| ||||||||||||||||||||||||||||||||||||||||||||||||||||
|
MobiSys '05 Paper
[MobiSys '05 Technical Program]
Accuracy Characterization for Metropolitan-scale Wi-Fi Localization
Abstract
Location systems have long been identified as an important component
of emerging mobile applications. Most research on location systems
has focused on precise location in indoor environments. However, many
location applications (for example, location-aware web search) become
interesting only when the underlying location system is available
ubiquitously and is not limited to a single office environment.
Unfortunately, the installation and calibration overhead involved for
most of the existing research systems is too prohibitive to imagine
deploying them across, say, an entire city. In this work, we evaluate
the feasibility of building a wide-area 802.11 Wi-Fi-based positioning
system. We compare a suite of wireless-radio-based positioning
algorithms to understand how they can be adapted for such ubiquitous
deployment with minimal calibration. In particular, we study the
impact of this limited calibration on the accuracy of the positioning
algorithms. Our experiments show that we can estimate a user's
position with a median positioning error of 13-40 meters (depending
upon the characteristics of the environment). Although
this accuracy is lower than existing positioning
systems, it requires substantially lower calibration overhead
and provides easy deployment and
coverage across large metropolitan areas.
|
 |
Many previous radio-based positioning systems have used the observed signal strength as a indicator of distance from a radio source. In practice, this works only as well as the radio beacon's signal strength decays predictably with distance and is not overly-attenuated by factors such as the number of walls crossed, the composition of those walls, and multi-path effects. For instance, buildings with brick walls attenuate radio signals by a different amount than buildings made of wood or glass. In addition to fixed obstructions in the environment, people, vehicles and other moving objects can cause the attenuation to vary in a given place over time.
To characterize how observed 802.11 signal strengths varied with
distance, we collected 500 readings
at varying distances from a access points with well known locations in an urban area.
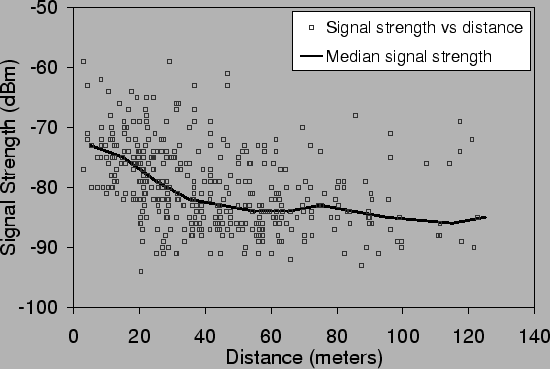
Figure 1 illustrates the variation in signal
strength for a single access point in a busy coffee shop![[*]](footnote.png) as a function of the distance between the AP and the
receiver. This graph plots the individual readings as well as showing how the median signal strength changes with distance.
as a function of the distance between the AP and the
receiver. This graph plots the individual readings as well as showing how the median signal strength changes with distance.
The points for the individual readings show considerable spread for a given distance, and medium to weak readings (-70 to -90 dBm) occur at all distances. The curve showing the median signal strength does indicate however that there is a trend towards seeing weaker signals as distance from an access point grows. This indicates that while care needs to be taken, signal strength can be used as a weak indicator of distance and can thus be used to improve location estimation over simple observation.
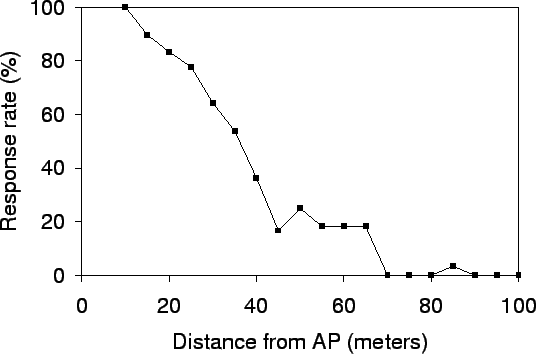 |
In addition to signal strength, we explore a new metric for estimating a user's position. We define the response rate metric as follows: from the training data set, we collect all Wi-Fi scans that are at the same distance from an access point; we then compute the fraction of times that this AP is heard in that collection of Wi-Fi scans. For scans close to the AP, we expect the response rate to be high while for scans further away, with signal attenuation and interference, the AP is less likely to be heard and so the response rate will be low. We measured the response rate as a function of distance, and as can be seen in Figure 2, there is a strong correlation between the response rate and the distance from the AP. Our results may seem contradictory to the results from Roofnet [1], which shows packet loss rate has low correlation to distance. Roofnet measured the raw loss rate of 1500 byte broadcast packets across distant nodes (over 100 meters). On the other hand, we measure probe response rate of APs within 100 meters. The probe response packet is about 100 bytes and uses link-level unicast retransmissions. With shorter distance, smaller sized packets and link-level retransmissions, we noticed a stronger correlation between response rate and distance.
