|
||||||||||||||
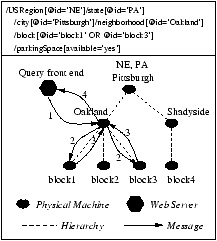
2.1 Wide-Area Sensing ServicesWe consider representative services from five classes of wide-area sensing services, as summarized in Table 1:Asset Tracker: This service is an example of a class of services that keeps track of objects, animals or people. It can help locate lost items (pets, umbrellas, etc.), perform inventory accounting, or provide alerts when items or people deviate from designated routes (children, soldiers, etc.). Tracking can be done visually with cameras or by sensing RFID tags on the items. For large organizations such as Walmart or the U.S. Military, the global database may be TBs of data. Ocean Monitor: This service is an example of a class of environmental monitoring services that collect and archive data for scientific studies. A concrete example is the Argus coastal monitoring service [2, 18], which uses a network of cameras overlooking coastlines, and analyzes near-shore phenomena (riptides, sandbar formation, etc.) from collections of snapshot and time-lapse images. Parking Finder: This service monitors the availability of parking spaces and directs users to available spaces near their destination (see, e.g., [14, 18]). It is an example of a class of services that monitors availability or waiting times for restaurants, post offices, highways, etc. Queriers tend to be within a few miles of the source of the sensed data, and only a small amount of data is kept for each item being monitored. Network Monitor: This service represents a class of distributed network monitoring services where the ``sensors'' monitor network packets. A key feature of this service is the large volume of writes. For example, a network monitoring service using NetFlow [4] summarization at each router can generate 100s of GBs per day [16]. We model our Network Monitor service after IrisLog [18, 7]. IrisLog maintains a multi-resolution history of past measurements and pushes the distributed queries to the data. Epidemic Alert: This service monitors health-related phenomena (number of people sneezing, with fevers, etc.) in order to provide early warnings of possible epidemics (see, e.g., [3]). When the number of such occurrences significantly exceeds the norm, an alert is raised of a possible epidemic. We use this service to consider a trigger-based read-write workload in which each object in the hierarchy reports an updated total to its parent whenever that total has changed significantly, resulting in a possible cascading of updates. Trigger-based workloads have not been considered previously in the context of data placement, but they are an important workload for sensing services. A Qualitative Characterization. In Table 1, we characterize qualitatively the five representative services along seven dimensions. Global DB Size is the size of the global database for the service. Note that for Ocean Monitor, it includes space for a full-fidelity historical archive, as this is standard practice for oceanography studies. For Network Monitor, it includes space for a multi-resolution history. In order to provide different points of comparison, for the remaining services, we assume only the most recent data is stored in the database.2 Write Rate is the rate at which objects are updated in the global database. We assume services are optimized to perform writes only when changes occur (e.g., Parking Finder only writes at the rate parking space availability changes). Read/Write Ratio is the ratio of objects read to objects written. A distinguishing characteristic of sensing services is that there are typically far more writes than reads, as far more data is generated than gets queried. An exception in our suite is Epidemic Alert, because we view each triggered update as both a read and a write. Read Burstiness refers to the frequency and severity of flash crowds, i.e., large numbers of readers at an object in a short window of time. For example, Parking Finder has flash crowds right before popular sporting events. Read Skewness is measured in two dimensions: the geographic scope of the typical query (e.g., parking queries are often at the neighborhood level) and the uniformity across the objects at a given level (e.g., parking queries are skewed toward popular destinations). R/W Proximity reflects the typical physical distance from the querier to the sensors being queried, as measured by the lowest level in the hierarchy they have in common. For example, an oceanographer may be interested in coastlines halfway around the world (root level proximity), but a driver is typically interested only in parking spaces within a short drive (neighborhood level proximity). Consistency refers to the typical query's tolerance for stale (cached) data. 2.2 Sensing System ArchitectureWe now describe the architecture of a generic wide-area sensing system on which the above services can be built. At a high level, a sensing system consists of three main components.Data Collection. This component collects data from the sensors, which may be cameras, RFID readers, microphones, accelerometers, etc. It also performs service-specific filtering close to the sensors, in order to reduce high-bit-rate sensed data streams (e.g., video) down to a smaller amount of post-processed data. In IrisNet, for example, this component is implemented as Sensing Agents (SAs) that run on Internet-connected hosts, each with one or more attached sensors. The post-processed data is stored as objects in the data storage component, described next. Data Storage. This component stores and organizes the data objects so that users can easily query them. Because of the large volume of data and because objects are queried far less frequently than they are generated, a scalable architecture must distribute the data storage so that objects are stored near their sources. Sensed data are typically accessed in conjunction with their origin geographic location or time. Organizing them hierarchically, e.g., according to geographic and/or political boundaries, is therefore natural for a broad range of sensing services. We assume that each sensing service organizes its data in its own hierarchies, tailored to its common access patterns. For example, the data of the Parking Finder may be organized according to a geographic hierarchy (for efficient execution of common queries seeking empty parking spots near a given destination), while data in an Ocean Monitor may further be organized according to timestamps (supporting queries seeking all riptide