase and succeed in executing
the write-2 phase. Progress is ensured in the presence of slow or
failed clients by the writeBackWrite and writeBackRead operations,
allowing other clients to complete phase 2 on their behalf. When
there contention exists, however, a client may
not obtain a usable write certificate, and in this case it asks the system to
resolve the contention for the timestamp in question. Our
contention resolution process uses BFT to order the
contending operations. It guarantees
-
if the write-2
phase completed for an operation o at timestamp t, o will
continue to be assigned to t.
- if some client has
obtained a certificate to run o at t, but o has not
yet completed, o will run at some timestamp ≥ t.
In the second case it is
possible that some replicas have already acted on the write-2 request
to run o at t and as a result of contention resolution, they may
need to undo that activity (since o has been assigned a different
timestamp). Therefore all replicas maintain a single backup state so
that they can undo the last write they executed. However, this undo
is not visible to end users, since they receive results only
when the write-2 phase
has completed, and in this case the operation retains its timestamp.
3.1 System Architecture
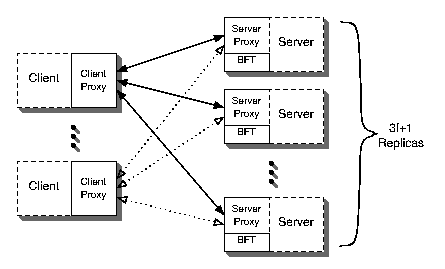
The system architecture is illustrated in Figure 1. Our
code runs as proxies on the client and server machines: the
application code at the client calls an operation on the client proxy, while
the server code is invoked by the server proxy in response to
client requests. The server code maintains replica state; it performs
application operations and must
also be able to undo the most recently received (but not yet
completed) operation (to handle
reordering in the presence of contention).
The replicas also run the BFT state machine replication protocol [2],
which they use to resolve contention; note that BFT is not involved
in the absence of contention.
Figure 1: System Architecture
3.2 Normal Case
We now present the details of our protocol for the case where there is
no need to resolve contention; Section 3.3 describes
contention resolution. We present an unoptimized version of the
protocol; optimizations are discusses in Section 4.
The system supports multiple objects. For now we assume that each
operation concerns a single object; we discuss how to extend this
to multi-object transactions in Section 3.6. Writers are
allowed to modify different objects in parallel but are restricted to
having only one operation outstanding on a particular object at a
time. Writers number their requests on individual objects
sequentially, which allows us to avoid executing modification
operations more than once. A writer can query the system for
information about its most recent write at any time.
A write certificate contains a quorum of grants, each of form
⟨cid, oid, op#, hop, vs, ts,
rid⟩σr, where each grant is signed by its
replica r with id rid. A grant states that the replica has
granted the client with id cid the right to run the operation
numbered op# whose hash is hop on object oid at timestamp
ts. A write certificate is valid if all the grants are from
different replicas, are correctly authenticated, and are otherwise
identical. We use the notation c.cid, c.ts, etc., to
denote the corresponding components of write certificate c. The
vs component is a viewstamp; it tracks the running of BFT to
perform contention resolution. A certificate C1 is later than
certificate C2 if C1's viewstamp or timestamp is larger than that
of C2. (A viewstamp is a pair consisting of the current BFT view
number, plus the number assigned by BFT to the operation it executed
most recently, with the obvious ordering.)
3.2.1 Processing at the Client
Write Protocol.
As mentioned, writing is performed in two phases. In the first phase
the writer obtains a certificate that allows it to execute
the operation at a particular timestamp in the second phase.
Write-1 phase.
The client sends a ⟨write-1, cid, oid, op#,
op⟩σc request to the replicas. The following replies
are possible:
-
⟨write-1-ok, grantTS, currentC⟩, if
the replica granted the next timestamp to this client.
- ⟨write-1-refused, grantTS, cid, oid,
op#, currentC⟩μcr, if the replica granted the timestamp to
some other client; the reply contains the grant to that client,
plus the information about this client's request (to prevent replays).
- ⟨write-2-ans, result,
currentC, rid⟩μcr, if the client's write has already been
executed (this can happen if this client is slow
and some other client performs the write for it – see step 2 below).
In a write-1-ok or write-1-refused reply, currentC is
the certificate for the latest write done at that replica.
The client discards invalid replies; it processes valid replies as
follows:
-
If it receives a quorum of OKs for the same viewstamp and
timestamp, it forms a write certificate from the grants in the
replies and moves to the write-2 phase.
- If it receives a quorum of refusals with the same viewstamp,
timestamp, and hash, some other client has received a quorum of
grants and should be executing a write phase 2. To
facilitate progress in the presence of slow or failed clients, the
client forms a certificate from these grants and performs the write
followed by a repeat of its own write-1 request: it sends a
⟨writeBackWrite,
writeC, w1⟩ to the replicas, where w1 is a copy
of its write-1 request;
replicas reply with their responses to the write-1.
- If it receives grants with different viewstamps or timestamps,
it also performs a writeBackWrite, this time using the latest write
certificate it received. This case can happen when
some replica has not heard of an earlier write. Writebacks are sent
only to the slow replicas.
- If it receives a write-2-ans, it uses the
certificate in the write-2-ans to move to phase 2. This case can
happen if some other client performed its write (did step 2 above).
- If it receives a quorum of responses containing grants
with the same viewstamp and timestamp but otherwise different, it
sends a resolve request to the replicas; the handling of this
request is discussed in Section 3.3. This situation
indicates the possibility of write contention, The replies to the resolve request are identical to replies to a write-1 request,
so the responses are handled as described in this section.
Write-2 phase.
The client sends a ⟨write-2, writeC⟩
request, where writeC is the write certificate it obtained in phase
1. Then it waits for a quorum of valid matching responses of the form
⟨write-2-ans, result,
currentC, rid⟩μcr; once it has these responses it returns
to the calling application. It will receive this many matching
responses unless there is contention; we discuss this case in
Section 3.3.
Read Protocol.
The client sends ⟨read, cid, oid, op,
nonce⟩μcr requests to the replicas. The
nonce is used to uniquely identify the request, allowing a
reader to distinguish the respective reply from a replay. The response
to this request has the form ⟨read-ans,
result, nonce, currentC, rid⟩μcr.
The client waits for a quorum of valid matching replies
and then returns the result to the calling application. If it receives
replies with different viewstamps or timestamps, it sends a
⟨writeBackRead,
writeC, cid, oid, op, nonce⟩μcr
to the (slow) replicas, requesting that they perform the write
followed by the read. Here writeC is the latest write certificate
received in the replies. This case can occur when a write is running
concurrently with the read.
