
| ||||||||||||||||||||||||||||||||||||||||||||||||||||
|
BSDCon 2002 Paper
[BSDCon '02 Tech Program Index]
Running "fsck" in the BackgroundMarshall Kirk McKusick, Author and ConsultantAbstractTraditionally, recovery of a BSD fast filesystem after an uncontrolled system crash such as a power failure or a system panic required the use of the filesystem checking program, "fsck". Because the filesystem cannot be used while it is being checked by "fsck", a large server may experience unacceptably long periods of unavailability after a crash.Rather than write a new version of "fsck" that can run on an active filesystem, I have added the ability to take a snapshot of a filesystem partition to create a quiescent filesystem on which a slightly modified version of the traditional "fsck" can run. A key feature of these snapshots is that they usually require filesystem write activity to be suspended for less than one second. The suspension time is independent of the size of the filesystem. To reduce the number and types of corruption, soft updates were added to ensure that the only filesystem inconsistencies are lost resources. With these two additions it is now possible to bring the system up immediately after a crash and then run checks to reclaim the lost resources on the active filesystems. Background "fsck" runs by taking a snapshot and then running its traditional first four passes to calculate the correct bitmaps for the allocations in the filesystem snapshot. From these bitmaps, "fsck" finds any lost resources and invokes special system calls to reclaim them in the underlying active filesystem. 1. Background and IntroductionTraditionally, recovery of the BSD fast filesystem [McKusick, et al., 1996] after an uncontrolled system crash such as a power failure or a system panic required the use of the "fsck" filesystem checking program [McKusick & Kowalski, 1994]. "fsck" would inspect all the filesystem metadata (bitmaps, inodes, and directories) and correct any inconsistencies that were found. As the metadata comprises about three to five percent of the disk space, checking a large filesystem can take an hour or longer. Because the filesystem is inaccessible while it is being checked by "fsck", a large server may experience unacceptably long periods of unavailability after a crash.Many methods exist for solving the metadata consistency and recovery problem [Ganger et al, 2000; Seltzer et al, 2000]. The solution selected for the fast filesystem is soft updates. Soft updates control the ordering of filesystem updates such that the only inconsistencies in the on-disk representation are that free blocks and inodes may be claimed as "in use" in the on-disk bitmaps when they are really unused. Soft updates eliminates the need to run "fsck" after a system crash except in the rare event of a hardware failure in the disk on which the filesystem resides. Since the only filesystem inconsistency is lost blocks and inodes, the only ill effect from running on the filesystem after a crash is that part of the filesystem space that should have been available will be lost. Any time the lost space from crashes reaches an unacceptable level, the filesystem must be taken offline long enough to run "fsck" to reclaim the lost resources. Because many server systems need to be available 24x7, there is never an available multi-hour time when a traditional version of "fsck" can be run. Thus, I have been motivated to develop a filesystem check program that can run on an active filesystem to reclaim the lost resources. The first approach that I considered was to write a new utility that would operate on an active filesystem to identify the lost resources and reclaim them. Such a utility would fall into the class of real-time garbage collection. Despite much research and literature, garbage collection of actively used resources remains challenging to implement. In addition to the complexity of real-time garbage collection, the new utility would need to recreate much of the functionality of the existing "fsck" utility. Having a second utility would lead to additional maintenance complexity as bugs or feature additions would need to be implemented in two utilities rather than just one. To avoid the complexity and maintenance problems, I decided to take an approach that would enable me to use most of the existing "fsck" program. "fsck" runs on the assumption that the filesystem it is checking is quiescent. To create an apparently quiescent filesystem, I added the ability to take a snapshot of a filesystem partition [McKusick & Ganger, 1999]. Using copy-on-write, a snapshot provides a filesystem image frozen at a specific point in time. The