events in the year 2004).3 Thus, the storage component of a sensing system provides a hierarchical distributed database for a sensing service. Let the global database of a service denote a sensor database built from the complete hierarchy for a service and the data collected from all the sensors used by that service. A host in the sensing system contains a part of this database, called its local database. Thus, each sensing service has exactly one global database, which can be distributed among multiple hosts. However, each host may own multiple local databases, one for each sensing service using the host. In IrisNet, for example, this storage component is implemented as Organizing Agents (OAs) that run on Internet-connected hosts. The global database is represented as a single (large) XML document whose schema defines the hierarchy for the service. Note that the hierarchy is logical---any subset of the objects in the hierarchy can be placed in a host's local database. Query Processing. A typical query selects a subtree from the hierarchy. The query is then routed over the hierarchy, in a top-down fashion, with the query predicates being evaluated at each intermediate host. The hierarchy also provides opportunities for in-network aggregation---as the data objects selected by the query are returned back through the hierarchy, each intermediate host aggregates the data sent by its children and forwards only the aggregated results. For example, a query for the total value of company assets currently within 100 miles of a given disaster is efficiently processed in-network by first summing up the total asset value within each affected building in parallel, then having these totals sent to each city object for accumulation in parallel, and so on up the object hierarchy. This technique, widely used in wireless sensor networks [31], is also used in a few existing wide-area sensing systems [14, 17, 39]. For example, in IrisNet, a query is specified in XPATH [43], a standard language for querying an XML document. Figure 2 shows a portion of an example hierarchy (for a Parking Finder service), a partitioning of the hierarchy among hosts (OAs), and an example of how queries are routed on that particular partitioning. The hierarchy is geographic, rooted at NE (the northeastern United States), continuing downward to PA (state), Pittsburgh (city), Oakland and Shadyside (neighborhoods), and then individual city blocks within those neighborhoods. In the figure, a single physical host holds the NE, PA, and Pittsburgh objects (i.e., the data related to the corresponding regions). The (XPATH) query shown is for all available parking spaces in either block 1 or block 3 of Oakland. The query is routed first to the Oakland host, which forwards subqueries to the block 1 and block 3 hosts, which respond to the Oakland host, and finally the answer is returned to the query front-end. In general, a query may require accessing a large number of objects in the hierarchy in a specific top-down order, and depending on how the hierarchy is partitioned and placed, the query may visit many physical hosts.
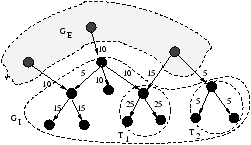
3 The Adaptive Data Placement ProblemIn this section, we describe the adaptive data placement problem, motivated by the characteristics of wide-area sensing services.3.1 Data Placement ChallengesBased on the discussion so far, we summarize the distinguishing challenges and constraints for adaptive data placement for wide-area sensing services as follows:Data Access Pattern. The data access patterns for wide-area sensing are far more complex than traditional distributed file systems or content distribution networks. First, the in-network aggregation within a hierarchically-organized database requires that different parts of the database be accessed in a particular order and the data be transmitted between the hosts containing the data. Moreover, in-network aggregation updates may be trigger-based. Second, different queries may select different, possibly overlapping, parts of the hierarchy. As a result, the typical granularity of access is unknown a priori. Dynamic Workload. Since many different sensing services can share the same set of hosts, even the high-level access patterns to the hosts are not known a priori. Moreover, the read and write load patterns may change over time and, in particular, the read load may be quite bursty. For example, after an earthquake, there may be a sudden spike in queries over sensed data from the affected geographic region. The data placement should quickly adapt to workload dynamics. Read/Write Workload. With millions of sensors constantly collecting new readings, the aggregate update rate of the sensor database is potentially quite high (e.g., 100s of GB per day for Network Monitor). Moreover, the number of writes is often an order of magnitude or more greater than the number of reads. Thus, any placement must consider the locations of the writers--not just the readers--and the number of replicas is constrained by the high cost of updating the replicas. Capacity Constraints. Each object has a weight (e.g., storage requirement, read and write load) and each host has a capacity (e.g., storage, processing power) that must be respected. Wide-area Distribution. The sensors and queriers may span a wide geographic area. On the other hand, many services have high R/W proximity. Thus, data placement must be done carefully to minimize communication costs and exploit any proximity. Consistency and Fault Tolerance. Each service's consistency and fault tolerance requirements must be met. Based on our representative services, we assume best effort consistency suffices. (Note that most data have only a single writer, e.g., only one sensor updates the availability of a given parking space.) For fault tolerance, we ensure a minimum number of replicas of each object. 