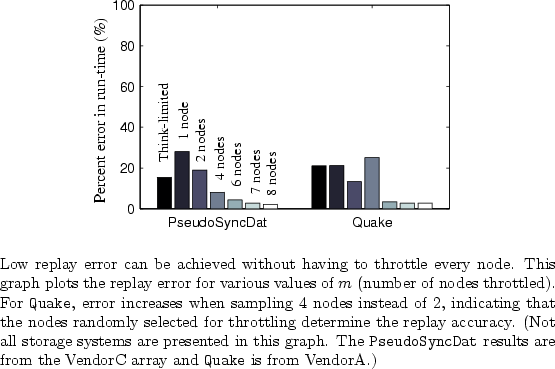
This experiment shows that low replay error can be achieved without having
to throttle every node. It compares the replay error for various
values of ![]() (the number of nodes throttled, chosen independently at random).
(the number of nodes throttled, chosen independently at random).
In some cases, node sampling can introduce error. Such is the case with Fitness, which only has 3 data dependencies. If any one of these is omitted, one of the nodes will issue I/O out of turn (resulting in concurrent access to the storage system). This represents a pathological case for node sampling. For example, when running on the VendorB platform, replay errors when throttling 1, 2, 3, and 4 nodes, are 37%, 29%, 17%, and 5%.
Quake and PseudoSyncDat are more typical applications. Figure 12 plots their error. With Quake, one achieves an error of 13% when throttling 2 of the 8 nodes (I/O sampling period of 5). Similarly, PseudoSyncDat achieves an 8% error when throttling 4 of the 8 nodes (I/O sampling period of 1). As with I/O sampling, one can sample nodes iteratively until a desired accuracy is achieved, and the traces can be evaluated across various storage systems to validate accuracy.
Interestingly, throttling more nodes does not necessarily improve replay accuracy (e.g., randomly throttling four nodes in Quake produces more error than throttling two). Because this experiment randomly selects the the throttled nodes, the sampled nodes may not necessarily be the ones with the most performance-affecting data dependencies. Therefore, heuristics for intelligent node sampling are required to more effectively guide the trace collection process and further reduce tracing time. In addition, learning to recognize common synchronization patterns (e.g,. barrier synchronization) could reduce the number of nodes that would need to be throttled. These are both interesting areas of future research.