3.2.2 Processing at the Replicas
Now we describe processing at the replicas in the absence of
contention resolution.
Each replica keeps the following information for each object:
-
currentC, the certificate for the current state of the object.
- grantTS, a grant for the next timestamp, if one exists
- ops, a list of write-1 requests that are currently under
consideration (the request that was granted the next
timestamp, and also requests that have been
refused), plus the request executed most recently.
- oldOps, a table containing, for each client authorized to write,
the op# of the most recently completed write request for that client
together with the result and certificate sent in the write-2-ans
reply to that request.
- vs, the current viewstamp (which advances each time
the system does contention resolution).
A replica discards invalid
requests (bad format, improperly signed, or invalid certificate).
It processes valid requests as follows:
Read request
⟨read, cid, oid, op, nonce⟩μcr.
The replica does an
upcall to the server code, passing it the op.
When this call returns it sends the result to the client in a
message ⟨read-ans, result, nonce,
currentC, rid⟩μcr. The nonce is used to ensure that the
answer is not a replay.
Write 1 request
⟨write-1, cid, oid, op#, op⟩σc.
If op# < oldOps[cid].op#, the request is old and is
discarded. If op# = oldOps[cid].op#, the replica returns
a write-2-ans response containing the
result and certificate stored in oldOps[cid]. If the request is
stored in ops, the replica responds with its previous write-1-ok or
write-1-refused response. Otherwise the replica appends the
request to ops. Then if
grantTS=null, it sets grantTS = ⟨
c, oid, op#, h, vs, currentC.ts+1, rid⟩σr,
where h is the hash of ⟨
cid, oid, op#, op⟩ and replies
⟨write-1-ok, grantTS, currentC⟩;
otherwise it replies ⟨write-1-refused, grantTS,
cid, oid, op#, currentC⟩μcr (since some other client
has been granted the timestamp).
Write 2 request
⟨write-2, writeC⟩.
Any node is permitted to run a write-2 request; the meaning of the
request depends only on the contained certificate rather than on the
identity of the sender. The certificate identifies the client c that
ran the write-1 phase and the oid and op# it requested.
The
replica uses the oldOps entry for c to identify old and duplicate write-2
requests; it discards old requests and returns the write-2 response stored
in oldOps[c] for duplicates.
If the request is new, the replica makes an upcall to the server code
to execute the operation corresponding to the request. A replica can
do the upcall to execute a write-2 request only if it knows the
operation corresponding to the request and it is up to date; in
particular its vs =writeC.vs and currentC.ts = writeC.ts−1. If
this condition isn't satisfied, it obtains the missing information
from other replicas as discussed in Sections 3.3
and 3.4,
and makes upcalls to perform earlier operations before executing the
current operation.
When it receives the result of the upcall, the replica updates the
information in the oldOps for c, sets grantTS to null,
sets ops to contain just the request being executed, and sets currentC = writeC. Then it replies ⟨write-2-ans, result, currentC, rid⟩μcr.
WriteBackWrite and WriteBackRead.
The replica
performs the write-2 request, but doesn't send the
reply. Then it processes the read or write-1 and
sends that response to the client.
3.3 Contention Resolution
Contention occurs when several clients are competing to write at the
same timestamp. Clients notice contention when processing responses to
a write-1 request, specifically case (5) of this processing,
where the client has received conflicting grants for the same viewstamp and
timestamp. Conflicting grants normally arise because of contention
but can also occur because a faulty client has sent different
requests to different replicas.
In either case a client requests contention resolution by
sending a ⟨resolve, conflictC, w1⟩ request to the replicas, where
conflictC is a conflict certificate formed from the grants in
the replies and
w1 is the write-1 request it sent that led to the conflict being
discovered. The processing of
this request orders one or more of the contending requests
and performs those requests in that order; normally all
contending requests will be completed.
To resolve contention we make
use of the BFT state machine protocol [2], which is also running
at the replicas. One of these replicas is acting as the BFT primary,
and the server proxy code tracks this information, just like a
client of BFT. However in our system, we use BFT only to reach agreement
on a deterministic ordering of the conflicting updates.
3.3.1 Processing at Replicas
To handle contention, a replica has additional state:
-
conflictC, either null or the conflict certificate
that started the conflict resolution.
- backupC, containing the previous write certificate (for
the write before the one that led to the currentC certificate).
- prev, containing the previous information stored in
oldOps for the client whose request was executed most recently.
A replica that is processing a resolve request has a non-null value in
conflictC. Such a replica is frozen: it does not respond to
client write and resolve requests, but instead delays this processing until
conflict resolution is complete.
When a non-frozen replica receives a valid ⟨resolve, clientConflictC, w1⟩ request, it
proceeds as follows:
-
If currentC is later than clientConflictC, or if
the viewstamps and timestamps match but the request has already
been executed according to the replica's oldOps, the conflict has already
been resolved (by contention resolution in the case where the
viewstamp in the message is less than vs). The request is handled
as a write-1 request.
- Otherwise the replica stores clientConflictC in
conflictC and adds w1 to ops if it is not already
there. Then it sends a ⟨start, conflictC, ops,
currentC, grantTS⟩σr message to the server
proxy code running at the current primary of the BFT protocol.
When the server proxy code running at the primary receives a quorum of
valid start messages (including one from itself) it creates a
BFT operation to resolve the conflict. The argument to this operation
is the quorum of these start messages; call this startQ.
Then
it causes BFT to operate by passing the operation request to the BFT
code running at its node. In other words, the server proxy becomes a
client of BFT, invoking an operation on the BFT service implemented by
the same replica set that implements the HQ service.
BFT runs in the normal way: the primary orders this operation relative
to earlier requests to resolve contention and starts the BFT protocol
to obtain agreement on this request and ordering. At the end of
agreement each replica makes an upcall to the server proxy code,
passing it startQ, along with the current viewstamp (which has
advanced because of the running of BFT).
In response to the upcall, the server proxy code produces the new
system state; now we describe this processing. In this discussion we
will use the notation startQ.currentC, startQ.ops, etc.,
to denote the list of corresponding components of the start
messages in startQ.
Producing the new state occurs as follows:
-
If startQ doesn't contain a quorum of correctly signed start
messages, the replica immediately returns from the upcall, without
doing any processing. This can happen only if the primary is
faulty. The replica makes a call to BFT requesting it to do a view
change; when this call returns, it sends its start message to
the new primary.