3.2 Problem Formulation and HardnessTo capture all these aspects, we formalize the data placement problem for wide-area sensing services as follows. Given a set of global databases (one for each service), the hosts where data can be placed, a minimum number of copies required for each object, and the capacities (storage and computation) of the hosts, adapt to the dynamic workload by determining, in an online fashion, (1) the local databases, possibly overlapping, to be placed at different hosts, and (2) the assignments of these local databases to the hosts such that the capacity of each host is respected, the minimum number of copies (at least) is maintained for each object, the average query latency is low, and the wide-area traffic is low.Given the complexity of this task, it is not surprising that even dramatically simplified versions of this problem are NP-hard. For example, even when there is an unbounded number of hosts, all hosts have the same capacity C, all pairs of hosts have the same latency, the query workload is known, and there are no database writes, the problem of fragmenting a global database into a set of fragments of size at most C, such that the average query latency is below a given threshold, is NP-hard.4 Because the global hierarchical database can be abstracted as a tree, selecting fragments is a form of graph (tree) partitioning and assigning fragments is a form of graph (tree) embedding. Many approximation algorithms have been proposed for graph partitioning and graph embedding problems (e.g., in the VLSI circuit optimization literature [25, 38]). None of these proposed solutions address the complex problem we consider. However, we get the following two (intuitive) insights from the existing approximation algorithms, which we use in IDP. First, the final partitions are highly-connected clusters. If, as in our case, the given graph is a tree, each partition is a subtree of the graph. Second, if the edges are weighted (in our case, the weights reflect the frequency in which a hop in the object hierarchy is taken during query routing), and the objective is to minimize the cost of the edges between partitions, most of the heavy edges are within partitions. 4 IDP AlgorithmsDue to the complexity of optimal data placement, IDP relies on a number of practical heuristics that exploit the unique properties of sensing services. Our solution consists of three simplifications. First, each host selects what parts of its local database to off-load using efficient heuristics, instead of using expensive optimal algorithms. Second, each host decides when to off-load or replicate data independently, based on its local load statistics. Finally, to mitigate the suboptimal results of these local decisions, we use placement heuristics that aim to yield ``good'' global clustering of objects. These three components, called Selection, Reaction, and Placement respectively, are described below.4.1 Fragment SelectionThe selection component of IDP identifies the fragments of its local database (i.e., the sets of objects) that should be transferred to a remote host. The fragments are selected so as to decrease the local load below a threshold while minimizing the wide-area traffic for data movement and queries. At a high level, fragment selection involves partitioning trees. However, previous tree partitioning algorithms [30, 38] tend to incur high computational costs with their O(n3) (n = number of objects) complexity, and hence prevent a host from shedding load promptly. For example, in IrisNet, using a 3 GHz machine with 1 GB RAM, the algorithms in [30, 38] take tens of minutes to optimally partition a hierarchical database with 1000 objects. Such excessive computational overhead would prevent IDP from shedding load in a prompt fashion. On the other hand, trivial algorithms (e.g., the greedy algorithm in Section 7.1.1) do not yield ``good'' fragmentation. To address this limitation, we exploit properties of typical query workloads to devise heuristics that provide near optimal fragmentation with O(n) complexity. We call our algorithm Post (Partitioning into Optimal SubTrees). As a comparison, under the same experimental setup used with the aforementioned optimal algorithms, Post computes the result in a few seconds. Below we describe the algorithm.Database Partitioning with Post. We use the following terminology in our discussion. For a given host, let GI denote the set of (Internal) objects in the local database, and GE denote the set of non-local (External) objects (residing on other hosts) and the set of query sources. Define the workload graph (Figure 3) to be a directed acyclic graph where the nodes are the union of GI and GE, and the edges are pointers connecting parent objects to child objects in the hierarchy and sources to objects. Under a given workload, an edge in the workload graph has a weight corresponding to the rate of queries along that edge (the weight is determined by locally collected statistics, as described in Section 6.1). The weight of a node in GI is defined as the sum of the weights of all its incoming edges (corresponding to its query load) and the weights of all its outgoing edges to nodes in GE (corresponding to its message load). For any set T of objects within GI, we define T's cost to be the sum of the weights of nodes in T. The cutinternal of T is the total weight of the edges coming from some node in GI to some node in T, and it corresponds to the additional communication overhead incurred if T were transferred. The cutexternal is the total weight of the edges coming from some node in GE to some node in T, and it corresponds to the reduction of load on the node if T were transferred. In Figure 3, the cutinternal of T1 is 10, while the cutexternal is 15. Intuitively, to select a good fragment, we should minimize cutinternal (achieved by T2 in Figure 3) so that it introduces the minimum number of additional subqueries or maximize cutexternal (achieved by T1 in Figure 3) so that it is the most effective in reducing external load. To design an efficient fragmentation algorithm for sensing services, we exploit the following important characteristics in their workloads: A typical query in a hierarchical sensor database accesses all objects in a complete subtree of the tree represented by the database, and the query can be routed directly to the root of the subtree. This observation is well supported by the IrisLog [7] query trace (more details in Section 7), which shows that more than 99% of user requests select a complete subtree from the global database. Moreover, users make queries on all the levels in the hierarchy, with some levels being more popular than the others. Under such access patterns, the optimal partition T is typically a subtree. The reason is that transferring only part of a subtree T from a host H1 to another host H2 may imply that a top-down query accesses objects in H1 (the top of T) then in H2 (the middle of T) and then back in H1 (the bottom of T), resulting in a suboptimal solution. The above observation enables Post to restrict the search space and run in linear time. Post sequentially scans through all the