next section describes the details on how snapshots are taken and managed. As lost resources will not be used until they have been found and marked as free in the bitmaps, there are no limits on how long a background reclamation scheme can take to find and recover them. Thus, I can run the traditional "fsck" over a snapshot to find all the missing resources even if it takes several hours and the filesystem is being actively changed. Snapshots may seem a more complex solution to the problem of running space reclamation on an active filesystem than a more straight forward garbage-collection utility. However, their cost (about 1300 lines of code) is amortized over the other useful functionality: the ability to do reliable dumps of active filesystems and the ability to provide back-ups of the filesystem at several times during the day. This functionality was first popularized by Network Appliance [Hitz et al, 1994; Hutchinson et al, 1999]. Snapshots enable the safe backup of live filesystems. When dump notices that it is being asked to dump a mounted filesystem, it can simply take a snapshot of the filesystem and run over the snapshot instead of on the live filesystem. When dump completes, it releases the snapshot. Periodic snapshots can be made accessible to users. When taken every few hours during the day, they allow users to retrieve a file that they wrote several hours earlier and later deleted or overwrote by mistake. Snapshots are much more convenient to use than dump tapes and can be created much more frequently. To make a snapshot accessible to users through a traditional filesystem interface, BSD uses the memory-disk driver, md. The mdconfig command takes a snapshot file as input and produces a /dev/md0 character-device interface to access it. The /dev/md0 character device can then be used as the input device for a standard BSD FFS mount command, allowing the snapshot to appear as a replica of the frozen filesystem at whatever location in the namespace that the system administrator chooses to mount it. Thus, the following script could be run at noon to create a midday backup of the /usr filesystem and make it available at /backups/usr/noon:
# Take the snapshot mount -u -o snapshot /usr/snap.noon /usr # Attach it to /dev/md0 mdconfig -a -t vnode -u 0 -f /usr/snap.noon # Mount it for user access mount -r /dev/md0 /backups/usr/noonWhen no longer needed, it can be removed with: # Unmount snapshot umount /backups/usr/noon # Detach it from /dev/md0 mdconfig -d -u 0 # Delete the snapshot rm -f /usr/snap.noon 2. Creating a Filesystem Snapshot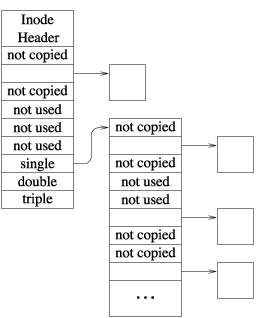 Figure 1: Structure of a snapshot file A filesystem snapshot is a frozen image of a filesystem at a given instant in time. Implementing snapshots in the BSD fast filesystem has proven to be straightforward. Taking a snapshot entails the following steps:
The splitting of the bitmap copies between steps two and six is the way that I avoid having the suspend time be a function of the size of the filesystem. By making our primary copy pass while the filesystem is still active, and then having only a few cylinder groups in need of recopying after it has been suspended, I keep the suspend time down to a small and usually filesystem size independent time. The details of the two-pass algorithm are as follows. Before starting the copy and scan of all the cylinder groups, the snapshot code allocates a "progress" bitmap whose size is equal to the number of cylinder groups in the filesystem. The purpose of the "progress" bitmap is to keep track of which cylinder groups have been scanned. Initially, all the bits in the "progress" map are cleared. The first pass is completed in step two before the filesystem is suspended. In this first pass, all the cylinder groups are scanned. When the clinder group is read, its corresponding bit is set in the "progress" bitmap. The cylinder group is then copied and its block map is consulted to update the snapshot file as described in step two. Since the filesystem is still active, filesystem blocks may be allocated and freed while the cylinder groups are being scanned. Each time a cylinder group is updated because of a block being allocated or freed, its corresponding bit in the "progress" bitmap is cleared. Once this first pass over the cylinder groups is completed, the filesystem is "suspended." Step six now becomes the second pass of the algorithm. The second pass need only identify and update the snapshot for any cylinder groups that were modified after it handled them in the first pass. The changed cylinder groups are identified by scanning the "progress" bitmap and rescanning any cylinder groups whose bits are zero. Although every bitmap would have to be reprocessed in the worst case, in practice only a few bitmaps need to be recopied and checked. 