Recall that ![]() is the desired latency value
at which the array provides high throughput but small queuing
delay. Since PARDA tries to operate close to
is the desired latency value
at which the array provides high throughput but small queuing
delay. Since PARDA tries to operate close to ![]() , an
administrator can control the overall latencies in a cluster,
bounding IO times for latency-sensitive workloads such as OLTP. We
investigated the effect of the threshold setting by running PARDA with
different
, an
administrator can control the overall latencies in a cluster,
bounding IO times for latency-sensitive workloads such as OLTP. We
investigated the effect of the threshold setting by running PARDA with
different ![]() values. Six hosts access the array concurrently,
each running a VM with a 16 GB disk performing 16 KB random reads with
32 outstanding IOs.
values. Six hosts access the array concurrently,
each running a VM with a 16 GB disk performing 16 KB random reads with
32 outstanding IOs.
|
|
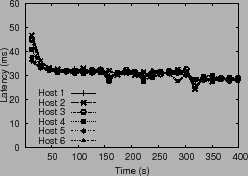
We first examine the throughput and latency
observed in the uncontrolled case, presented in
Table 4.
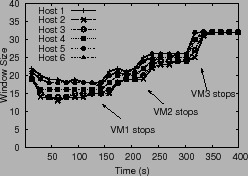
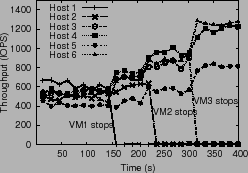
In Figure 9, we enable the control algorithm with
![]() = 30 ms and equal
shares, stopping one VM each at times
= 30 ms and equal
shares, stopping one VM each at times
![]() = 145 s,
= 145 s, ![]() = 220 s and
= 220 s and ![]() = 310 s.
Comparing the results
we can see the effect of the control algorithm
on performance. Without PARDA, the system
achieves a throughput of 3130 IOPS at an average latency of 60 ms. With
= 310 s.
Comparing the results
we can see the effect of the control algorithm
on performance. Without PARDA, the system
achieves a throughput of 3130 IOPS at an average latency of 60 ms. With
![]() = 30 ms, the system achieves a throughput of 3150 IOPS, while
operating close to the latency threshold. Other experiments with
different threshold values, such as those shown in
(
= 30 ms, the system achieves a throughput of 3150 IOPS, while
operating close to the latency threshold. Other experiments with
different threshold values, such as those shown in
(![]() = 40 ms)
and Figure 12
(
= 40 ms)
and Figure 12
(![]() = 25 ms), confirm that PARDA is effective at maintaining
latencies near
= 25 ms), confirm that PARDA is effective at maintaining
latencies near ![]() .
.
These results demonstrate that PARDA is able to control latencies
by throttling IO from hosts. Note the different window
sizes at which hosts operate for different values of ![]() .
Figure 9(a) also highlights the adaptation of
window sizes, as more capacity becomes available at the array when
VMs are turned off at various points in the experiment. The
ability to detect capacity changes through changes in latency is an
important dynamic property of the system.
.
Figure 9(a) also highlights the adaptation of
window sizes, as more capacity becomes available at the array when
VMs are turned off at various points in the experiment. The
ability to detect capacity changes through changes in latency is an
important dynamic property of the system.