- The replica determines whether startQ.grantTS forms
a certificate (i.e., it consists of a quorum of valid matching
grants). It
chooses the grant certificate if one exists, else the latest valid
certificate in startQ.currentC; call this certificate C.
- Next the replica determines whether it needs to undo the most recent
operation that it performed prior to conflict resolution; this can
happen if some client started phase 2 of a contending write and the
replica had executed its write-2 request, yet none of the
replicas that contributed to startQ knew about the write-2 and
some don't even know of a grant for that request. The replica can
recognize the situation because currentC is later than C. To undo,
it makes an upcall to the server code, requesting the undo. Then it
uses prev to revert the state in oldOps for the client that
requested the undone operation, and sets currentC to backupC.
- Next the replica brings itself up to date by executing
the operation identified by C, if it hasn't already done
so. This processing may include executing even earlier operations,
which it can obtain from other replicas if necessary, as discussed in
Section 3.4. It executes the operations by
making upcalls to the server code and updates its oldOps to reflect
the outcome of these executions.
Note that all honest replicas will have identical oldOps after this step.
- Next the replica builds an ordered list L of operations that need
to be executed. L contains all valid non-duplicate (according to its
oldOps) requests in startQ.ops, except that the replica retains at most
one operation per client; if a (faulty) client submitted multiple
operations (different hashes), it selects one of these in a
deterministic way, e.g., smallest hash. The operations in L are
ordered in some deterministic way, e.g., based on the cid ordering
of the clients that requested them.
- The operations in L will be executed
in the selected order, but first the replica needs to obtain
certificates to support each execution. It updates vs to hold the
viewstamp given as an argument of the upcall and sends a grant
for each operation at its selected timestamp to all other replicas.
- The replica waits to receive 2f+1 valid
matching grants for each operation and uses them to form certificates.
Then it executes the operations in L in the selected order by making
upcalls, and updating ops, oldOps, grantTS and currentC (as in
Write-2 processing) as these executions occur.
- Finally the replica clears conflictC
and replies to the resolve request
that caused it to freeze (if there is one); this processing is
like that of a write-1 request (although most likely
a write2-ans response will be sent).
Conflict resolution has no effect on the processing of write-1
and read request. However, to process requests that contain
certificates (write-2, resolve, and also the write-back
requests) the replica must be as up to date as the client with respect
to contention resolution. The viewstamp conveys the needed
information: if the viewstamp in the certificate in the request is
greater than vs, the replica calls down to the BFT code at its node,
requesting to get up to date. This call returns the startQ's and
viewstamps for all the BFT operations the replica was missing. The replica
processes all of this information as described above; then it
processes the request as described previously.
A bad primary might not act on start messages, leaving the
system in a state where it is unable to make progress. To
prevent this, a replica will broadcast the start message to all
replicas if it doesn't receive the upcall in some time period;
this will cause BFT to do a view-change and switch to a new primary
if the primary is the problem. The
broadcast is also useful to handle bad clients that send the resolve request to just a few replicas.
3.3.2 Processing at Clients
The only impact of conflict resolution on client processing is that a
write-2-ans response might contain a different certificate than
the one sent in the write-2 request; this can happen if
contention resolution ran concurrently with the write 2 phase. To
handle this case the client selects the latest certificate and uses it
to redo the write-2 phase.
3.4 State Transfer
State transfer is required to bring slow replicas up to date so that they
may execute more recent writes. A replica detects that it has
missed some updates when it receives a valid certificate to execute a
write at timestamp t, but has an existing value of currentC.ts
smaller than t−1.
A simple but inefficient protocol for state transfer is to request
state from all replicas, for each missing update up to t−1, and
wait for f+1 matching replies.
To avoid transferring the same update from multiple replicas we take
an optimistic approach, retrieving a single full copy of
updated state, while confirming the hash of the updates from the
remaining replicas.
A replica requests state transfer from f+1 replicas, supplying a
timestamp interval for the required updates. One replica is designated
to return the updates, while f others send a hash over
this partial log. Responses are sought from other replicas if the
hashes don't agree with the partial log, or after a timeout. Since
the partial log is likely to be considerably larger than f hashes, the
cost of state transfer is essentially constant with
respect to f.
To avoid transferring large partial logs, we propose regular system
checkpoints to establish complete state at all
replicas [2]. These reduce subsequent writeback cost and
allow logs prior to the checkpoint to be discarded. To further
minimize the cost of state transfer, the log records may be
compressed, exploiting overwrites and application-specific
semantics [7]; alternatively, state may be transferred in
the form of differences or Merkle trees [15].
3.5 Correctness
This section presents a high-level correctness argument for the HQ
protocol. We prove only the safety properties of the system, namely
that we ensure that updates in the system are
linearizable [6], in that the system behaves like a
centralized implementation executing operations atomically one at a
time. A discussion of liveness can be found in [4].
To prove linearizability we need to show that there exists a
sequential history that looks the same to correct processes as the
system history. The sequential history must preserve certain ordering
constraints: if an operation precedes another operation in the system
history, then the precedence must also hold in the sequential history.
We construct this sequential history by ordering all writes by the
timestamp assigned to them, putting each read after the
write whose value it returns.
To construct this history, we must ensure that different writes are
assigned unique timestamps. The HQ protocol achieves this through its
two-phase process — writes must first retrieve a quorum of grants
for the same timestamp to proceed to phase 2, with any two quorums
intersecting at at least one non-faulty replica. In the absence of
contention, non-faulty replicas do not grant the same timestamp to
different updates, nor do they grant multiple timestamps to the same
update.
To see preservation of the required ordering constraints, consider the
quorum accessed in a read or write-1 operation. This
quorum intersects with the most recently completed write operation at
at least one non-faulty replica. At least one member of the quorum
must have currentC reflecting this previous write, and hence no
complete quorum of responses can be formed for a state previous to
this operation. Since a read writes back any pending write to a quorum
of processes, any subsequent read will return this or a later
timestamp.
We must also ensure that our ordering constraints are preserved in the
presence of contention, during and following BFT invocations. This is
provided by two guarantees:
-
Any operation that has
received 2f+1 matching write-2-ans responses prior to the
onset of contention resolution is guaranteed to retain its
timestamp t. This follows because at least one non-faulty replica
that contributes to startQ will have a currentC such that
currentC.ts ≥ t. Furthermore contention resolution leaves unchanged the
order of all operations with timestamps less than or equal to the
latest certificate in startQ.
- No operation ordered subsequently in contention resolution
can have a quorum of 2f+1 existing write-2-ans responses. This
follows from the above.