nodes of the workload graph, and for each node it considers the whole subtree rooted at it. For all the subtrees with costs smaller than the given capacity C, it outputs the one with the optimal objective. The search space is further decreased by scanning the nodes in the workload-graph in a bottom-up fashion, thus considering the lower cost subtrees near the leaves before the higher cost subtrees further up the tree. As mentioned before, in typical settings, Post takes a few seconds to run. Yet, as we will show in Section 7.1.1, the quality of the resulting fragmentation, in practice, is very close to that of the O(n3) optimal algorithms that take tens of minutes to run. IDP uses Post with different objective functions for different situations. For example, Post could choose the subtree that maximizes the value of cutexternal. In Figure 3, T1 denotes such a fragment. Replicating or splitting such fragments would be effective in reducing the external load on the host. Note that this objective tends to choose large fragments since cutexternal increases with size. Alternatively, Post could minimize the value of cutinternal. In Figure 3, T2 denotes such a fragment. Splitting such fragments would minimize any resulting increase in the host hop counts of queries. Unfortunately, this objective tends to pick small fragments which may slow down the load shedding. To avoid this, Post only considers fragments of size greater that C/2, where C is a parameter (discussed next) specifying the cost of the fragments Post must select. Parameters of Post. IDP must choose a value for C to pass to the Post algorithm. C can be chosen to be the smallest amount Cmin of load whose removal makes the host underloaded. This minimizes the network traffic cost of data placement, but the host may become overloaded again easily. A C far greater than Cmin would protect the host from overload but increase the overhead and duration of a load shedding event. This choice is equivalent to having two thresholds in the system: the load shedding is triggered when the load is above a high-watermark threshold Thhigh, and at that point the load is shed until the load goes below a low-watermark threshold Thlow. In addition to these two thresholds, IDP uses a deletion threshold Thdel that characterizes the lowest load at an object replica that still justifies retaining that replica. Load Estimation. Each host needs to monitor its load in order to decide when to start shedding load. The load could be estimated using an exponentially-decaying average, Lavg, of the instantaneous loads, Li, on all the objects in the local database. However, after shedding load, Lavg overestimates the actual load for a while, because its time-decaying average is unduly inflated by the load just prior to shedding. As a result, unwarranted further shedding could occur repeatedly. A possible fix would be to prevent the host from shedding load until Lavg becomes valid; however, this approach would react too slowly to increasing flash crowds. Instead, we adapt a technique used by TCP to estimate its retransmission time out values [20]. We maintain the exponentially-decaying average, Vavg, of the value |Lavg - Li|, and then estimate the load as Lavg - 2Vavg, until Lavg again becomes valid. Our experiments show that this provides a stable estimate of a host's local load. 4.2 ReactionIn IDP, hosts exchange database fragments in order to adapt to changing workloads, using the following four operations:
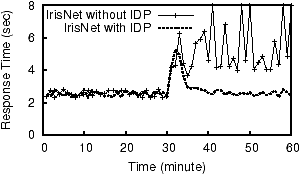
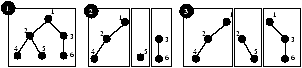
4.3 Fragment PlacementGiven a fragment and its load information, IDP must find, through a suitable discovery mechanism, a host that can take the extra load. The simplest approach selects a random host capable of taking the extra load. However, this may require a query to visit multiple hosts, increasing query latency. Therefore, we use two heuristics that exploit the query and data source characteristics to improve the overall performance.The first heuristic uses our previous observation that subtrees of the global database should be kept as clustered as possible. Thus the host discovery component first considers the neighboring hosts as possible destinations for a fragment. A host H1 is a neighbor of fragment f if H1 owns an object that is a parent or a child of some object in f. A host H2, trying to split or replicate a fragment, f, first sees if any of the neighboring hosts of f can take the extra load, and if such a host is found, f is sent to it. If more than one neighboring host is capable of taking the extra load, then the one having the highest adjacency score is chosen. The adjacency score of a host H1 with respect to the fragment f is the expected reduction of read traffic (based on local statistics) if f is placed in H1. This helps maintain large clusters throughout the system. When no suitable neighboring host is found, IDP's second heuristic searches for the host capable of taking the extra load that is the closest to the optimal location among all such hosts. The optimal location for an object is the weighted mid-point of its read and write sources. We account for the location of sources using the GNP [34] network mapping system. Specifically, each component of the sensing system (sensor, host, or client web interface) has GNP coordinates, and the cartesian distance between hosts is used to estimate the latency between them. If the read and write loads of an object are R and W, and the average read and write source locations are GNPread and GNPwrite, then the optimal location is given by GNPopt = R � GNPread + W � GNPwrite/R+W. The optimal location of a fragment is the average of the optimal locations of all the objects in the fragment. 4.4 A Simple RunIntuitively, IDP achieves its goal by letting hosts quickly readjust their loads by efficiently partitioning or replicating objects and by keeping the neighboring objects clustered. We illustrate a simple run of IDP in Figure 4. Rectangular boxes represent hosts and the trees represent their local databases. Initially the global database is placed at one host (1), which experiences high read and write load. To shed write load the host then determines two fragments (one containing object 5 and the other containing objects 3 and 6) for splitting. The fragments are then placed at newly-discovered hosts near the write sources (2). To shed read load, it then determines two more fragments and places them in hosts already owning objects adjacent to the fragments (3).
