We make a conscious effort to avoid a separate data structure to track the
adapted values of ![]() and
and ![]() for each detected sequential stream. We
store the value of
for each detected sequential stream. We
store the value of ![]() and
and ![]() in the page data structure. This
removes any restriction on the number of streams that can be tracked.
in the page data structure. This
removes any restriction on the number of streams that can be tracked.
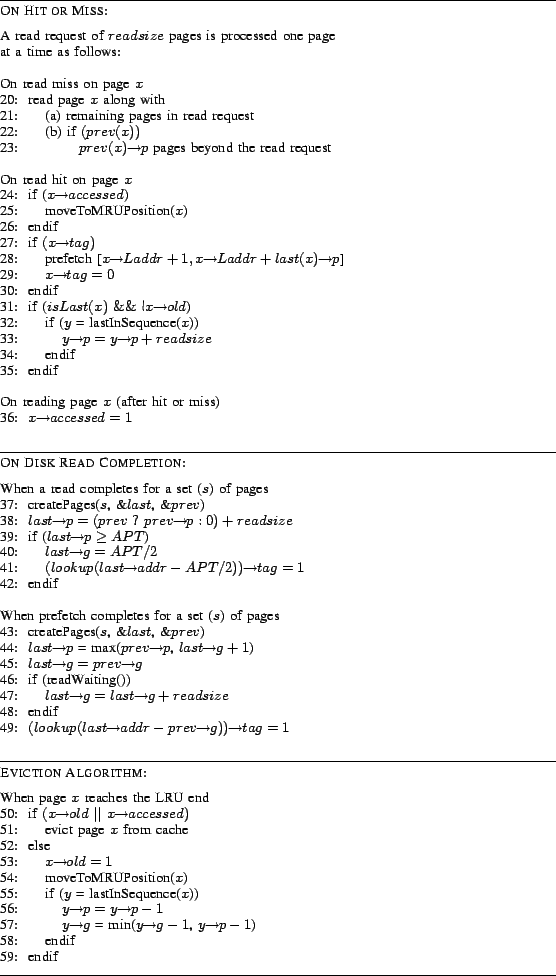
Lines 20-23 implement the synchronous prefetching component of the algorithm.
The number of pages to be prefetched on a read miss is not fixed
(as in FS algorithms) but is the adapted value of ![]() stored in the
metadata of the previous page.
stored in the
metadata of the previous page.
Whenever the current ![]() is
greater than the Asynchronous Prefetch Threshold (
is
greater than the Asynchronous Prefetch Threshold (![]() ),
asynchronous prefetching is activated.
),
asynchronous prefetching is activated.
![]() is set to an empirically reasonable value of
is set to an empirically reasonable value of ![]() .
A page at a distance of
.
A page at a distance of ![]() from the last page prefetched is chosen as the
prefetch trigger page and the
from the last page prefetched is chosen as the
prefetch trigger page and the
![]() is set (Lines 41, 49). When there is a hit on a
is set (Lines 41, 49). When there is a hit on a ![]() page,
the
page,
the ![]() is reset and an asynchronous prefetch is initiated for
is reset and an asynchronous prefetch is initiated for ![]() pages as specified in the last page
of the current set (Lines 27-30).
pages as specified in the last page
of the current set (Lines 27-30).
Adapting the degree of prefetch (p): As per Theorem III.1, we desire to
operate at a point where
![]() . If
. If ![]() is more than this optimal value,
the last page in a prefetched set will reach the LRU end unaccessed. We
give such a page another chance by moving it to the MRU position and setting the
is more than this optimal value,
the last page in a prefetched set will reach the LRU end unaccessed. We
give such a page another chance by moving it to the MRU position and setting the ![]() flag (Line 53).
Whenever an unaccessed page is moved to the MRU position in this way, it is an
indication that the current value of
flag (Line 53).
Whenever an unaccessed page is moved to the MRU position in this way, it is an
indication that the current value of ![]() is too high, and therefore,
we reduce the value of
is too high, and therefore,
we reduce the value of ![]() (Line 56).
In Lines 31-35,
(Line 56).
In Lines 31-35, ![]() is incremented by the
is incremented by the ![]() (the size of read request
is pages) whenever there is
a hit on the
(the size of read request
is pages) whenever there is
a hit on the ![]() page of a read set (pages read in the same I/O)
which is also not marked
page of a read set (pages read in the same I/O)
which is also not marked ![]() .
.
Adapting the trigger distance (g): The main idea is to increment
![]() if on the completion of a prefetch we find that a read is
already waiting for the first page within the prefetch set (readWaiting()).
If
if on the completion of a prefetch we find that a read is
already waiting for the first page within the prefetch set (readWaiting()).
If ![]() was larger, the prefetch would have been issued earlier, reducing or eliminating the stall time for the read.
Thus, we increment
was larger, the prefetch would have been issued earlier, reducing or eliminating the stall time for the read.
Thus, we increment ![]() in Line 47. However, we also need to decrement
in Line 47. However, we also need to decrement
![]() when
when ![]() itself is being decremented (Line 57).
This keeps
itself is being decremented (Line 57).
This keeps
![]() as per Lemmas III.1, III.2.
as per Lemmas III.1, III.2.
Whenever we adapt the value of ![]() and
and ![]() we store the updated values in the last
page that has been read into the cache for the sequence. This is located
by the lastInSequence(
we store the updated values in the last
page that has been read into the cache for the sequence. This is located
by the lastInSequence(![]() ) method in Lines 11-19. The method simply returns the
last page of the set that
) method in Lines 11-19. The method simply returns the
last page of the set that ![]() belongs to, or if the next set of pages
has also been prefetched, it returns the last page of the next
set. The logic is to keep the adapted values of
belongs to, or if the next set of pages
has also been prefetched, it returns the last page of the next
set. The logic is to keep the adapted values of ![]() and
and ![]() in the page that
is most recently added to the cache and is thus most likely to stay in the
cache for the longest time. In the unlikely case where the
adapted values of
in the page that
is most recently added to the cache and is thus most likely to stay in the
cache for the longest time. In the unlikely case where the
adapted values of ![]() and
and ![]() are forgotten because of page evictions,
we set
are forgotten because of page evictions,
we set ![]() to the current prefetch size, and set
to the current prefetch size, and set ![]() to half of
to half of ![]() .
.
Since AMP adapts to discover the optimal values of ![]() and
and ![]() ,
it incurs a minor cost of adaptation which quickly becomes
negligible and allows it achieve near optimal performance.
,
it incurs a minor cost of adaptation which quickly becomes
negligible and allows it achieve near optimal performance.
In the eviction part of the algorithm (Lines 50-59),
pages that are ![]() or
or ![]() are evicted from the LRU end.
Finally, we always make sure that
are evicted from the LRU end.
Finally, we always make sure that
![]() (Lines 44, 57) and
(Lines 44, 57) and
![]() (a reasonable
(a reasonable ![]() pages for all algorithms).
pages for all algorithms).