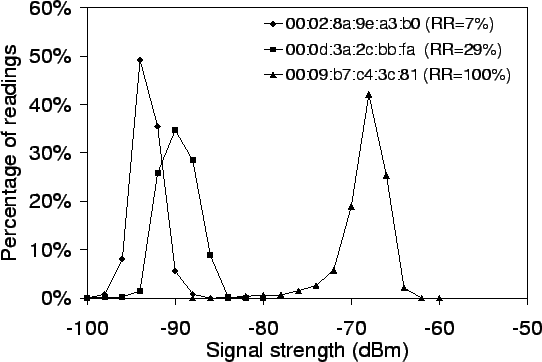 |
These observations tend to reduce our confidence in algorithms that depend on signal strength varying predictably as a function of distance to the access point. Response rate appears to vary much more predictably vs. distance. However, even though the effect of distance is largely unpredictable, Figure 3 indicates that for a given location, signal strengths are relatively stable. Thus different locations may still be reliably identified by their signal strength signature. We test these beliefs experimentally in the remainder of this paper.
Based on the above observations, we looked at three classes of positioning algorithms. In this section, we present an overview of these algorithms.
This is the simplest positioning algorithm.
During the training phase, we combine all of the
readings for a single access point and estimate a geographic location
for the access point by computing the arithmetic mean of the positions reported in all of the
readings. Thus, the radio map for this algorithm has one record per
access point containing the estimated position of that AP.
Using this map, the centroid algorithm positions the user at the center of all of the APs heard during a scan by computing an average of the estimated positions of each of the heard APs. In addition to the simple arithmetic mean, we also experimented with a weighted version of this mechanism, where the position of each AP was weighted by the received signal strength during the scan.
This algorithm is based on an indoor positioning mechanism proposed in RADAR [2]. The hypothesis behind RADAR is as follows: at a given point, a user may hear different access points with certain signal strengths; this set of APs and their associated signal strengths represents a fingerprint that is unique to that position. As can be inferred from Figure 3, radio fingerprints are potentially a good indicator of a user's position. We used the same basic fingerprinting technique, but with the much coarser-grained war driving compared to the in-office dense dataset collected for RADAR. Thus, for fingerprinting, the radio map is the raw war-driving data itself, with each point in the map being a latitude-longitude coordinate and a fingerprint containing a scan of Wi-Fi access points and the signal strength with which they were heard.
In the positioning phase, a user's Wi-Fi device performs a scan of its
environment. We compare this scan with all of the fingerprints in the
radio map to find the fingerprint that is the closest match to the
positioning scan in terms of APs seen and their corresponding signal
strengths. The metric that we use for comparing various fingerprints
is ![]() -nearest-neighbor(s) in signal space as described in the
original RADAR work. Suppose the positioning scan discovered three
APs
-nearest-neighbor(s) in signal space as described in the
original RADAR work. Suppose the positioning scan discovered three
APs ![]() ,
, ![]() , and
, and ![]() with signal strengths
with signal strengths
![]() . We
determine the set of recorded fingerprints in the radio map that have
the same set of APs and compute the distance in signal space between
the observed signal strengths and the recorded ones in the
fingerprints. Thus, for each matching fingerprint with signal
strengths
. We
determine the set of recorded fingerprints in the radio map that have
the same set of APs and compute the distance in signal space between
the observed signal strengths and the recorded ones in the
fingerprints. Thus, for each matching fingerprint with signal
strengths
![]() , we compute the Euclidean distance:
, we compute the Euclidean distance:
To account for APs that may have been deployed after the radio map was
generated and for lost beacons from access points, we apply the
following heuristics. First, during the positioning phase, if we
discover any AP that never appears in the radio map, we ignore that
AP. Second, when matching fingerprints to an observed scan, if we
cannot find fingerprints with the same set of APs as heard in the
scan, we expand the search to look for fingerprints that have
supersets or subsets of the APs in the observed scan. We match
fingerprints that have at most ![]() different APs between the
fingerprint in the radio map and the observed scan. These heuristics
help improve the matching rate for fingerprints significantly from
70% to 99%. Across all of our data sets, we found that
different APs between the
fingerprint in the radio map and the observed scan. These heuristics
help improve the matching rate for fingerprints significantly from
70% to 99%. Across all of our data sets, we found that ![]() provides the best matching rate without reducing overall accuracy.