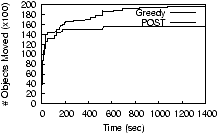
5 Replica Selection During QueriesWhile processing a query, if a host's local database does not contain some objects required by the query, subqueries are generated to gather the missing objects. Because the global database is split or replicated at the granularity of individual objects, IDP can route subqueries to any of the replicas of the required objects. Two simple replica selection strategies are proximity selection that selects the closest replica and random selection that selects a random replica. However, as we will show in Section 7, these simple strategies are not very effective for sensing services. For example, in the presence of read-locality, proximity selection fails to shed load from the closest (and the most overloaded) replica. Therefore, we use the following randomized selection algorithm.Randomized Response-Time Selection. Another possible policy is to select the replica with the smallest expected response time (network latency plus the host processing time). Each host models the response time of the replicas using the moving averages of their previous actual response times. Note that when the load of all the replicas are similar (i.e., their host processing times are comparable), the choice is determined by network latencies. This may cause load oscillation of the optimally placed host due to a herd effect [13]. To avoid this oscillation, we instead use the following randomized response-time (RRT) algorithm. Each host, when it contacts a replica ri, measures its response times and uses them to estimate ri's expected response time ei. Suppose a host is considering the replicas in increasing order of response time, r1, r2, ..., rn. The algorithm assigns a weight wi to replica ri according to where ei falls within the range e1 to en as follows: wi = (en - ei)/(en - e1). Finally it normalizes the weights to compute the selection probability pi of ri as pi = wi/�j wj. Note that if all the hosts are similarly loaded, RRT prefers nearby replicas. If the replicas are at similar distances, RRT prefers the most lightly-loaded host. In addition, the randomization prevents the herd effect. 6 Implementation DetailsWe now sketch our implementation of IDP in IrisNet, including the various modules and parameter settings.6.1 Implementation in IrisNetOur implementation of IDP consists of three modules.The Stat-Keeper Module. This module runs in each IrisNet OA (i.e., at each host). For each object, we partition its read traffic into internal reads, in which the object is read immediately after reading its parent on the same OA, and external reads, in which a (sub)query is routed directly to the object from the user query interface or another OA. For each object in an OA's local database, the stat-keeper maintains (1) the object's storage requirements, (2) its external read load, defined as an exponentially-decaying average of the rate of external reads, (3) its internal read load, defined as an exponentially-decaying average of the rate of internal reads, (4) its (external) write load, defined as an exponentially-decaying average of the rate of writes, (5) GNPread, and (6) GNPwrite. (GNPread and GNPwrite are defined in Section 4.3.) Moreover, the stat-keeper maintains the current size, aggregate read load, and aggregate write load for each local database. When an OA with multiple local databases (from multiple co-existing services) incurs excessive load, the local database with maximum size or load sheds its load. The module is implemented as a light weight thread within the query processing component of the OA. On receiving a query or an update, the relevant statistics (maintained in the main memory) are updated, incurring very negligible overhead (<1% CPU load). The Load Adjusting Module. This module is at the center of IDP's dynamic data placement algorithm. It uses different statistics gathered by the stat-keeper module, and when the OA is overloaded, performs the tasks described in Section 4.1 and Section 4.2. The OA Discovery Module. This module performs the tasks described in Section 4.3 and acts as a matchmaker between the OAs looking to shed load and the OAs capable of taking extra load. Currently, the first heuristic described in Section 4.3 (selecting neighboring nodes) is implemented in a distributed way. Each OA exchanges its current load information with its neighboring OAs by piggybacking it with the normal query and response traffic. Thus each OA knows how much extra load each of its neighboring OAs can take, and can decide if any of these OAs can accept the load of a replicated or split fragment. The second heuristic (selecting optimally located nodes), however, is implemented using a centralized directory server where underloaded OAs periodically send their location and load information. Our future work includes implementing this functionality as a distributed service running on IrisNet itself. 6.2 Parameter SettingsWe next present the tradeoffs posed by different Post parameters and their settings within our implementation. The values are chosen based on experiments with our implementation subjected to a real workload (more details in Section 7.1 and in [33]).Watermark Thresholds. The value of the high watermark threshold Thhigh is set according to the capacity of an OA (e.g., the number of objects per minute that can be processed by queries). The value of the low watermark threshold Thlow poses the following tradeoff. A smaller value of Thlow increases the data placement cost (and the average response time) due to increased fragmentation of the global database. However, a larger value of Thlow causes data placement thrashing, particularly when the workload is bursty. Our experiments in [33] show that a value of Thlow = 4/5Thhigh provides a good balance among different degrees of burstiness. Deletion Threshold. The deletion threshold Thdel for an object presents additional trade-offs. A small Thdel keeps replicas even if they are not required. This increases the local database size and hence the OA processing time.5 A high Thdel can remove replicas prematurely, increasing the data placement cost. Based on our experiments, we set the threshold such that an object gets deleted if it receives no queries in the past 30 minutes (and the object has more than the minimum number of replicas). We use these parameter settings in our experiment evaluation, discussed next. 7 Experimental EvaluationOur evaluation consists of the following two steps. First, we use a real workload with our deployment of IDP (within IrisNet) running on the PlanetLab to study how IDP's different components work in practice. Then, we use simulation and synthetic workloads to understand how sensitive IDP is to different workloads.7.1 Performance in Real DeploymentIn this section, we evaluate IDP using IrisLog, an IrisNet-based Network Monitor application deployed on 310 PlanetLab hosts. Each PlanetLab host in our deployment runs an IrisNet OA. Computer programs running on each PlanetLab host collect resource usage statistics, and work as sensors to report to the local OA once every 30 seconds. We drive our evaluation by using IrisLogTrace, a real user query trace6 collected from our IrisLog deployment on the PlanetLab from 11/2003 to 8/2004 (Table 2). Because the trace is relatively sparse, we replay this trace with a speedup factor, defined as the ratio between the original duration of the trace and the replay time. For the experiments requiring longer traces than what we have, we concatenate our trace to construct a longer trace. At the beginning of each experiment, the global database is randomly partitioned among a small group of hosts. As the workload is applied, IDP distributes the database among the available hosts, with the data placement costs decreasing over time. We say that the system has reached initial steady state if, under our reference workload, no data relocation occurs within a period of 2 hours. We experimentally ensured that this choice of period was reasonable. In all our experiments, we measure the cost of data placement from the very beginning of the experiment, while all other metrics (e.g., response time) are measured after the system has reached its initial steady state, at which point the specific workload to be studied is started.Figure 1 demonstrates the overall performance of IDP. As shown, IDP helps IrisNet maintain reasonable response times even under a high flash-crowd. Without IDP, IrisNet becomes overloaded and results in high response times and timeouts. We now evaluate the individual components of IDP.
