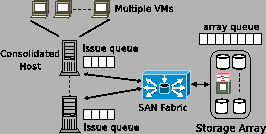
PARDA was designed for distributed systems such as the one shown in Figure 1. Multiple hosts access one or more storage arrays connected over a SAN. Disks in storage arrays are partitioned into RAID groups, which are used to construct LUNs. Each LUN is visible as a storage device to hosts and exports a cluster filesystem for distributed access. A VM disk is represented by a file on one of the shared LUNs, accessible from multiple hosts. This facilitates migration of VMs between hosts, avoiding the need to transfer disk state.
Since each host runs multiple virtual machines, the IO traffic issued by a host is the aggregated traffic of all its VMs that are currently performing IO. Each host maintains a set of pending IOs at the array, represented by an issue queue. This queue represents the IOs scheduled by the host and currently pending at the array; additional requests may be pending at the host, waiting to be issued to the storage array. Issue queues are typically per-LUN and have a fixed maximum issue queue length1 (e.g., 64 IOs per LUN).
IO requests from multiple hosts compete for shared resources at the storage array, such as controllers, cache, interconnects, and disks. As a result, workloads running on one host can adversely impact the performance of workloads on other hosts. To support performance isolation, resource management mechanisms are required to specify and control service rates under contention.
Resource allocations are specified by numeric shares, which are assigned to VMs that consume IO resources.2 A VM is entitled to consume storage array resources proportional to its share allocation, which specifies the relative importance of its IO requests compared to other VMs. The IO shares associated with a host is simply the total number of per-VM shares summed across all of its VMs. Proportional-share fairness is defined as providing storage array service to hosts in proportion to their shares.
In order to motivate the problem of IO scheduling across multiple
hosts, consider a simple example with four hosts running a total of
six VMs, all accessing a common shared LUN over a SAN. Hosts 1 and 2
each run two Linux VMs configured with OLTP workloads using
Filebench [20]. Hosts 3 and 4 each run a Windows
Server 2003 VM with Iometer [1], configured to generate
16 KB random reads. Table 1 shows that the VMs are
configured with different share values, entitling them to consume
different amounts of IO resources. Although a local start-time fair
queuing (SFQ) scheduler [16] does provide proportionate
fairness within each individual host, per-host local schedulers alone
are insufficient to provide isolation and proportionate fairness across hosts. For example, note that the aggregate throughput (in
IOPS) for hosts 1 and 2 is quite similar, despite their different
aggregate share allocations. Similarly, the Iometer VMs on hosts 3 and
4 achieve almost equal performance, violating their specified ![]() share ratio.
share ratio.
Many units of allocation have been proposed for sharing IO resources, such as Bytes/s, IOPS, and disk service time. Using Bytes/s or IOPS can unfairly penalize workloads with large or sequential IOs, since the cost of servicing an IO depends on its size and location. Service times are difficult to measure for large storage arrays that service hundreds of IOs concurrently.
In our approach, we conceptually partition the array queue among hosts in proportion to their shares. Thus two hosts with equal shares will have equal queue lengths, but may observe different throughput in terms of Bytes/s or IOPS. This is due to differences in per-IO cost and scheduling decisions made within the array, which may process requests in the order it deems most efficient to maximize aggregate throughput. Conceptually, this effect is similar to that encountered when time-multiplexing a CPU among various workloads. Although workloads may receive equal time slices, they will retire different numbers of instructions due to differences in cache locality and instruction-level parallelism. The same applies to memory and other resources, where equal hardware-level allocations do not necessarily imply equal application-level progress.
Although we focus on issue queue slots as our primary fairness metric, each queue slot could alternatively represent a fixed-size IO operation (e.g., 16 KB), thereby providing throughput fairness expressed in Bytes/s. However, a key benefit of managing queue length instead of throughput is that it automatically compensates workloads with lower per-IO costs at the array by allowing them to issue more requests. By considering the actual cost of the work performed by the array, overall efficiency remains higher.
Since there is no central server or proxy performing IO scheduling, and no support for fairness in the array, a per-host flow control mechanism is needed to enforce specified resource allocations. Ideally, this mechanism should achieve the following goals: (1) provide coarse-grained proportional-share fairness among hosts, (2) maintain high utilization, (3) exhibit low overhead in terms of per-host computation and inter-host communication, and (4) control the overall latency observed by the hosts in the cluster.
To meet these goals, the flow control mechanism must determine the maximum number of IOs that a host can keep pending at the array. A naive method, such as using static per-host issue queue lengths proportional to each host's IO shares, may provide reasonable isolation, but would not be work-conserving, leading to poor utilization in underloaded scenarios. Using larger static issue queues could improve utilization, but would increase latency and degrade fairness in overloaded scenarios.
This tradeoff between fairness and utilization suggests the need for a more dynamic approach, where issue queue lengths are varied based on the current level of contention at the array. In general, queue lengths should be increased under low contention for work conservation, and decreased under high contention for fairness. In an equilibrium state, the queue lengths should converge to different values for each host based on their share allocations, so that hosts achieve proportional fairness in the presence of contention.
Ajay Gulati 2009-01-14