A client may receive up to 2f matching write-2-ans responses
for a given certificate, yet have its operation reordered and
committed at a later timestamp. Here it will be unable to complete a
quorum of responses to this original timestamp, but rather will see
its operation as committed later in the ordering after it redoes its
write-2 phase using the later certificate and receives a quorum of
write-2-ans responses.
The argument for safety (and also the argument for liveness given
in [4])
does not depend on the behavior of clients. This implies that the HQ
protocol tolerates Byzantine-faulty clients, in the sense that they
cannot interfere with the correctness of the protocol.
3.6 Transactions
This section describes how we extend our system to
support transactions that affect multiple objects.
We extend the client write-1 request so that now it can contain
more than one oid; in addition it must provide an op# for each
object. Thus we now have ⟨write-1, cid, oid1,
op1#, ..., oidk, opk#, op⟩σc. We still restrict
the client to one outstanding operation per object; this implies that
if it performs a multi-object operation, it cannot perform operations
on any of the objects used in that operation until it finishes.
Note that op could
be a sequence of operations, e.g., it consists of op1; ...; opm,
as perceived by the server code at the application.
The requirement for correct execution of a transaction is
that for each object it uses it must be executed
at the same place in the order for that object at all replicas.
Furthermore it must not be interleaved
with other transactions. For example suppose one
transaction consisted of op1(o1); op2(o2) while a second
consisted of op3(o1); op4(o2); then
the assignment of timestamps cannot be such that
o3 happens after o1 while o4 happens before o2.
We achieve these conditions as follows.
-
When a replica receives a valid new multi-object request, and
it can grant this client the next timestamp for each
object, it returns a multi-grant of the form ⟨cid, h, vs, olist⟩σr, where olist contains an entry
⟨oid, op#, ts⟩ for each object used by the
multi-object request; otherwise it refuses, returning all outstanding
grants for objects in the request. In either case it returns its most
recent certificate for each requested object.
- A client can move to phase 2 if it receives
a quorum of matching multi-grants. Otherwise it either does a writeBackWrite or requests contention
resolution. The certificate in the write-2 request contains
a quorum of multi-grants; it is valid only if the multi-grants
are identical.
- A replica processes a valid write-2 request by making a
single upcall to the application. Of course it does this only after
getting up to date for each object used by the request. This allows
the application to run the transaction atomically, at the right place
in the order.
- To carry out a resolve request, a replica
freezes for all objects in the request
and performs conflict resolution for them simultaneously:
Its start message contains information for each object
identified in the resolve request.
- When processing startQ during contention
resolution, a replica retains a most one valid
request per client per object. It orders these requests in some
deterministic way and sends grants to the other replicas; these will
be multi-grants if some of these request are multi-object
operations, and the
timestamp for object o will be o.currentC.ts+|Lo|, where Lo is
L restricted to requests that concern object o. It performs the
operations in the selected order as soon as it obtains the newC
certificate.
4 Optimizations
There are a number of ways to improve the protocol just described.
For example, the write-2-ans can contain the client op# instead
of a certificate; the certificate is needed only if it differs from
what the client sent in the request. In addition we don't send
certificates in responses to write-1 and read requests,
since these are used only to do writebacks, which aren't needed in
the absence of contention and failures; instead, clients need to
fetch the certificate from the replicas returning the largest
timestamp before doing the writeback. Another useful optimization is
to avoid sending multiple copies of results in responses to read
and write-2 requests; instead, one replica sends the answer,
while the others send only hashes, and the client accepts the answer
if it matches the hashes. Yet another improvement is to provide
grants optimistically in responses to write-1 requests: if the
replica is processing a valid write-2 it can grant the next
timestamp to the write-1 even before this processing
completes. (However, it cannot reply to the write-2 until
it has performed the operation.)
Below we describe two additional optimizations:
early grants and avoiding signing. In addition we discuss preferred
quorums, and our changes to BFT.
4.1 Early Grants
The conflict resolution strategy discussed in Section 3.3
requires an extra round of communication at the end of running
BFT in order for replicas to obtain grants and build certificates.
We avoid this communication by producing the grants while running BFT.
The BFT code at a replica executes an operation by making an upcall to
the code running above it (the HQ server code in our system) once it
has received a quorum of valid commit messages. We modify these
messages so that they now contain grants.
This is done by modifying the BFT code so that prior to sending commit messages it does a makeGrant upcall to the server proxy
code, passing it startQ and the viewstamp that corresponds to the
operation being executed. The server code determines the grants it
would have sent in processing startQ and returns them in its
response; the BFT code then piggybacks the grants on the commit
message it sends to the other replicas.
When the BFT code has the quorum of valid commit messages, it
passes the grants it received in these messages to the server proxy
code along with startQ and the viewstamp. If none of the replicas
that sent commit messages is faulty, the grants will be exactly
what is needed to make certificates. If some grants are bad, the replica
carries out the post phase as described in Section 3.3.
The grants produced while running BFT could be collected by a
malicious intruder or a bad replica.
Furthermore, the BFT operation might
not complete; this can happen if the BFT replicas carry out a view
change, and fewer than f+1 honest replicas had sent out their commit messages prior to the view change.
However, the malicious intruder can't make a certificate from
grants collected during the running of a single aborted BFT operation,
since there can be at most 2f of them, and it is unable
to make a certificate from grants produced during the execution of
different BFT operations because these grants contain different viewstamps.
4.2 Avoiding Signing
In Section 3, we assumed that grants and write-1
requests were signed. Here we examine what happens when we switch
instead to MACs (for write-1 requests) and authenticators
(for grants). An authenticator [2] is a vector of
MACs with an entry for each replica; replicas create authenticators
by having a secret key for each other replica and using it to create
the MAC for the vector entry that corresponds to that other
replica.
Authenticators and MACs work fine if there is no contention and
no failures.
Otherwise
problems arise due to
an important difference between signatures and authenticators: A
signature that any good client or replica accepts as valid will
be accepted as valid by all good clients and replicas; authenticators
don't have this property. For example, when processing startQ
replicas determined the most recent valid certificate; because we
assumed signatures, we could be sure that all honest replicas would
make the same determination. Without signatures this won't be true,
and therefore we need to handle things differently.
The only place where authenticators cause problems during non-contention
processing is in the responses to write-2 and writeback
requests.
In the approach described in Section 3.2, replicas drop
bad write-2 and writeback requests. This was reasonable
when using signatures, since clients can avoid sending bad
certificates.
But clients are unable to tell whether authenticators are valid;
they must rely on replicas to tell them.
Therefore we provide an additional response to write-2 and
writeback requests: the replica can send a write-2-refused
response, containing a copy of the certificate, and signed by it.