3. Maintaining a Filesystem SnapshotEach time an existing block in the filesystem is modified, the filesystem checks whether that block was in use at the time that the snapshot was taken (i.e., it is not marked "not used"). If so, and if it has not already been copied (i.e., it is still marked "not copied"), a new block is allocated from among the "not used" blocks and placed in the snapshot file to replace the "not copied" entry. The previous contents of the block are copied to the newly allocated snapshot file block, and the modification to the original is then allowed to proceed. Whenever a file is removed, the snapshot code inspects each of the blocks being freed and claims any that were in use at the time of the snapshot. Those blocks marked "not used" are returned to the free list.When a snapshot file is read, reads of blocks marked "not copied" return the contents of the corresponding block in the filesystem. Reads of blocks that have been copied return the contents in the copied block (e.g., the contents that were stored at that location in the filesystem at the time that the snapshot was taken). Writes to snapshot files are not permitted. When a snapshot file is no longer needed, it can be removed in the same way as any other file; its blocks are simply returned to the free list and its inode is zeroed and returned to the free inode list. Snapshots may live across reboots. When a snapshot file is created, the inode number of the snapshot file is recorded in the superblock. When a filesystem is mounted, the snapshot list is traversed and all the listed snapshots are activated. The only limit on the number of snapshots that may exist in a filesystem is the size of the array in the superblock that holds the list of snapshots. Currently, this array can hold up to twenty snapshots. Multiple snapshot files can exist concurrently. As described above, earlier snapshot files would appear in later snapshots. If an earlier snapshot is removed, a later snapshot would claim its blocks rather than allowing them to be returned to the free list. This semantic means that it would be impossible to free any space on the filesystem except by removing the newest snapshot. To avoid this problem, the snapshot code goes through and expunges all earlier snapshots by changing its view of them to being zero length files. With this technique, the freeing of an earlier snapshot releases the space held by that snapshot. When a block is overwritten, all snapshots are given an opportunity to copy the block. A copy of the block is made for each snapshot in which the block resides. Overwrites typically occur only for inode and directory blocks. File data is usually not overwritten. Instead, a file will be truncated and then reallocated as it is rewritten. Thus, the slow and I/O intensive block copying is infrequent. Deleted blocks are handled differently. The list of snapshots is consulted. When a snapshot is found in which the block is active ("not copied"), the deleted block is claimed by that snapshot. The traversal of the snapshot list is then terminated. Other snapshots for which the block are active are left with an entry of "not copied" for that block. The result is that when they access that location, they will still reference the deleted block. Since snapshots may not be modified, the block will not change. Since the block is claimed by a snapshot, it will not be allocated to another use. If the snapshot claiming the deleted block is deleted, the remaining snapshots will be given the opportunity to claim the block. Only when none of the remaining snapshots wants to claim the block (i.e., it is marked "not used" in all of them) will it be returned to the freelist. 4. Snapshot PerformanceThe experiments described in this section and the background "fsck" performance section used the following hardware/software configuration:Computer: Dual Processor using two Celeron 350MHz CPUs. The machine has 256Mb of main memory. O/S: FreeBSD 5.0-current as of December 30, 2001 I/O Controller: Adaptec 2940 Ultra2 SCSI adapter
Disk: Two
Small Filesystem: 0.5Gb, 8K block, 1K fragment, 90% full, 70874
files, initial snapshot size 0.392Mb (0.08% of filesystem space).
Large Filesystem: 7.7Gb, 16K block, 2K fragment, 90% full, 520715
files, initial snapshot size 2.672Mb (0.03% of filesystem space).
Load: Four continuously running simultaneous Andrew benchmarks
that create a moderate amount of filesystem activity intermixed
with periods of CPU intensive activity [Howard et al, 1988].
