
 |
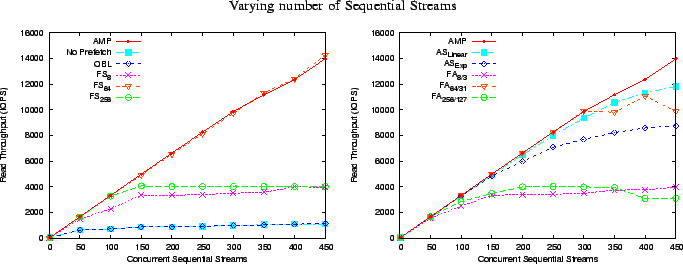
In Figure 9, we study the aggregate streaming
throughput of various prefetching algorithms when we increase the number of
concurrent sequential streams
while keeping the cache size constant. We observe that most algorithms
saturate at some throughput beyond which increasing the number of streams
does not improve the aggregate throughput. Algorithms that issue fewer
but larger disk reads and at the same time waste little generally do better.
We observe that no prefetching and OBL have the
lowest throughput as they have a large number of small read requests.
Somewhat better are the FA
![]() and FS
and FS
![]() algorithms
as they create fewer read requests than OBL. Interestingly,
FA
algorithms
as they create fewer read requests than OBL. Interestingly,
FA
![]() and FS
and FS
![]() algorithms also have similarly low performance
in spite of large prefetch degree. This is because the large prefetch degree
leads to significant prefetch wastage. The FS
algorithms also have similarly low performance
in spite of large prefetch degree. This is because the large prefetch degree
leads to significant prefetch wastage. The FS
![]() and FA
and FA
![]() perform the
best in their respective classes as they strike a balance and have large reads
but do not waste as much. The AS
perform the
best in their respective classes as they strike a balance and have large reads
but do not waste as much. The AS
![]() and AS
and AS
![]() are generally good
performers because they adapt the degree the prefetch. However, since these
algorithms lack the ability to detect and avoid wastage, the more aggressive AS
are generally good
performers because they adapt the degree the prefetch. However, since these
algorithms lack the ability to detect and avoid wastage, the more aggressive AS
![]() fares worse than its linear counterpart. AMP being an asynchronous
adaptive algorithm discovers the right prefetch degree for
each stream thus avoiding wastage and achieving the best possible performance.
fares worse than its linear counterpart. AMP being an asynchronous
adaptive algorithm discovers the right prefetch degree for
each stream thus avoiding wastage and achieving the best possible performance.
At the maximum number of streams, AMP outperforms the FA algorithms by ![]() -
-![]() %, the AS algorithms by
%, the AS algorithms by ![]() -
-![]() %,
the FS algorithms from nearly equal to
%,
the FS algorithms from nearly equal to ![]() % and no prefetching and OBL by a factor of
% and no prefetching and OBL by a factor of ![]() .
.