Tiered Fault Tolerance for Long-Term Integrity
Byung-Gon Chun† Petros Maniatis† Scott Shenker§ John Kubiatowicz§
|
Abstract: Fault-tolerant services typically make assumptions about the type and maximum number of faults that they can tolerate while providing their correctness guarantees; when such a fault threshold is violated, correctness is lost. We revisit the notion of fault thresholds in the context of long-term archival storage. We observe that fault thresholds are inevitably violated in long-term services, making traditional fault tolerance inapplicable to the long-term. In this work, we undertake a “reallocation of the fault-tolerance budget” of a long-term service. We split the service into service pieces, each of which can tolerate a different number of faults without failing (and without causing the whole service to fail): each piece can be either in a critical trusted fault tier, which must never fail, or an untrusted fault tier, which can fail massively and often, or other fault tiers in between. By carefully engineering the split of a long-term service into pieces that must obey distinct fault thresholds, we can prolong its inevitable demise. We demonstrate this approach with Bonafide, a long-term key-value store that, unlike all similar systems proposed in the literature, maintains integrity in the face of Byzantine faults without requiring self-certified data. We describe the notion of tiered fault tolerance, the design, implementation, and experimental evaluation of Bonafide, and argue that our approach is a practical yet significant improvement over the state of the art for long-term services.
Because only 2 (= f+1) matching replies are required to convince a client of a result, even if the fault assumption is again met because one faulty replica is repaired, the remaining one faulty replica will always be able to corroborate r0's view of the world to some clients and r3's view of the world to other clients, keeping up the charade indefinitely. Crash-fault tolerant replicated state machines based on the Paxos [32] protocol do not deal with Byzantine faults explicitly (i.e., assume a Byzantine-fault threshold of 0) and they can have similar problems if a Byzantine fault crops up rarely and briefly.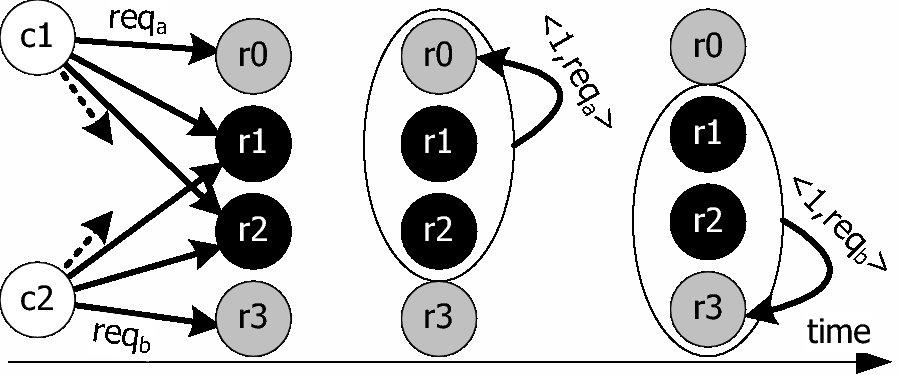
Figure 1: An example that shows the potential effects of a fault threshold violation in PBFT. Black circles are faulty replicas (one of them is the primary), gray circles are correct replicas, and white circles are clients. When two clients c1 and c2 submit requests reqa and reqb to the replicas at roughly the same time, but only manage to reach one correct replica each, the two faulty replicas can convince the two correct replicas to assign the same sequence number to different requests.
A Bonafide node contains a MAS as well as a buffer to hold Add requests temporarily and a main data structure that maintains committed bindings (Figure 3). In Bonafide, the service state—the key-value pairs—is maintained as a variation of a hash tree [37], which computes a cryptographic digest of the whole state from the leaves up, storing it at the tree root. The results of individual state queries (i.e., key lookups in the tree) can be validated against that root digest; as long as the digest is kept safe from tampering, individual lookups can be performed by an untrusted service component without risking an integrity violation. This state is replicated at each replica in the system in untrusted storage (bottom tier) but its root digest (of size on the order of 1 Kbit in today's hardware) is stored in each node's MAS. Each replica's MAS module lies in its most trusted fault tier: we assume that while in service no MAS module returns contents other than those that were stored at it. We use a MAS for the root digest of the service state, since it cryptographically protects the integrity of any answers about that state provided by even an untrusted component.
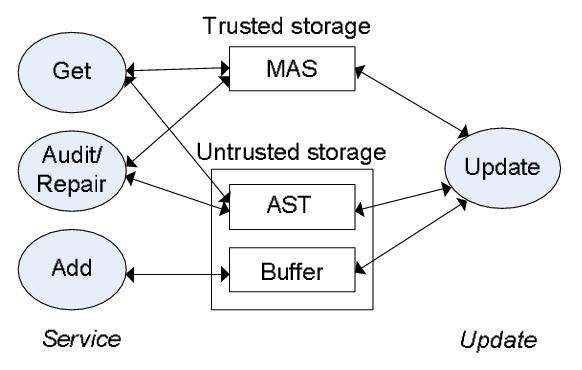
Figure 3: A Bonafide node contains the following state shown in the middle of the figure: a MAS, a buffer to hold Add requests temporarily, and an AST that maintains committed bindings. The MAS stores the AST root digest, a sequence number, and a checkpoint certificate. The left side shows the get, add, audit/repair processes running during the S phase, and the right side shows the update process running during the U phase. The arrows show what state the processes access.
