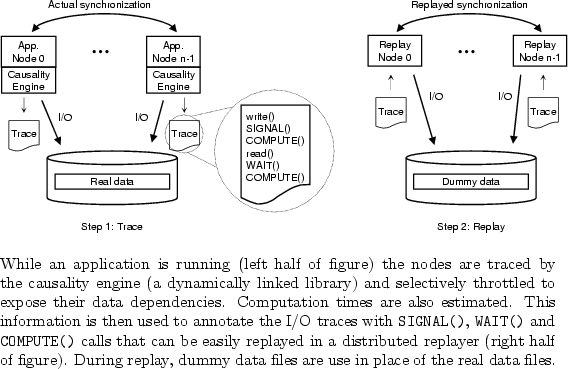
Trace collection is an iterative process, requiring that an application be run multiple times,
each time choosing a different node to throttle. Then, given a collection of traces (one
trace for each of ![]() application threads), a distributed replayer (
application threads), a distributed replayer (![]() replay threads, one per trace)
can replay the I/O, including any inter-I/O computation and synchronization, against
dummy data files. Figure 4 illustrates this high-level architecture.
replay threads, one per trace)
can replay the I/O, including any inter-I/O computation and synchronization, against
dummy data files. Figure 4 illustrates this high-level architecture.