Five operations were implemented in the kernel:
The final step after a successful background "fsck" run is to
update the filesystem status in the superblock. There are two
flags in the superblock that track the state of a filesystem.
The first is the "clean" flag that is set when a filesystem is
unmounted (by the system administrator or at system shutdown) and
cleared while it is mounted with writing enabled. The second is
the "unclean-at-mount" flag that is described below.
The "clean" flag is used by the traditional "fsck" to
decide which filesystems need to be checked. Those filesystems
with the flag set are skipped; those filesystems with the flag
clear are checked. Following a successful check, the "clean"
flag is set. Before soft updates, the kernel did not allow
unclean filesystems (e.g., filesystems with the "clean" flag
cleared) to be mounted for writing as the corruption could cause
the system to panic.
The "unclean-at-mount" flag was added as part of soft
updates. Unclean filesystems running with soft updates are safe
to mount with writing permitted. However, the system needs to
remember that some cleanup may be required. Thus, the "unclean-at-mount" flag gets set when an unclean filesystem is mounted
(e.g., mounted with writing enabled without the "clean" flag
having been set). The "unclean-at-mount" flag serves two purposes. First, when a filesystem with the "unclean-at-mount" is
unmounted, the "clean" flag is not set to show that cleaning is
still required. Second it tracks the filesystems that need
cleaning. By the time that background "fsck" is run, all the
filesystems are mounted so none will have their "clean" flag
set. Thus, the "unclean-at-mount" flag is used by the background "fsck" to distinguish which filesystems need to be
checked. Those filesystems with the flag set are checked; those
filesystems with the flag clear are skipped.
So, the final step after a successful run of a background
"fsck" is to clear the "unclean-at-mount" bit in the
superblock (using operation 1) so that the filesystem will be
marked "clean" when it is unmounted by the system administrator
or at system shutdown.
The "fsck" program is really just a front end that reads
the /etc/fstab file and determines which filesystems need to be
checked. For each filesystem to be checked, the appropriate back
end is invoked. For the fast filesystem, "fsck_ffs" is
invoked. If "fsck" is invoked with neither the -F nor the -B
flag, it runs in traditional mode and checks every listed
filesystem. Otherwise it is invoked with the -F to request that
it run in foreground mode. In foreground mode, the check program
for each filesystem is invoked with the -F flag to determine
whether it wishes to run as part of the boot up sequence, or if
it is able to do its job in background after the system is up and
running. A non-zero exit code indicates that it wants to run in
foreground and it is invoked again with neither the -F nor the -B
flag so that it will run in its traditional mode. A zero exit
code indicates that it is able to run later in background and
just a deferred message is printed. The "fsck" program
attempts to run as many checks in parallel as possible. Typically it can run a check on each disk in parallel.
After the system has gone multiuser, "fsck" is invoked
with the -B flag to request that it run in background mode. The
check program for each filesystem is invoked with the -F flag to
determine whether it wishes to run as part of the boot up
sequence, or if it is able to do its job in background after the
system is up and running. A non-zero exit code indicates that it
wanted to run in foreground that is assumed to have been done, so
the filesystem is skipped. A zero exit code indicates that it is
able to run in background so the check program is invoked with
the -B flag to indicate that a check on the active filesystem
should be done. When running in background mode, only one
filesystem at a time will be checked. To further reduce the load
on the system, the background check is typically run at a nice
value of plus four.
The "fsck_ffs" program does the actual checking of the
fast filesystem. When invoked with the -F flag, "fsck_ffs"
determines whether the filesystem needs to be checked immediately
in foreground or if its checking can be deferred to background.