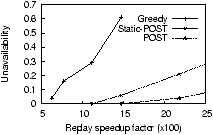
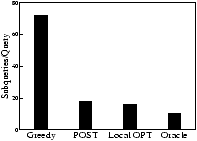
7.1.1 Partitioning HeuristicsThis section evaluates Post and compares it with three hypothetical algorithms: Greedy, LocalOPT and Oracle. In Greedy, overloaded hosts evict individual objects in decreasing order of their loads. As a result, hosts make decisions with finer granularity, but do not try to keep the hierarchical objects clustered. In LocalOPT, each host partitions its XML fragment using an optimal tree partitioning algorithm [30] with O(n3) complexity. However, because each invocation of LocalOPT takes tens of minutes of computation time, we do not use it in our live experiments on the PlanetLab. Oracle is an offline approach that takes the entire XML database and the query workload and computes the optimal fragmentation (again, using the algorithm in [30]). Oracle cannot be used in a real system and only serves as a lower bound for comparison purposes.Our evaluation consists of two phases. In Phase 1, we fragment the IrisLog database by using all but the last 1000 queries of IrisLogTrace as warm-up data. To do this within a reasonable amount of time, we perform this phase on the Emulab testbed [6] on a LAN. This enables us to use a large speedup factor of 1200 and finish this phase in a short period of time. We also assign each Emulab host its GNP coordinates that can be used to model the latency between any two emulated hosts if required. In Phase 2 of our experiment, we place the fragments created in Phase 1 in our PlanetLab deployment and inject the last 1000 queries from IrisLogTrace. To understand the advantage of Post's adaptive fragmentation, we also use Static-Post which, under all speedup factors, starts from the same warm-up data (generated from Phase 1 with a speedup factor of 1200) and does not further fragment the database during Phase 2. Figure 5(a) plots the cumulative overhead of the fragmentation algorithms over time during the warm-up phase of the experiment. The graph shows that the amount of fragmentation decreases over time, which means that our load-based invocations of the algorithms do converge under this workload. Greedy incurs higher overhead than Post because Greedy's non-clustering fragmentation increases the overall system load which makes the hosts fragment more often. We do not use LocalOPT or Oracle in this experiment due to their excessive computation overhead. Replaying IrisLogTrace with a high speedup factor on IrisLog overloads the hosts. Because of this overload, the response of a typical query may return only a fraction of the requested objects. The remaining objects reside in overloaded hosts that fail to respond to a query within a timeout period (default 8 seconds in IrisNet). We define the unavailability of a query to be the fraction of the requested objects not returned in the answer. Figure 5(b) shows the average unavailability of IrisLog under different fragmentation algorithms and under different speedup factors. Greedy is very sensitive to load and suffers from high unavailability even under relatively smaller speedup factors (i.e., smaller load). This is because Greedy produces suboptimal fragments and overloads the system by generating a large number of subqueries per query (Figure 5(c)). Post is significantly more robust and it returns most objects even at a higher speedup factor. The effectiveness of Post comes from its superior choice of fragments, which generate a near optimal number of subqueries (as shown in Figure 5(c)). The difference between Static-Post and Post in Figure 5(b) demonstrates the importance of adaptive load-shedding for better robustness against a flash-crowd-like event.
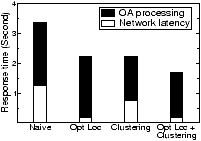
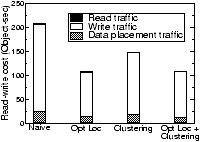
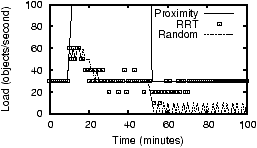
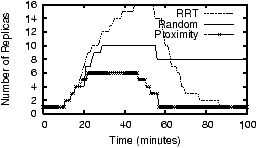
7.1.2 Data Placement HeuristicsWe now evaluate the effectiveness of different heuristics described in Section 4.3 for choosing a target host for a fragment. The heuristics are compared to the naive approach of choosing any random host that can accept the extra load. We start this experiment by placing the fragments generated by Phase 1 of the previous experiment and then replaying the last 1000 queries from IrisLogTrace with a moderate speedup factor. In different settings, we use a different combination of placement heuristics. We represent the cost of a data transfer using the metric object-sec, which is the product of the number of objects transferred and the latency between the source and the destination. Intuitively, this metric captures both the amount of data transferred and the distance over which it is transferred. The results of this experiment are shown in Figure 6. As mentioned before, response times and read/write traffic are computed only in the second phase of the experiment (done on the PlanetLab), while the data placement cost includes the cost incurred in both phases.The first heuristic Opt Loc, choosing a host near the optimal location, reduces network latency and traffic, as shown in Figure 6. The second heuristic Clustering, choosing a neighboring host, reduces the number of hops between hosts. This is due to the fact that the heuristic increases the average cluster size (25% increase on average in our results). To achieve the best of both heuristics, we use them together as follows. Because host processing time dominates network latency, we first try to find a neighboring host capable of taking the extra load; only if no such host exists, we use the second heuristic to find a host near the optimal location. This has the following interesting implication: because the read and write sources of the objects that are adjacent in the global database are expected to be nearby (because of read-write locality of sensor data), first placing an object in the optimal host and then placing the adjacent objects in the same host automatically places the objects near the optimal location. As shown in the graph, the combination of the two heuristics reduces the total response time and read network traffic, with a slight increase in write network traffic. Also note that the data placement cost is many times smaller than the read/write cost, showing that IDP has little overhead. 