When a client receives such a response it requests contention
resolution.
The main issue in contention resolution is determining the latest
valid certificate in startQ. It doesn't work to just select the
certificate with the largest timestamp, since it might be
forged. Furthermore there might be two or more
certificates for the same highest timestamp but different requests;
the replicas need to determine which one is valid.
We solve these problems by doing some extra processing before running
BFT. Here is a sketch of how it works:
To solve the problem of conflicting certificates that propose the same
timestamp but for different requests, the primary builds startQ from
start messages as before except that startQ may contain more
than a quorum of messages. The primary collects start messages
until there is a subset startQsub that contains no conflicting
certificates. If two start messages propose conflicting
certificates, neither is placed in startQsub; instead the primary
adds another message to startQ and repeats the analysis. It is safe
for the primary to wait for an additional message because at least one
of the conflicting messages came from a dishonest replica.
This step ensures that startQsub contains at most one certificate
per timestamp. It also guarantees that at least one
certificate in startQsub contains a timestamp greater than or
equal to that of the most recently committed write operation because
startQsub contains at least f+1 entries from non-faulty
replicas, and therefore at least one of them supplies a late enough
certificate.
The next step determines the latest valid
certificate. This is accomplished by a voting phase in which
replicas collect signed votes for certificates that are
valid for them and send this information to the primary in signed accept messages; the details can be found in [4].
The primary collects a quorum of accept messages and includes
these messages as an extra argument in the call to BFT to execute the
operation. Voting can be avoided if the latest certificate was formed
from startQ.grantTS or proposed by at least f+1 replicas.
This step retains valid certificates but discards forged certificates.
Intuitively it works because replicas can only get votes for
valid certificates.
When replicas process the upcall from BFT,
they use the extra information to identify the latest certificate. An
additional point is that when replicas create the set L of
additional operations to be executed, they add an operation to L
only if it appears at least f+1 times in startQ.ops.
This test ensures that the operation is vouched for by at least one
non-faulty replica, and thus avoids executing forged operations.
This scheme executes fewer requests than the approach
discussed in Section 3.3.
In particular, a write request that has
already reached phase 2 will be executed in the scheme
discussed in Section 3.3, but now it might not be (because
it doesn't appear at least f+1 times in startQ.ops). In this
case when the write-2 request is processed by a replica after
contention resolution completes, the replica cannot honor the request.
Instead it sends a write-2-retry response containing a grant for
the next timestamp, either for this client or some other client. When
a client gets this response, it re-runs phase 1 to obtain a new
certificate before retrying phase 2.
4.3 Preferred Quorums
With preferred quorums, only a predetermined quorum of replicas
carries out the protocol during fault-free periods. This technique
is used in Q/U and
is similar to the use of witnesses in Harp
[10]. In addition to reducing cost,
preferred quorums ensure that all client operations intersect at the
same replicas, reducing the frequency of writebacks.
Since ultimately every replica must perform each operation, we have
clients send the write-1 request to all replicas. However, only
replicas in the preferred quorum respond, the authenticators in these
responses contain entries only for replicas in the preferred quorum,
and only replicas in the preferred quorum participate in phase 2. If
clients are unable to collect a quorum of responses, they switch to an
unoptimized protocol using a larger group.
Replicas not in the preferred quorum need to periodically learn
the current system state, in particular the timestamp of
the most recently committed operation. This communication can
be very lightweight, since only metadata and
not client operations need be fetched.
4.4 BFT Improvements
The original implementation of BFT was optimized to perform well at
small f, e.g., at f=2. Our implementation is intended to scale as
f increases. One main difference is that we use TCP instead of UDP,
to avoid costly message loss in case of congestion at high f.
The other is the use of MACs instead of authenticators in protocol
messages. The original BFT used authenticators to allow the same
message to be broadcast to all other replicas with a single operating
system call, utilizing IP multicast if available. However,
authenticators add linearly-scaling overhead to each message, with
this extra cost becoming significant at high f in a non-broadcast
medium.
Additionally, our implementation of BFT allows the use of preferred quorums.
5 Analysis
Here we examine the performance characteristics of HQ, BFT, and Q/U
analytically; experimental results can be found
in Section 6. We focus on the cost of write
operations since all three protocols offer one-phase read operations,
and we expect similar performance in this case. We also focus on
performance in the normal case of no failures and no contention. For
both HQ and Q/U we use assume preferred quorums and
MACs/authenticators. We show results for the original BFT algorithm (using
authenticators and without preferred quorums), BFT-MACs (using MACs
but not preferred quorums), and BFT-opt (using both MACs and preferred
quorums). We assume the protocols use point-to-point communication.
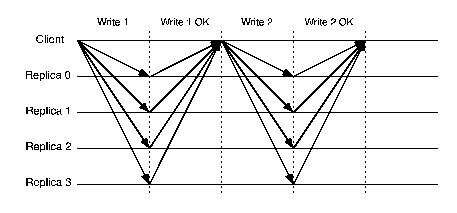
Figure 2: Protocol communication patterns - Quorum-based: HQ.
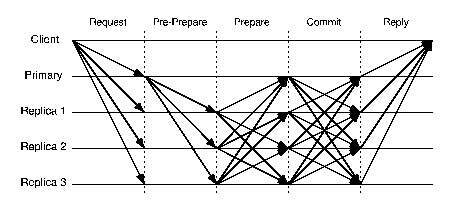
Figure 3: Protocol communication patterns - Agreement-based: BFT.
Figures 2 and 3 show the communication patterns for BFT and
HQ; the communication pattern for Q/U is similar to the first round of
HQ, with a larger number of replicas. Assuming that latency is dominated
by the number of message
delays needed to process a request, we can see that the latency of HQ
is lower than that of BFT and the latency for Q/U is half of that
for HQ. One point to
note is that BFT can be optimized so that
replicas reply to the client following the
prepare phase, eliminating
commit-phase latency in the absence of failures; with this
optimization BFT can achieve the same latency as HQ. However, to
amortize its quadratic communication costs, BFT employs batching,
committing a group of operations as a single unit. This can lead to
additional latency over a quorum-based scheme.
Figures 4 and 5
shows the total number of messages
required to carry out a write request in the three systems; the figure
shows the load at both clients and servers. Consider first
Figure 4, which shows the load at servers. In
both HQ and Q/U, servers process a constant number of messages to carry
out a write request: 4 messages in HQ and 2 in Q/U. In BFT, however,
the number of messages is linear in f: For each write operation that
runs through BFT, each replica must process 12f+2 messages.
