
 |
We consider a client using ![]() K blocks each in two levels of cache, and having a network impact of up to
K blocks each in two levels of cache, and having a network impact of up to ![]() KBps. In a typical enterprise SAN environment, there are thousands of such concurrent application threads, scaling the need for both cache and network resources by many orders of magnitude. In fact, even without demotions, many SAN environments are regularly found bandwidth-bound (particularly with sequential reads), implying, as we observe below, that implementing DEMOTE might be detrimental to performance.
KBps. In a typical enterprise SAN environment, there are thousands of such concurrent application threads, scaling the need for both cache and network resources by many orders of magnitude. In fact, even without demotions, many SAN environments are regularly found bandwidth-bound (particularly with sequential reads), implying, as we observe below, that implementing DEMOTE might be detrimental to performance.
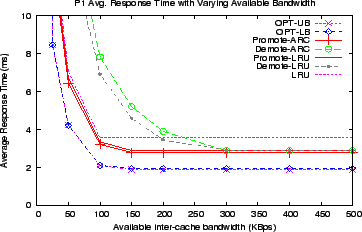
In Figure 12, we plot the average response time
as a function of the inter-cache bandwidth available to the client.
For each algorithm, we notice two regimes, a bandwidth-sensitive regime on the left side where decreasing the bandwidth available increases the average response time, and a bandwidth-insensitive, flat regime, on the right. As expected, OPT-UB, closely followed by OPT-LB, performs the best, with the lowest average response time and the least inter-cache bandwidth requirement (as indicated by the long flat portion on the right).
Note that, the DEMOTE variants perform even worse than plain LRU when bandwidth is not abundant.
SAN environments which cannot accommodate the ![]() x network cost of DEMOTE over LRU will see this behavior.
This fundamental concern has limited the deployment of DEMOTE algorithms in commercial systems.
x network cost of DEMOTE over LRU will see this behavior.
This fundamental concern has limited the deployment of DEMOTE algorithms in commercial systems.
The PROMOTE variants are significantly better than the DEMOTE variants when bandwidth is limited, while they outperform LRU handsomely when bandwidth is abundant. As bandwidth is reduced, LRU becomes only marginally worse than PROMOTE because the benefit of more hits in the lower cache, ![]() , is no longer felt as the bandwidth between the caches becomes the bottleneck. Overall, PROMOTE performs the best in all bandwidth regimes.
, is no longer felt as the bandwidth between the caches becomes the bottleneck. Overall, PROMOTE performs the best in all bandwidth regimes.