7.1.3 Replica Selection HeuristicsTo demonstrate the effect of different replica selection heuristics, we do the following experiment. We place a fragment in a host H on the PlanetLab. We start issuing queries from a nearby location so that H is the optimal host for the reader. At time t<10, the load of the host is below the threshold ( = 35, the maximum load H can handle). At t=10, we increase the query rate by a factor of 10. This flash crowd exists until t=50, after which the read load drops below the threshold. As the query rate increases, the host creates more and more replicas. In different versions of this experiment, we use different heuristics to select a replica to which the query is sent. We plot the load of the host H and the number of replicas at different times in Figure 7.With proximity-based replica selection, host H becomes overloaded and creates new replicas. However, as expected, all the load shedding efforts are in vain because all the queries continue to go to H. As the figure shows, its current load promptly goes up (the peak value 400 is not shown in the graph) while all the newly created replicas remain unused and eventually get deleted. With random selection, the load is uniformly distributed among the replicas. As shown in Figure 7, as the load increases, fragments are replicated among the hosts until the load of each host goes below the threshold (t=20). However, after the flash crowd disappears (t=50), all the replicas still get the same equal fraction of the total load. In this particular experiment, at t= 51, the average load of each replica is slightly below the threshold used for deletion of objects. Because of the randomized deletion decision, two replicas get deleted at t=57. This raises the average load of each replica above the deletion threshold. As a result, these replicas remain in the system and consume additional resources (Figure 7(b)). Randomized response-time (RRT) selection shows the same good load balancing properties of random selection. Moreover, after the flash crowd disappears, the replica at the optimal location gets most of the read load. Thus, the other replicas become underloaded and eventually get deleted. Furthermore, because RRT incorporates estimated response times of replicas in its replica selection, it significantly reduces the query response time (by around 25% and 10% compared to proximity-based and random selection, respectively). This demonstrates the effectiveness of RRT for sensing services.
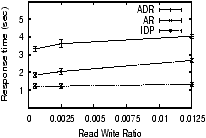
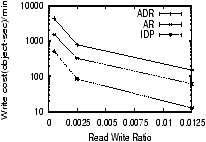
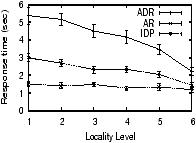
7.2 Sensitivity Analysis with SimulationWe now use simulation to understand how IDP performs as the different parameters of the workload change. Our IrisNet simulator enables us to use a larger setup (with 10,000 hosts) than our PlanetLab deployment of IrisLog. Each simulated host is given multi-dimensional coordinates based on measurements from the GNP [34] network mapping system, and the cartesian distance between hosts estimates the latency between them. We use the GNP coordinates of the 867 hosts from [34]. Because the simulated hosts and sensors outnumber the available GNP coordinates by two orders of magnitude, we emulate additional GNP coordinates by adding small random noise to the actual GNP coordinates. To approximate the geographic locality of sensors, we make sure that sensors that report to sibling leaf objects are assigned nearby GNP coordinates (e.g., the sensors that report to block 1, 2, and 3 of Oakland have nearby coordinates). The simulator does not model the available bandwidth between hosts in the network. However, most messages are small and, therefore, their transmission times will be limited more by latency than by bandwidth. Unless otherwise stated, we use IrisLogTrace with an appropriate speedup factor for our read workload. For our write workload, we assume that every sensor reports data once every 30 seconds.We compare IDP with the following existing adaptive data placement approaches. In the first approach, aggressive replication (AR), a host maintains replicas of the objects it has read from other hosts. The second approach, adaptive data replication (ADR), uses the algorithm proposed in [41]. Although ADR provably minimizes the amount of replication compared to aggressive replication, it incurs a higher communication cost. This is because, for general topologies, it requires building a spanning tree of the hosts and communicating only through that tree, which is crucial for the optimality of its data placement overhead. In all the schemes, if a host has insufficient capacity to store the new objects, it replaces a randomly-chosen least-recently-used object. Note that comparing IDP with ADR or AR is not an apples-to-apples comparison, since ADR and AR were designed for different workloads. Still, our experiments provide important insight about their performance under a sensing workload. For lack of space, we present only a few interesting results. More details of the simulation setup and additional results can be found in [33]. Read and Write Rate.Figure 8(a) shows that for a given write rate (16,000 objects/min),7 the average query response time of IDP increases slightly with the read rate. This is because of the increased fragmentation due to higher system load. Surprisingly, even with AR, the response time increases with the read rate. The reason behind this counter-intuitive performance is that AR is oblivious to data clustering. ADR has the worst response time because it communicates over a spanning tree, ignores data clustering, and does not consider the hierarchical data access patterns. At all the read rates shown in Figure 8(a), IDP performs significantly better than the other algorithms. Similarly, our experiments have shown that IDP incurs significantly less read traffic than these algorithms across all the read rates.In Figure 8(b), we vary the write rate with a constant read rate (40 objects/min). As expected, the write cost increases as the write rate increases. Although both ADR and IDP create similar numbers of replicas, ADR incurs a higher write cost because updates are propagated using a spanning tree overlay and, therefore, they traverse longer distances. AR incurs more cost than IDP, because it fails to capture the locations of write sources while placing replicas. Read-Write Proximity.Read-write proximity reflects the physical distance between the reader and the writer. As mentioned in Section 2.1, we model it by the lowest level (called a locality level) in the hierarchy they have in common. Our simulated database has 6 levels, with the root at level 1. Thus, a locality level of 1 signifies the smallest proximity (because the reader and the writer for the same data can be anywhere in the whole hierarchy), and a level of 6 means the highest proximity.Figure 8(c) shows that increasing the locality level reduces the average response time. This