provides the best matching rate without reducing overall accuracy.
Fingerprinting is based on the assumption that the Wi-Fi devices used
for training and positioning measure signal strengths in the same
way. If that is not the case (due to differences caused by
manufacturing variations, antennas, orientation, etc.), one cannot
directly compare the signal strengths. To account for this, we
implemented a variation of fingerprinting called ranking
inspired by an algorithm
proposed for the RightSpot system [15]. Instead of
comparing absolute signal strengths,
this method compares lists of access points sorted by signal
strength. For example, if the positioning scan discovered
![]() , then we replace this set of signal
strengths by their relative ranking, that is,
, then we replace this set of signal
strengths by their relative ranking, that is,
![]() . Likewise, if
. Likewise, if
![]() , then
, then
![]() . We compare the relative rankings using the
Spearman rank-order correlation coefficient [23]:
. We compare the relative rankings using the
Spearman rank-order correlation coefficient [23]:
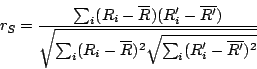
Particle filters have been used in the past, primarily in robotics, to
past
fuse a stream of sensor data into location
estimates [9,21,13].
A particle filter is a
probabilistic approximation algorithm that implements a Bayes
filter [6]. It represents the location estimate
of a user at time ![]() using a collection of weighted particles
using a collection of weighted particles
![]() . Each
. Each ![]() is a distinct hypothesis
about the user's current position. Each
particle has a weight
is a distinct hypothesis
about the user's current position. Each
particle has a weight ![]() that represents the likelihood that this
hypothesis is true, that is, the
probability that the user's device would hear the observed scan if it
were indeed at the position of the particle. A detailed
description of the particle filter algorithm can be found in
[13].
that represents the likelihood that this
hypothesis is true, that is, the
probability that the user's device would hear the observed scan if it
were indeed at the position of the particle. A detailed
description of the particle filter algorithm can be found in
[13].
Particle-filter based location techniques require two input models: a sensor model and a motion model. The sensor model is responsible for computing how likely an individual particle's position is, given the observed sensor data. For Place Lab, the sensor model estimates how likely it is that a given set of APs would be observed at a given location. The motion model's job is to move the particles' locations in a manner that approximates the motion of the user.
For our experiments, we built two sensor models: one based on signal
strength, while the other based on the response rate metric defined
earlier. During the training phase, for each access point, we build an
empirical model of how the signal strength and response rate vary by
distance. Rather than fit the mapping data to a parametric function,
Place Lab maintains a small table with an entry for each 5 meter
increment in distance from the estimated AP location. Response rates
are recorded as a percentage, while the signal
strength distribution is recorded as a fraction of observations with
low, medium and high strength for each distance bucket. The
low/medium/high cut-offs are determined empirically to split the
training data for each AP uniformly into the three categories.
As an example, Place Lab will compute and record that for an AP
![]() , its response rate
at 60 meters is (say) 55%. We also record that at 60 meters, that AP will be
seen with medium signal strength much more often than low or high.
Given a new Wi-Fi scan, the sensor model determines a particle's
likelihood as follows: for each AP in the scan, we look up the response
rate or the probability of seeing the measured signal strength based on
the distance between the particle and the estimated AP location in the
radio map.