This is reduced to 8f+2 messages in
BFT-opt by using preferred quorums.
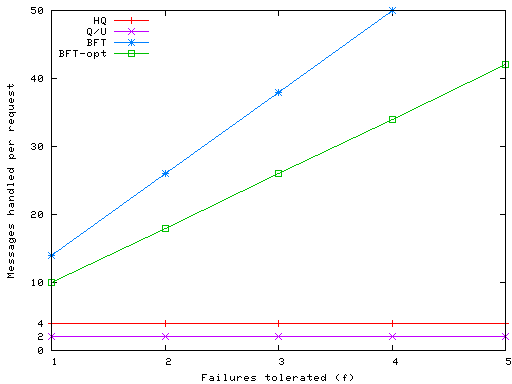
Figure 4: Total server messages sent/received per write operation in BFT, Q/U, and HQ
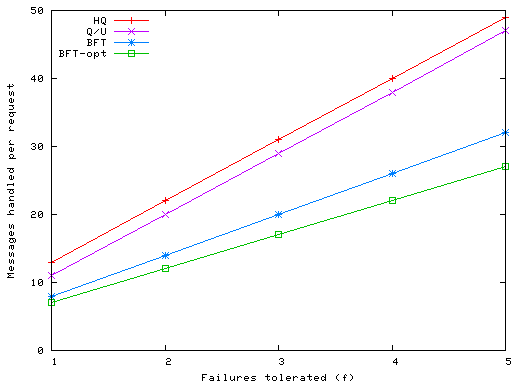
Figure 5: Total client messages sent/received per write operation in BFT, Q/U, and HQ
Figure 5 shows the load at the client. Here we
see that BFT-opt has the lowest cost, since a client just sends the
request to the replicas and receives a quorum of responses. Q/U also
requires one message exchange, but it has larger quorums (of size
4f+1), for 9f+2 messages. HQ has two message exchanges but uses
quorums of size 2f+1; therefore the number of messages processed at
the client, 9f+4, is similar in HQ to Q/U.
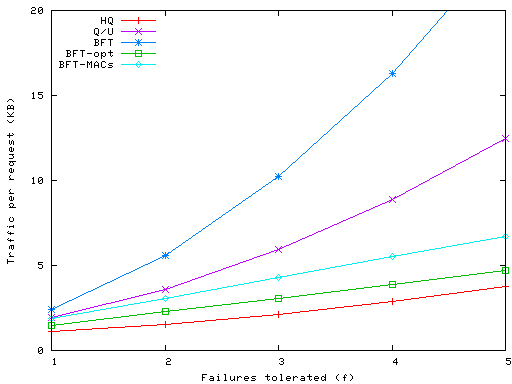
Figure 6: Total server traffic sent/received per write operation in BFT, Q/U, and HQ

Figure 7: Total client traffic sent/received per write operation in BFT, Q/U, and HQ
Figures 6 and 7 show the total byte count of the messages
processed to carry out a write request. This is computed using
20 byte SHA-1 digests [17] and HMAC authentication codes [16], 44 byte TCP/IP
overhead, and a nominal request payload of 256 bytes. We analyze the
fully optimized version of Q/U, using compact timestamps and
replica histories pruned to the minimum number of two
candidates. The results for BFT in Figure 6
show that our optimizations (MACs and preferred quorums) have a major
impact on the byte count at replicas.
The use of MACs
causes the number of bytes to grow only linearly with f
as opposed to quadratically as in BFT, as shown by
the BFT-MACs line; an additional linear reduction in traffic
occurs through
the use of preferred quorums, as shown by BFT-opt line.
Figure 6 also shows results for HQ and Q/U. In HQ
the responses to the write-1 request contains an authenticator
and the write-2 request contains a certificate, which grows
quadratically with f. Q/U is similar: The response to a write
returns what is effectively a grant (replica history), and
these are combined to form a certificate (object history
set), which is sent in the next write request. However, the grants
in Q/U are considerably larger than those in HQ and also contain
bigger authenticators (size 4f+1 instead of 2f+1), resulting in
more bytes per request in Q/U than HQ. While HQ and Q/U are
both affected by quadratically-sized certificates, this becomes a problem
more slowly in HQ: At a given value of f=x in
Q/U, each certificate contains the same number of grants as in HQ at
f=2x.
Figure 7 shows the bytes required at the client.
Here the load for BFT is low, since the client simply sends
the request to all replicas and receives the response. The
load for Q/U is the highest, owing to the quadratically growing
certificates, larger grants and communication with approximately
twice as many replicas.
6 Experimental Evaluation
This section provides performance results for HQ and BFT in
the case of no failures. Following [1], we focus on
performance of writes in a counter service supporting increment and
fetch operations. The system supports multiple counter objects; each
client request involves a single object and the client waits for a
write to return before executing the subsequent request. In the
non-contention experiments different clients use different objects; in
the contention experiments a certain percentage of requests goes to a
single shared object.
To allow meaningful comparisons of HQ and BFT, we produced new
implementations of both, derived from a common C++
codebase. Communication is implemented over TCP/IP sockets, and we use
SHA-1 digests for HMAC message authentication. HQ uses preferred quorums;
BFT-MACs and BFT-opt use MACs instead of authenticators, with the latter
running preferred quorums. Client operations in the
counter service consist of a 10 byte op payload, with no disk
access required in executing each operation.
Our experiments ran on Emulab [20], utilizing 66
pc3000 machines. These contain 3.0 GHz 64-bit Xeon processors
with 2GBs of RAM, each equipped with gigabit NICs. The
emulated topology consists of a 100Mbps switched LAN with near-zero
latency, hosted on a gigabit backplane with a Cisco 6509 high-speed
switch. Network bandwidth was not found to be a limiting factor in any
of our experiments. Fedora Core 4 is installed on all machines,
running Linux kernel 2.6.12.
Sixteen machines host a single replica each, providing support up to f=5,
with each of the remaining 50 machines hosting two clients. We vary
the number of logical clients between 20 and 100 in each experiment,
to obtain maximum possible throughput. We need a large
number of clients to fully load the system because we limit
clients to only one operation at a time.
Each experiment runs for 100,000 client operations of burn-in time
to allow performance to stabilize, before recording data for the
following 100,000 operations. Five repeat runs were recorded for
each data-point, with the variance too small to be visible in our plots.
We report throughput; we observed batch size and
protocol message count in our experiments and these results match
closely to the analysis in Section 5.
We begin by evaluating performance when there is no contention:
we examine
maximum throughput in HQ and BFT, as well as their scalability
as f grows.