To be eligible for background checking it must have been running
with soft updates, not have been marked as needing a foreground
check, and be mounted and writable when the background check is
to be done. If these conditions are met, then "fsck_ffs" exits
with a zero exit status. Otherwise it exits with a non-zero exit
status. If the filesystem is clean, it will exit with a non-zero
exit status so that the clean status of the filesystem can be
verified and reported during the foreground checks. Note that,
when invoked with the -F flag, no checking is done. The only
thing that "fsck_ffs" does is to determine whether a foreground
or background check is needed and exit with an appropriate status
code.
When "fsck_ffs" is invoked with the -B flag, a check is
done on the specified and possibly active filesystem. The potential set of corrections is limited to those available when running in preen mode (as further detailed in the previous section).
If unexpected errors are found, the filesystem is marked as needing a foreground check and "fsck_ffs" exits without attempting
any further checking.
Because of "fsck"'s I/O clustering, it is capable of using
nearly all the bandwidth of a disk. Although background "fsck"
only checks one filesystem partition at a time (as compared to
traditional "fsck" that checks all separate disks containing
filesystems in parallel), even a single instance of "fsck" can
cause seriously increased latency to processes trying to access
files on the filesystem (or anything else on the same disk) that
is being checked.
As there is no urgency in completing the space reclamation,
background "fsck" is usually run at lower priority than other
processes. The usual way to reduce priority is to nice the process to some positive value which results in it getting a lower
priority for the CPU. Because "fsck" is nearly completely I/O
bound, giving it a lower CPU priority has almost no effect on the
time in which it runs and hence in its rate of issuing I/O
requests.
As a general solution to reducing the resource usage of I/O
bound processes such as background "fsck", a small change has
been made to the disk strategy routine. When an I/O request is
posted, the disk strategy routine first checks whether the process is running at a positive nice. If it is, and there are any
other outstanding I/O requests for the disk, the process is put
to sleep for nice hundredths of a second. Thus, a process running at a nice of four will sleep for forty millisecond each time
it makes a disk I/O request. Such a process will be able to do
at most twenty-five disk I/O requests per second - about a third
of the bandwidth of a current technology disk. At the maximum
nice value of twenty, a process is limited to five I/O requests
per second which is low enough to be almost unnoticeable by other
processes competing for access to the disk. Because the slowdown is imposed only when there are other outstanding disk
requests, I/O bound processes can run at full speed on an otherwise idle system.
Table 6 shows the times to run background "fsck" on a
filesystem that is otherwise idle. It is running with a nice
value of zero. It is the only process active on the system, so
represents a lower bound on the time that a background disk check
can be done. Note that its running time is only slightly greater
than would be expected by adding the time to take and remove a
snapshot (see Table 1 and Table 3) to the running time of the
traditional "fsck" shown in Table 5.
Table 7 shows the times to run background "fsck" on a
filesystem that has four processes concurrently writing to it.
It is running with a nice value of four. Note that its running
time increases by a factor of ten as it is yielding to the other
running processes. By contrast, its effect on the other processes is minimal as their aggregate throughput is slowed by less
than ten percent.
Snapshots may seem a more complex solution to the problem of
running space reclamation on an active filesystem than a more
straight forward garbage-collection utility. However, their cost
(about 1300 lines of code) is amortized over the other useful
functionality: the ability to do reliable dumps of active
filesystems and the ability to provide back-ups of the filesystem
at several times during the day.
For the future, I need to gain experience with using background "fsck", to gain confidence in its robustness, and to
find the optimal priority to minimize its slowdown on the system
while still finishing its job in a reasonable amount of time.
In his spare time, he enjoys swimming, scuba diving, and
wine collecting. The wine is stored in a specially constructed
wine cellar (accessible from the web at www.mckusick.com/~mckusick/) in the basement of the house that he shares
with Eric Allman, his domestic partner of 20-and-some-odd years.
You can contact him via email at mckusick@mckusick.com.
|
|
This paper was originally published in the
Proceedings of the BSDCon '02 Conference on File and Storage Technologies, February 11-14, 2002, Cathedral Hill Hotel, San Francisco, California, USA.
Last changed: 28 Dec. 2001 ml |
|