, its response rate
at 60 meters is (say) 55%. We also record that at 60 meters, that AP will be
seen with medium signal strength much more often than low or high.
Given a new Wi-Fi scan, the sensor model determines a particle's
likelihood as follows: for each AP in the scan, we look up the response
rate or the probability of seeing the measured signal strength based on
the distance between the particle and the estimated AP location in the
radio map.
Place Lab uses a simple motion model that moves particles random distances in random directions. Our future work includes incorporation of more sophisticated motion models (such as those by Patterson et al. [22]) that model direction, velocity and even mode of transportation.
 |  |  |
 |  |  |
We collected traces of war-driving data in three neighborhoods in the
Seattle metropolitan area:
For each neighborhood, we collected traces in two phases. First we constructed training data sets by driving around each neighborhood for thirty minutes with a Wi-Fi laptop and a GPS unit. Our data collection software performed Wi-Fi scans four times per second using an Orinoco-based 802.11b Wi-Fi card. GPS readings were logged approximately once per second. To assign latitude-longitude coordinates to each Wi-Fi scan, we used linear interpolation between consecutive GPS readings based on the timestamps associated with the Wi-Fi scans and the two GPS readings.
In the second phase, we collected another set of traces for each neighborhood. These traces are used as test data to estimate the positioning accuracy of the various Place Lab algorithms. In this phase, Place Lab used only the Wi-Fi scans collected in the trace, while the GPS readings were used as ``ground truth'' to compute the accuracy of the user's estimated position. To ensure that we gathered clean ground truth data, we tried to navigate within areas where the GPS device continuously reported a GPS lock and eliminated (and re-gathered) traces where the GPS data was obviously erroneous. Note that GPS has an accuracy of 5-7 meters, bounding the accuracy of our measurements to this level of granularity.
Even though Place Lab can be used both outdoors and indoors, most of our evaluation below is based on traces that were collected entirely outdoors. This limitation is due to the fact that we use GPS as ground truth and hence can evaluate Place Lab's performance only when GPS is available. In Section 4.6, we will present results from a simple experiment where we used Place Lab indoors.
In this section, we present our results from a suite of experiments conducted using the above data sets. Our results demonstrate the effect of varying a number of parameters on the accuracy of positioning using Place Lab.
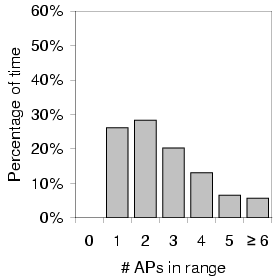
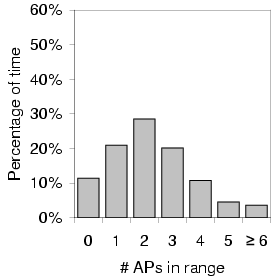
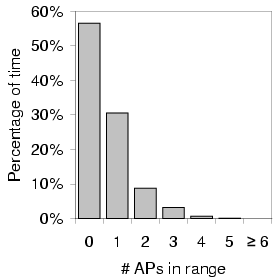
Figure 4 shows the distribution of the number of access
points in range per scan for each of the three areas we measured.
Table 1 shows the density of APs in the three areas.
As expected, we noticed the highest density of APs in the downtown urban
setting with an average of 2.66 APs per scan and no scans without
APs. Also not surprisingly, the suburban traces saw zero APs (that
is, no coverage) more than half the time and rarely saw more than
one. Interestingly, the residential Ravenna data had almost the same
number of APs per ![]() as downtown. With the
exception of the approximately 10% of scans with no coverage, the AP
density distribution for Ravenna fairly closely matched the downtown
distribution.
as downtown. With the
exception of the approximately 10% of scans with no coverage, the AP
density distribution for Ravenna fairly closely matched the downtown
distribution.