Throughput is CPU-bound in all
experiments, hence this figure reflects message processing
expense and cryptographic operations, along with kernel message
handling overhead.
Figure 8 shows that the lower message count and
fewer communication phases in HQ is reflected in higher throughput.
The figure also shows significant benefits for the two BFT optimizations;
the reduction in message size achieved by BFT-MACs, and the reduced
communication and cryptographic processing costs
in BFT-opt.
Throughput in HQ drops by 50% as f grows from 1 to 5, a
consequence of the overhead of computing larger
authenticators in grants, along with receiving and validating larger
certificates. The BFT variants show slightly worse scalability, due
to the quadratic number of protocol messages.
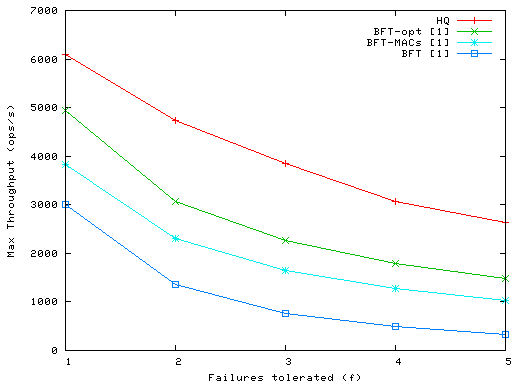
Figure 8: Maximum non-batched write throughput under varying f.
Based on our analysis, we expect Q/U to provide somewhat less than
twice the throughput of HQ at f=1, since it requires
half the server message exchanges but more processing per message
owing to larger messages and more MAC computations.
We also expect it to scale less well than HQ, since its
messages and processing grow more quickly with f than HQ's.
The results in Figure 8 don't tell the whole story.
BFT can batch requests: the primary collects messages
up to some bound, and then runs the protocol once per
batch. Figure 9 shows that batching greatly improves
BFT performance. The figure shows results for maximum batch sizes of
2, 5, and 10; in each case client requests may accumulate
for up to 5ms at the primary, yielding observed batch sizes very
close to the maximum.
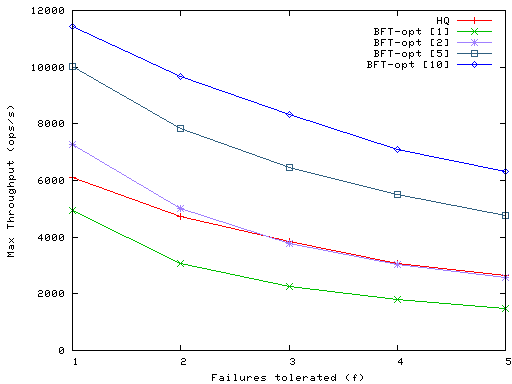
Figure 9: Effect of BFT batching on maximum write throughput.
Figure 10 shows the performance of HQ for
f=1,...,5 in the presence of write contention; in the figure
contention factor is the fraction of writes
executed on a single shared object. The figure shows that HQ
performance degrades gracefully as contention increases. Performance
reduction flattens significantly for high rates of write contention
because multiple contending operations are ordered with a single round
of BFT, achieving a degree of write batching. For example, at f=2
this batching increases from an average of 3 operations ordered per
round at contention factor 0.1 to 16 operations at contention factor 1.
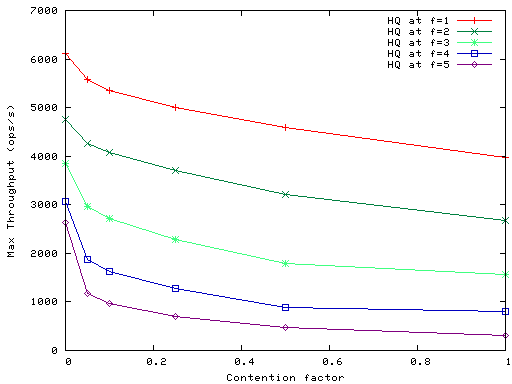
Figure 10: HQ throughput under increasing write contention.
7 Related Work
Byzantine quorum systems were introduced
by Malkhi and Reiter [12].
The initial constructions were designed to handle only read and
(blind) write operations. These were less powerful than state machine
replication (implemented by our protocols) where the outcome of an
operation can depend on the history of previously executed operations.
Byzantine quorum protocols were later extended to support general
object replication assuming benign clients (e.g. [13, 3]), and subsequently to support Byzantine clients but for
larger non-blocking quorums [5]. Still more recent work
showed how to handle Byzantine clients while using only 3f+1
replicas [11].
Recently, Abd-El-Malek et al. [1]
demonstrated for the first time how
to adapt a quorum protocol to implement state machine
replication for multi-operation transactions
with Byzantine clients. This is achieved with a combination of optimistic
versioning and by having client requests store a
history of previous operations they depend on, allowing the
detection of conflicts in the ordering of operations (due to
concurrency or slow replicas) and the retention of the correct version.
Our proposal builds on this work but reduces the number of replicas
from 5f+1 to 3f+1. Our protocol does not require as many replicas
owing to our mechanism for detecting and recovering from conflicting
orderings of concurrent operations at different replicas. The Q/U
protocols use a one-phase algorithm for writes; Abd-El-Malek et al show
in their paper that their one-phase write protocol cannot run with
fewer than 5f+1 replicas (with quorums of size 4f+1). We use a
two-phase write protocol, allowing us to require
only 3f+1 replicas. A further difference of our work from Q/U
is our use of BFT to order contending writes; this hybrid
approach resolves contention much more efficiently than the approach
used in Q/U, which resorts to an exponential backoff of concurrent
writers that may lead to a substantial performance degradation.
In work done concurrently with that on Q/U, Martin and
Alvisi [14] discuss the tradeoff between number of rounds
and number of replicas for reaching agreement, a building block
that can be used to construct state machine
replication. They prove that 5f+1 replicas are needed
to ensure reaching agreement in two communication steps and they
present a replica-based algorithm that shows this lower bound is
tight.
Earlier proposals for Byzantine fault tolerant state-machine replication
(e.g., Rampart [18] and
BFT [2])
relied on inter-replica communication, instead of
client-controlled, quorum-based protocols, to serialize requests.
These protocols employ 3f+1 replicas, and have
quadratic communication costs in the normal case, since each operation
involves a series of rounds where each replica sends a message to all
remaining replicas, stating their agreement on an ordering that
was proposed by a primary replica. An important optimization
decouples the agreement from request execution [21]
reducing the number of the more
expensive storage replicas to 2f+1
but still retaining the quadratic communication costs.