Get: When a client c invokes Get(k) to retrieve a value of key k, its Bonafide stub (called a proxy below) multicasts ⟨ Get, k, z, c ⟩c messages to R where z is a nonce used for freshness and waits for f+1 ⟨ Reply, i, v, pi, ⟨ Lookup, qs, ⟨ si, ri ⟩, z, t, m ⟩i'⟩ valid matching messages confirming that ( k, v ) is within the AST, or that ( k, v ) does not exist in the AST. Note that the attestation includes the nonce the client sent to ensure it does not accept a stale response.
Client.Get(key) // quo_RPC sends msg to R, collects matching responses on non-* // fields from a quorum of given size, retransmits on timeout ⟨ Reply, *, value, witness, * ⟩ ← quo_RPC(⟨Get, key⟩, f+1) return value Server.Get(client, key)i // this is server i ⟨ value, witness ⟩ ← lookup_AST(key) att ← lookup_MAS(qs) // attestation send client a ⟨ Reply, i, value, witness, att ⟩ Client.Add(key,value) ⟨ TentReply, *, key, value⟩ ← quo_RPC(⟨Add, key, value⟩, 2f+1) // at this point, the client holds a tentative reply collect Reply messages // in the next S phase if (f+1 valid, matching replies are collected) return accepted(key, value) Server.Add(client, key, value)i if (⟨ key, value'⟩ in AST), treat as a Get and return add ⟨ client, key, value ⟩ to Adds send client a ⟨ TentReply, i, key, value⟩ Server.Audit(ASTNode,hASTNode)i status ← check ASTNode,hASTNode if (status invalid) repair ASTNode // fetch from other for each child C of ASTNode Audit(C, hC) // hC is contained in the label of ASTNode Server.Start_Service(Committed_Adds)i // reply for Adds committed in the previous U phase for each ⟨ key, value, client ⟩ in Committed_Adds send client a ⟨ Reply, i, value, witness, att ⟩
Figure 4: Simplified service process pseudocode.
Server.UpdateStart()i PBFT.Invoke(⟨ Batch, i, stable_ckpt_cert, Adds ⟩i) Server.Finalize()i Server.Execute(batch)i // PBFT Execute callback append batch in batch_log on receiving the 2f + 1-st batch: choose the latest stable_ckpt from batch_log AllAdds ← the union of the Adds set from each batch for each ⟨ key, value, client ⟩ in AllAdds repair the AST path to this new key if needed insert key,value into AST insert ⟨ key, value, client ⟩ into Committed_Adds store_MAS(qs, ASTRootDigest) multicast a UCheckPoint and flush batch_log Server.Finalize()i on receiving 2f + 1 matching UCheckPoints: store_MAS(qc, stable_ckpt_cert) reset the watchdog timer and the mode bit begin a new S phase
Figure 5: Update process pseudocode.
Audit and Repair Time: We measured the average time of a basic audit that does not perform any repair over five runs. The disk drive we used was an IBM 40GB IDE disk drive with rotation speed 7200 rpm, average seek time 8.5ms, and buffer size 2MB. The mean audit time of the entire AST is 554.5 seconds and the standard deviation is 9.9% of the mean.
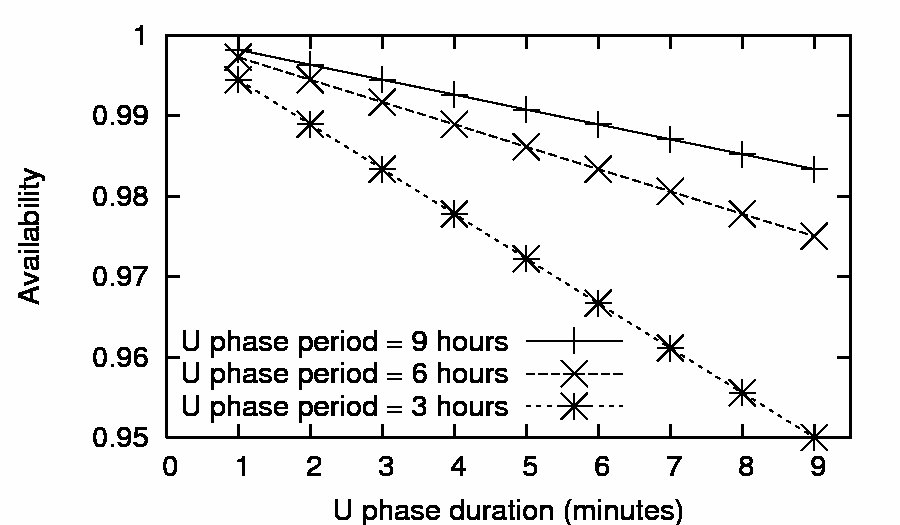
Availability: Finally, we analytically show that Bonafide availability (the ratio of service time to service time plus update time) is high enough for varying U phase duration and period in Figure 6. When the update period is 9 hours, availability is 0.998 and 0.983 for one-minute and nine-minute U phase durations, respectively. Availability decreases linearly as update duration increases. In addition, as we perform update more frequently (i.e., update period decreases), availability decreases more rapidly. For example, when update duration is nine minutes, availability drops from 0.983 to 0.950 as update period changes from 9 hours to 3 hours. However, when we perform update frequently, its duration may decrease since fewer additions are collected, mitigating the effects of unavailability. With one-minute update duration, availability becomes 0.994 despite three-hour periods.
This document was translated from LATEX by HEVEA.