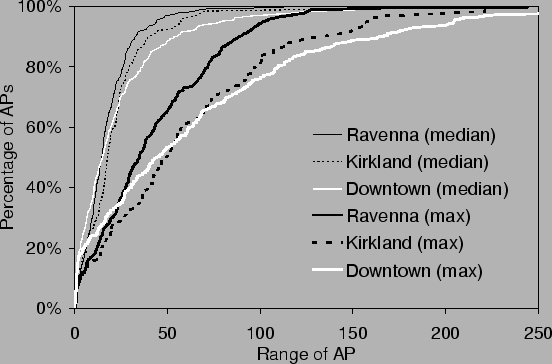
We also plotted the median and maximum range of each AP based on estimated positions of the AP from the radio map. Figure 5 shows a cumulative distribution function (CDF) of the median and maximum ranges for each of the three areas. In the relatively sparse Kirkland area, we notice that APs can be heard at a longer range than in Ravenna. We believe that this is due to the fact that Ravenna has a much denser distribution of access points and thus experiences higher interference (and consequently shorter range) as the data-gathering station gets further away from the AP. On the other hand, in downtown, which has about the same AP density as Ravenna, the maximum AP range is higher. This is due to the large number of tall buildings in downtown; APs that are located on higher floors often have a much longer range.
We now compare the relative performance of our positioning algorithms across the three areas. To evaluate the accuracy of Place Lab's positioning, we compare the position reported by Place Lab to that reported by the GPS device during the collection of the positioning trace. Table 2 summarizes the results. Ravenna, with its high density of short-range access points, performs the best and can estimate the user's position with a median error of 13-17 meters. Surprisingly, for Ravenna, there is little variation across the different algorithms. Even the simple centroid algorithms perform relatively well.
On the other hand, in Kirkland, with much lower AP density, we notice
that the median positioning error is 2-3 times worse. But,
as we move from the centroid algorithm to the particle-filter-based
techniques, we notice a substantial improvement in accuracy (25%
decrease in median error).
In this case, the smarter algorithms were better able to filter through
the sparse data and estimate the user's position. However, one algorithm that
performed quite poorly in Kirkland is ranking. This is because of the
significant number of times that a Wi-Fi scan produced a single AP.
With just one AP, there can be no relative ranking, and hence the
algorithm picks a random set of ![]() fingerprints that contain the AP and
attempts to position the user at the average position of those
randomly chosen fingerprints.
fingerprints that contain the AP and
attempts to position the user at the average position of those
randomly chosen fingerprints.
In the downtown area, even though the AP density is the same as Ravenna, median error is higher by 5-10 meters. This is due to the fact that APs in the tall buildings of downtown typically have a larger range and thus can be heard much further away than APs in Ravenna.
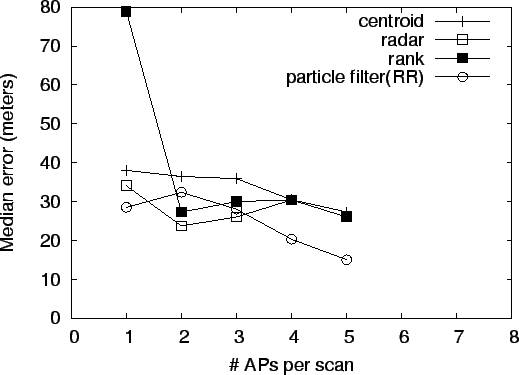
Finally, to understand the effect of the numbers of APs per scan on the positioning accuracy, we separated the output of the positioning traces based on the number of APs that were heard in each scan. For each group, we computed the median error. Figure 6 shows the median error as a function of the number of APs that were seen in a scan for one of the areas. Variants of algorithms that performed similar to their counterparts are left out for clarity. As we can see, the higher the number of APs heard during a scan, the lower the median positioning error. This graph also shows quite starkly the poor performance of ranking in the presence of a single known access point.
 |
When building a metropolitan-scale positioning system, an important question to ask is how fresh the training data needs to be in order to produce reasonable positioning estimates. In particular, new access points may be deployed while existing APs are decommissioned. We can express AP turnover as the percentage of currently deployed access points that are not present in the training data set. To measure the effect of such obsolete training data, we generated variations of the three training sets (one for each area) by randomly dropping access points from the original data. This simulates the effect of having performed the training war drive before these APs were deployed. Note that decommissioned APs are, for the most part, less of a problem. They result in dead state in the training data and, except for fingerprinting, their presence in the training data does not affect the positioning algorithm.
