 [Next]
[Up]
[Previous]
[Next]
[Up]
[Previous]
To understand the factors that influence scalability for a throughput-centric workload, we analyzed Denali's performance when running many web server VMs. We found that three factors strongly influenced scalability: disk transfer block size, the popularity distribution of requests across VMs, and the object size transferred by each web server.
To evaluate these factors, we used a modified version of the httperf
HTTP measurement tool to generate requests across a parameterizable
number of VMs. We modified the tool to generate requests according to
a Zipf distribution with parameter ![]() . We present results for repeated requests to a small object of 2,258 bytes
(approximately the median web object size). Requests of a larger web
object (134,007 bytes) were qualitatively similar.
. We present results for repeated requests to a small object of 2,258 bytes
(approximately the median web object size). Requests of a larger web
object (134,007 bytes) were qualitatively similar.
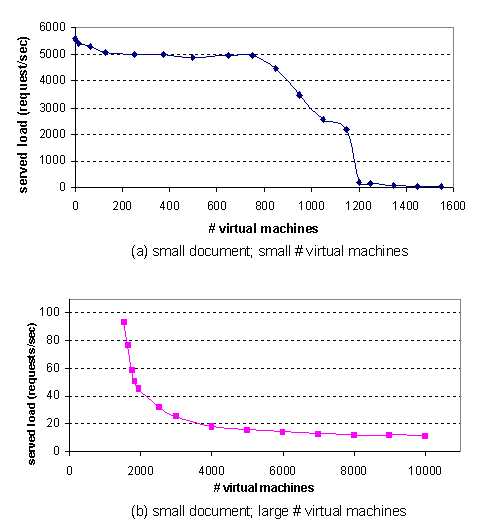
Figure 8: In-core vs. out-of-core: (a) shows aggregate performance up to the ``cliff'' at approximately 1000 VMs; (b) shows aggregate performance beyond the cliff.
The performance of Denali at scale falls into two regimes. In the in-core regime, all VMs fit in memory, and the system can sustain nearly constant aggregate throughput independent of scale. When the number of active VMs grows to a point that their combined working sets exceed the main memory capacity, the system enters the disk-bound regime. Figure 8 demonstrates the sharp performance cliff separating these regimes.
In-core regime: To better understand the performance cliff, we evaluated the effect of two variables: disk block transfer size, and object popularity distribution. Reducing the block size used during paging can improve performance by reducing internal fragmentation, and as a consequence, reducing a VM's in-core footprint. This has the side-effect of delaying the onset of the performance cliff (Figure 9): by using a small blocksize, we can push the cliff to beyond 1000 VMs.
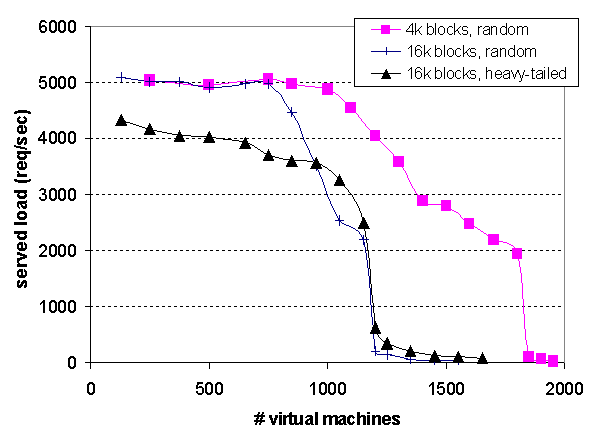
Figure 9: Block size and popularity distribution: this graph shows the effect of varying block size and popularity distribution on the ``cliff''; the web servers were serving a 2,258 byte document.
Disk-bound regime: To illustrate Denali's performance in the disk-bound regime, we examined web server throughput for 4,000 VMs serving the ``small'' document; the footprint of 4,000 VMs easily exceeds the size of main memory. Once again, we considered the impact of block size and object popularity on system performance.
To explore the effect of heavy-tailed distributions, we fixed the disk
block transfer size at 32 kilobytes, and varied the Zipf popularity
parameter ![]() . As
. As ![]() increases, the distribution becomes
more concentrated on the popular VMs. Unlike the CPU and the network,
Denali's paging policy is purely demand driven; as a result, Denali is
able to capitalize on the skewed distribution, as shown in
Figure 10.
increases, the distribution becomes
more concentrated on the popular VMs. Unlike the CPU and the network,
Denali's paging policy is purely demand driven; as a result, Denali is
able to capitalize on the skewed distribution, as shown in
Figure 10.
Figure 11 illustrates the effect of increased block size on throughput. As a point of comparison, we include results from a performance model that predicts how much performance our three disk subsystem should support, given microbenchmarks of its read and write throughput, assuming that each VM's working set is read in using random reads and written out using a single sequential write. Denali's performance for random requests tracks the modeled throughput, differing by less than 35% over the range of block sizes considered.
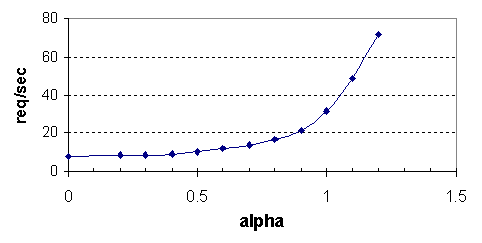
Figure 10: Out-of-core performance vs.
: increasingly skewed popularity distributions have better out-of-core performance; this data was gathered for 4,000 VMs serving the small web object, and a block size of 32KB.
This suggests that Denali is utilizing most of the available raw disk bandwidth, given our choice of paging policy. For heavy-tailed requests, Denali is able to outperform the raw disk bandwidth by caching popular virtual machines in main memory. To improve performance beyond that which we have reported, the random disk reads induced by paging would need to be converted into sequential reads; this could be accomplished by reorganizing the swap disk layout so that the working sets of VMs are laid out sequentially, and swapped in rather than paged in.
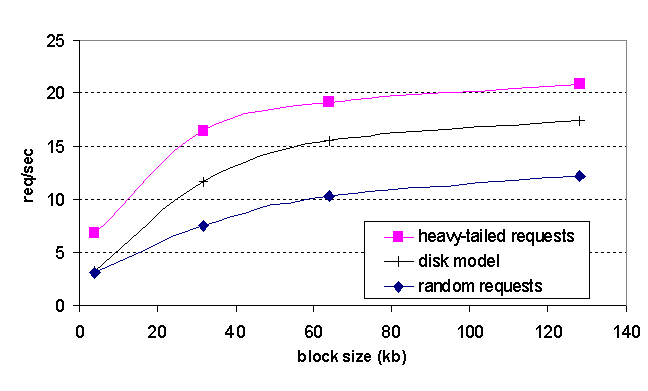
Figure 11: Out-of-core performance vs. block size: increased block size leads to increased performance in the out-of-core regime.