is intuitive, because queries with higher levels of locality select fewer objects, and, thus, need to traverse fewer hosts. Because it keeps objects clustered, IDP outperforms the other algorithms. The difference in performance becomes more pronounced as the locality level is low, because such queries select large subtrees from the global database and so the advantages of clustering are amplified. Representative Services Workload. We have also evaluated IDP, AR, and ADR with a wide variety of synthetic workloads and a heterogeneous mix of them (more details in [33]). By tuning different parameters, we have generated workloads outlined in Table 1. Our results show that IDP outperforms the other two algorithms in both response time and network overhead for all the workloads. AR has worse response time because it ignores data clustering and optimal placement, and worse network overhead because it creates too many replicas. The performance of AR approaches that of IDP when both (1) the write rate is low (e.g., Epidemic Alert) so that eager replication has minimal cost, and (2) the read locality is near the leaf objects (e.g., Parking Finder) so that typical queries select only small subtrees and hence clustering objects is not that crucial. On the other hand, ADR has worse response time and network overhead for all the services, mainly because it communicates over a spanning tree, ignores data clustering, and does not consider the hierarchical data access patterns. 8 Related WorkThe issues of data replication and placement in wide-area networks have been studied in a variety of contexts. In this section, we first discuss the relevant theoretical analyses and then present relevant efforts in Web content delivery, distributed file systems, and distributed databases.Theoretical Background. The off-line data allocation problem (i.e., the placement of data replicas in a system to reduce a certain cost function) has been studied extensively (see [15] for a survey). The general problem has been found to be NP-Hard [42], and several approximate and practical solutions have been proposed [21, 28, 36]. The similar problem of optimally replicating read-only objects has been addressed in the context of content distribution networks [22] and the Web [35]. Other studies [11, 29, 41] have explored the on-line replication of objects in distributed systems. The competitive algorithm in [11] is theoretically interesting, but has little practical application since on every write, all but one replica is deleted. [29] uses expensive genetic algorithms to approximate optimal replication, and requires global information (e.g., current global read and write loads). The ADR algorithm in [41] provides optimal data placement when the network topology is a tree. However, its performance on a general topology is worse than IDP, as shown in Section 7. Web Content Delivery. Web proxy caches [40] replicate data on demand to improve response time and availability, but deal with relatively infrequent writes and simpler access patterns. The replication schemes used by distributed cache systems and content distribution systems (CDNs) [1, 23] place tighter controls on replication in order to manage space resources even more efficiently and to reduce the overhead of fetching objects. These approaches may be more applicable to read/write workloads. However, they do not support the variable access granularity and frequent writes of sensing services. Distributed File Systems. Some recent wide-area distributed file systems have targeted supporting relatively frequent writes and providing a consistent view to all users. The Ivy system [32] provides support for the combination of wide-area deployment and write updates. However, while creating replicas in the underlying distributed hash table (DHT) is straightforward, controlling their placement is difficult. The Pangaea system [36] uses aggressive replication along with techniques (efficient broadcast, harbingers, etc.) for minimizing the overhead of propagating updates to all the replicas. However, our experiments in Section 7 show that the less aggressive replication of IDP provides better read performance while significantly reducing write propagation overhead. These existing works do not consider the complex access patterns and dynamic access granularity that we consider. Distributed Databases. Distributed databases provide similar guarantees as file systems while supporting more complex access patterns. Off-line approaches [10, 24] to the replication problem require the complete query schedule (workload) a priori, and determine how to fragment the database and where to place the fragments. However, neither [10] nor [24] considers the storage and processing capacity of the physical sites, and [24] considers only read-only databases. Brunstrom et al. [12] considers data relocation under dynamic workloads, but assumes that the objects to be allocated are known a priori and does not consider object replication. It also allocates each object independently and thus fails to exploit the possible access correlation among objects. The PIER system [19], like Ivy, relies on an underlying DHT for replication of data. The Mariposa system [37] considers an economic model for controlling both the replication of table fragments and the execution of queries across the fragmented database. While Mariposa's mechanisms are flexible and could create arbitrary replication policies, the work does not evaluate the policies. All of these past efforts are very specific to relational databases, and, therefore, are not directly applicable to the hierarchical database systems that we explore. 9 ConclusionIn this paper, we identified the unique workload characteristics of wide-area sensing services, and designed the IDP algorithm to provide automatic, adaptive data placement for such services. Key features of IDP include proactive coalescing, size-constrained optimal-partitioning, TCP-time-out-inspired load estimators, GNP-based latency estimators, parent-child peering soft-state fault tolerance, placement strategies that are both cluster-forming and latency-reducing, and randomized response-time replica selection. We showed that IDP outperforms previous algorithms in terms of response time, network traffic, and responsiveness to flash crowds, across a wide variety of sensing service workloads.Acknowledgements. We thank Brad Karp and Mahadev Satyanarayanan for helpful discussions on this work. References
This document was translated from LATEX by HEVEA. |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Last changed: 16 Nov. 2005 jel |