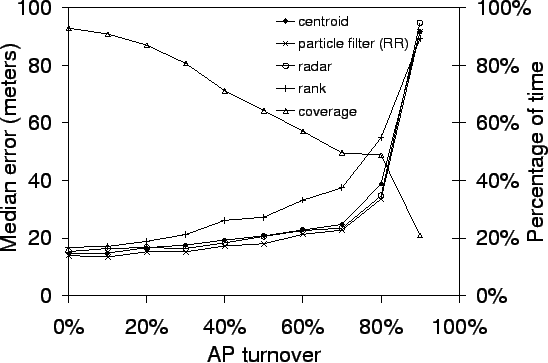
Figure 7 shows how AP turnover affects
the median positioning error for the Ravenna
neighborhood. From the figure, we can see that
as the AP turnover rate increases, the coverage (that is, the
percentage of time that at least one known AP is within range of the
user) decreases. What is important to note though is that for most
algorithms, an AP turnover of even 30%
produces minimal
effect on the positioning accuracy. The positioning error starts to
increase noticeably only after at least half of the access points in
the area have turned over. The exception to this is the ranking
algorithm. Since it relies on a fairly coarse metric for positioning
(relative rank order of AP signal strengths), the fewer APs available
for this relative ordering, the worse its performance.
This data suggests that training data for an area does not need to be refreshed too often. Of course, the refresh rate (and exactly when to refresh) would depend on the turnover rate of APs in that area. Our experiments used variations that randomly dropped access points across the original training data. This is reasonable in dense urban areas as well as in residential neighborhoods where there are many uncorrelated deployments of access points. This is less true of large-scale deployments, say across a suburban office complex or a university campus, that span an entire neighborhood and are typically upgraded in lock step.
Correlated turnover can be an issue even in seemingly uncorrelated neighborhoods. As an anecdotal example, we looked at the AP turnover in the Ravenna neighborhood, which happens to be located near the University of Washington. Some of the blocks that we war drove are home to the university fraternity houses. We compared our Ravenna data set (which was gathered after the start of the school year) to another data set of the same neighborhood that we gathered earlier during the middle of the summer. At least 50% of the APs in the later set of traces did not appear in our earlier traces. This was due to the fact that between our two experiments, new students had arrived for the fall quarter while summer students left en masse. Hence, when determining the schedule and frequency of refresh for the training data, it is important to take into account such social factors that can have a significant effect on the deployment of access points.
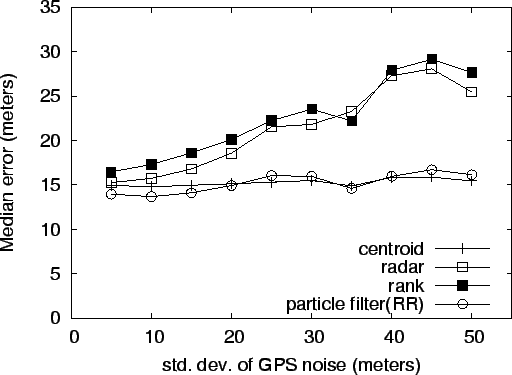
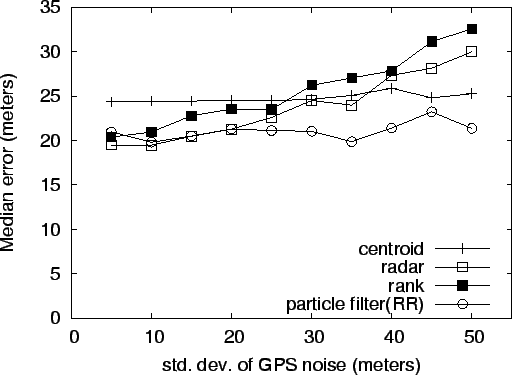
Some geographic regions will have higher GPS errors than others, due to urban canyons or foliage. This next experiment was designed to measure how robust the algorithms are to errors in the measured positions of the training data, which are normally measured via GPS. One way to assess the effect of poor GPS data would be to single out those areas where the GPS data is known to be poor. However, such locations may well exhibit Wi-Fi anomalies like multipath in urban canyons or RF blockage in areas of thick foliage [19]. In order to assess the overall effect of inaccurate GPS data on all our test data, we added zero mean Gaussian noise to the originally measured latitude-longitude readings in the training data. To make the results easier to understand, we specified the standard deviation of the noise in meters and converted to degrees latitude or longitude with the following:
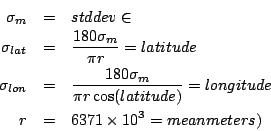
In the next experiment, we vary the geometric density of mapping points in
the training data set. We expect the accuracy will go down with
decreasing density of training data points. This variation is intended to
find the effect of reduced density in the training set (which in turn
means less calibration). We measured training density as the mean
distance from each point (latitude-longitude coordinate) in the