8 Conclusions
This paper presents HQ, a new protocol for
Byzantine-fault-tolerant state-machine replication. HQ
is a quorum based protocol that
is able to run arbitrary operations.
It reduces the required number of replicas from
the 5f+1 needed in earlier work (Q/U) to the minimum of 3f+1
by using a two-phase instead of a one-phase write protocol.
Additionally we present a new way of handling contention in
quorum-based protocols: we use BFT. Thus we propose a hybrid approach
in which operations normally run optimistically, but a pessimistic
approach is used when there is contention. The hybrid approach can be
used broadly; for example it could be used in Q/U to handle contention,
where BFT would only need to run at a predetermined subset
of 3f+1 replicas.
We also presented a new implementation of BFT that was
developed to scale with f.
Based on our analytic and performance results, we believe the following
points are valid:
- In the region we studied (up to f=5), if contention is low and
low latency is the main issue, then if it is acceptable to use 5f+1
replicas, Q/U is the best choice else HQ is best since it outperforms
BFT with a batch size of 1.
- Otherwise, BFT is the best choice in this region:
it can handle high contention workloads, and
it can beat the throughput of both HQ and Q/U through its use of
batching.
- Outside of this region, we expect HQ will scale best. Our
results show that as f grows, HQ's throughput decreases more slowly than
Q/U's (because of the latter's larger messages and processing costs) and BFT's
(where eventually batching cannot compensate for the quadratic number
of messages).
9 Acknowledgments
We thank the anonymous reviewers and our shepherd Mema Roussopoulos
for their valuable feedback and the developers of Q/U for
their cooperation.
We also thank the supporters of Emulab, which was absolutely crucial
to our ability to run experiments.
This research was supported by
NSF ITR grant CNS-0428107 and by T-Party, a joint program between
MIT and Quanta Computer Inc., Taiwan.
References
- [1]
-
Abd-El-Malek, M., Ganger, G. R., Goodson, G. R., Reiter, M. K., and Wylie,
J. J.
Fault-scalable byzantine fault-tolerant services.
In SOSP '05: Proceedings of the twentieth ACM symposium on
Operating systems principles (New York, NY, USA, 2005), ACM Press,
pp. 59–74.
- [2]
-
Castro, M., and Liskov, B.
Practical Byzantine Fault Tolerance and Proactive Recovery.
ACM Transactions on Computer Systems 20, 4 (Nov. 2002),
398–461.
- [3]
-
Chockler, G., Malkhi, D., and Reiter, M.
Backoff protocols for distributed mutual exclusion and ordering.
In Proc. of the IEEE International Conference on Distributed
Computing Systems (2001).
- [4]
-
Cowling, J., Myers, D., Liskov, B., Rodrigues, R., and Shrira, L.
Hq replication: Properties and optimizations.
Technical Memo In Prep., MIT Computer Science and Artificial
Laboratory, Cambridge, Massachusetts, 2006.
- [5]
-
Fry, C., and Reiter, M.
Nested objects in a byzantine Quorum-replicated System.
In Proc. of the IEEE Symposium on Reliable Distributed
Systems (2004).
- [6]
-
Herlihy, M. P., and Wing, J. M.
Axioms for Concurrent Objects.
In Conference Record of the 14th Annual ACM Symposium on
Principles of Programming Languages (1987).
- [7]
-
Kistler, J. J., and Satyanarayanan, M.
Disconnected Operation in the Coda File System.
In Thirteenth ACM Symposium on Operating Systems Principles
(Asilomar Conference Center, Pacific Grove, CA., Oct. 1991), pp. 213–225.
- [8]
-
Lamport, L., Shostak, R., and Pease, M.
The Byzantine Generals Problem.
ACM Transactions on Programming Languages and Systems 4, 3
(July 1982), 382–401.
- [9]
-
Lamport, L. L.
The implementation of reliable distributed multiprocess systems.
Computer Networks 2 (1978), 95–114.
- [10]
-
Liskov, B., Ghemawat, S., Gruber, R., Johnson, P., Shrira, L., and
Williams, M.
Replication in the Harp File System.
In Proceedings of the Thirteenth ACM Symposium on Operating
System Principles (Pacific Grove, California, 1991), pp. 226–238.
- [11]
-
Liskov, B., and Rodrigues, R.
Byzantine clients rendered harmless.
Tech. Rep. MIT-LCS-TR-994 and INESC-ID TR-10-2005, July 2005.
- [12]
-
Malkhi, D., and Reiter, M.
Byzantine Quorum Systems.
Journal of Distributed Computing 11, 4 (1998), 203–213.
- [13]
-
Malkhi, D., and Reiter, M.
An Architecture for Survivable Coordination in Large Distributed
Systems.
IEEE Transactions on Knowledge and Data Engineering 12, 2 (Apr.
2000), 187–202.
- [14]
-
Martin, J.-P., and Alvisi, L.
Fast byzantine consensus.
In International Conference on Dependable Systems and
Networks (2005), IEEE, pp. 402–411.
- [15]
-
Merkle, R. C.
A Digital Signature Based on a Conventional Encryption Function.
In Advances in Cryptology - Crypto'87, C. Pomerance, Ed.,
no. 293 in Lecture Notes in Computer Science. Springer-Verlag, 1987,
pp. 369–378.
- [16]
-
National Institute of Standards and Technology.
Fips 198: The keyed-hash message authentication code (hmac), March
2002.
- [17]
-
National Institute of Standards and Tecnology.
Fips 180-2: Secure hash standard, August 2002.
- [18]
-
Reiter, M.
The Rampart toolkit for building high-integrity services.
Theory and Practice in Distributed Systems (Lecture Notes in
Computer Science 938) (1995), 99–110.
- [19]
-
Schneider, F. B.
Implementing fault-tolerant services using the state machine
approach: a tutorial.
ACM Comput. Surv. 22, 4 (1990), 299–319.
- [20]
-
White, B., Lepreau, J., Stoller, L., Ricci, R., Guruprasad, S., Newbold,
M., Hibler, M., Barb, C., and Joglekar, A.
An integrated experimental environment for distributed systems and
networks.
In Proc. of the Fifth Symposium on Operating Systems Design and
Implementation (Boston, MA, Dec. 2002), USENIX Association,
pp. 255–270.
- [21]
-
Yin, J., Martin, J., Venkataramani, A., Alvisi, L., and Dahlin, M.
Separating agreement from execution for byzantine fault tolerant
services.
In Proceedings of the 19th ACM Symposium on Operating Systems
Principles (Oct. 2003).
|