training data set to its geometrically nearest neighbor. In order to
generate this variation, we first split the training
file into a grid of 10m ![]() 10m cells. We then eliminated
Wi-Fi scans from the training data set one by one, creating a new
mapping file after each
elimination. To pick the next point to eliminate, we randomly picked
one point in the cell with the highest population of points. If two or
more cells tied for the maximum number of points, we picked between
those tied cells at random. By eliminating points from the cells with
the highest population, this algorithm tended to eliminate points
around higher densities, driving the training files toward a more
uniform density of data points for testing.
10m cells. We then eliminated
Wi-Fi scans from the training data set one by one, creating a new
mapping file after each
elimination. To pick the next point to eliminate, we randomly picked
one point in the cell with the highest population of points. If two or
more cells tied for the maximum number of points, we picked between
those tied cells at random. By eliminating points from the cells with
the highest population, this algorithm tended to eliminate points
around higher densities, driving the training files toward a more
uniform density of data points for testing.
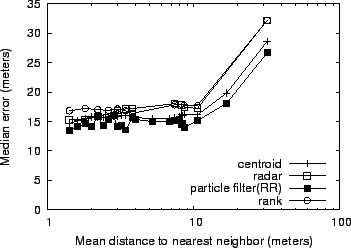
Figure 10 shows the median positioning
error as a function of the average distance to the nearest neighbor in
the training data set. The higher the average distance, the sparser
the data set. From the figure, we can see that until the mapping density
drops below 10 meter average distance between points, there is no
appreciable effect on median error. Beyond that point, however, the
positioning error increases sharply. There is not much distinction in
this behavior across the various algorithms. This suggests that a
training map generated at a scanning rate of one Wi-Fi scan per second
and a driving speed of 20-25 miles/hour (or faster speeds with repeated drives through
the same neighborhood) is sufficient to provide reasonable accuracy.
 |
All of the above experiments used training and positioning data sets that were collected entirely outdoors. Since the training data requires GPS, it must necessarily be collected outdoors. In the positioning phase, Place Lab can be used both outdoors and indoors. However, it is difficult to quantify the accuracy while indoors since we cannot collect any ground truth GPS data. To demonstrate the usability of Place Lab indoors, we ran a simple experiment where we collected two-minute-long positioning traces in nine different indoor locations, along with longer outdoor training traces around those locations. For each location, we computed the average position estimated by Place Lab. In addition, we determined average latitude-longitude positions for all nine locations by plotting their addresses into a mapping tool (MapPoint). Table 3 summarizes the error between Place Lab's average estimate and the latitude-longitude position from MapPoint.
The average error from
this simple experiment ranges from 9 to 98 meters. Although at the
high end the average error is significantly higher than in our
previous experiments, it comes partially from inaccurate ground truth
data: we used a single latitude-longitude point to represent each
location when in fact each building may be several tens of meters
across. We stress that this experiment is not an attempt to draw general
conclusions about the accuracy of Place Lab when used indoors with
training data that was collected outdoors. The experiment only serves
to show that unlike GPS, Place Lab works indoors (and when there
is no line of sight to the sky). Of
course, one should remember that the limited calibration associated
with Place Lab inherently means that it cannot be used for precise
indoor location applications.
To summarize the results from the above experiments, we noted a few dominant effects that play a role in positioning accuracy using the various location techniques.
We now discuss some of the practical issues that must be addressed when deploying such a system in the real world. Our experimental setup used active scanning to probe for nearby access points. However, APs can sometimes be configured to not respond to broadcast probe packets. Moreover, they may never send out broadcast beacon packets announcing their presence either. In such scenarios, passive scanning where the Wi-Fi card does not send out probe requests, and instead simply sniffs traffic on each of the Wi-Fi channels, may be used. Passive scanning relies on network traffic to discover APs and hence can detect even cloaked APs that do not necessarily advertise their network IDs.
All of our experiments were performed in outdoor environments since we needed access to GPS data even for our positioning traces to allow us to compare Place Lab's estimated positions to some known ground truth. However, Place Lab can work indoors as well. Even though we were unable to perform extensive experiments to measure Place Lab's accuracy when indoors, our regular use of Place Lab in a variety of indoor situations has shown that it can routinely position the user within less than one city block of their true position. As long as the user's device can hear access points that have been mapped out, Place Lab can estimate its position. This accuracy is not sufficient for indoor location applications that require room-level (or greater) accuracy, but is more than enough for other coarser-grained applications. For such applications, Place Lab can function as a GPS replacement that works both indoors and outdoors.
We used Wi-Fi cards based on the Orinoco chipset for all of our experiments. As pointed out in [10], different chipsets can report different signal strength values for the same AP at the same location. This is because each chipset interprets the raw signal strength value differently. However, there is a linear correlation for measured signal strengths across chipsets. This was first shown by Haeberlen et. al. [10]. We validated this claim for the following chipsets: Orinoco, Prism 2, Aironet, and Atheros. If we record the chipset information when collecting data sets, then even if the positioning is done using a chipset that is different from the one used for collecting the training data, a simple linear transformation will be sufficient to map the signal strength values across them. Of course, this is important only for those algorithms that actually rely on signal strength for positioning.
As the first systematic study of metropolitan-scale Wi-Fi localization, our accuracy comparisons suggest what to pursue in terms of new positioning algorithms. We found that different algorithms work best with different densities and ranges of access points. Since both of these quantities can be measured beforehand, the best algorithm could be automatically switched in depending on the current situation. Further, the size of the radio map can be a substantial issue for small mobile devices. The centroid and particle filter radio maps are relatively compact whereas fingerprinting algorithms require the entire training data set as their radio map. If (say for privacy concerns), the user wishes to store the radio map for their region on their local device, this may be a factor in determining the appropriate algorithm to use.
Our studies also compare the effects of density of calibration data, noise in calibration, and age of data on the centroid, particle filter and fingerprinting algorithms. An algorithm combining these techniques is feasible, and it may prove to be both robust and accurate. Moreover, one could incorporate additional environmental data such as (for example) constrained GIS maps of city streets and highways for navigation applications to improve the positioning accuracy. While we leave these ideas for future work, our study gives a concrete basis for choosing what to do next.
Place Lab is an attempt at providing ubiquitous Wi-Fi-based positioning in metropolitan areas. In this paper, we compared a number of Wi-Fi positioning algorithms in a variety of scenarios. Our results show that in dense urban areas Place Lab's positioning accuracy is between 13-20 meters. In more suburban neighborhoods, accuracy can drop down to 40 meters. Moreover, with dense Wi-Fi coverage, the specific algorithm used for positioning is not as important as other factors including composition of the neighborhood (lots of tall buildings versus low-rises), age of training data, density of training data sets, and noise in the training data. In sparser neighborhoods, sophisticated algorithms that can model the environment more richly win out. All of this positioning accuracy (although lower than that provided by precise indoor positioning systems) can be achieved with substantially less calibration effort: half an hour to map out an entire city neighborhood as compared to over 10 hours for a single office building [10].
Interested readers may download the data sets used for these experiments and the Place Lab source code from http://www.placelab.org/.
|
This paper was originally published in the
Proceedings of the 3rd International Conference on Mobile Systems, Applications, and Services, Applications, and Services,
June 6–8, 2005 Seattle, WA Last changed: 20 May 2005 aw |
|