


Next: Related work
Up: Geographic Properties of Internet
Previous: Geographic Properties of Internet
The Internet consists of several autonomous systems (ASes) that are
under the control of different administrative domains. Routing across
these administrative domains is accomplished using the Border gateway
protocol (BGP), a protocol for propagating routes between ASes. ASes
connect to each other either at public exchanges or at private
peering points. The
network path between two end-hosts typically traverses multiple
ASes. BGP is flexible in allowing each AS to apply its own local
preferences, and export and import policies for route selection and
propagation. The characteristics of an end-to-end path are very much
dependent on the policies employed by the intervening ASes.
Previous work on Internet routing has focused on studying properties
such as end-to-end performance, routing stability, and routing
convergence that are affected by routing policies. There has also been
work on strategies for determining alternate (and hopefully better)
routes by using overlay networks to circumvent the default Internet
routing. We discuss previous work in more detail in Section
2.
In this paper, we present a novel way of analyzing certain properties
of Internet routing. We show how geographic information can
provide insights into the structure and functioning of the Internet,
including the interactions between different autonomous systems. In
particular, geographic information can be used to quantify well-known
network properties such as hot-potato routing. It can also be used to
quantify and substantiate prevalent intuitions about Internet routing,
such as the relative optimality of intra-ISP routing compared to
inter-ISP routing.
To analyze geographic properties of routing, it is necessary to first
determine the geographic path of an IP route. The geographic
path is obtained by stringing together the geographic locations of the
nodes (i.e., routers) along the network path between two hosts. For
instance, the geographic path from a host in Berkeley to one in
Harvard may look as follows: Berkeley 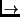 San Francisco
New York Boston
Cambridge. The level of detail in the geographic path would depend on
how precisely we are able to determine the locations of the
intermediate routers in the path. In Section 3, we
describe GeoTrack [13], a tool we have developed for determining
the geographic path of routes. Our study is based on extensive
traceroute data gathered from 20 hosts distributed across the U.S. and
Europe and also traceroute data gathered by Paxson [26] in 1995.
Internet routes can be highly circuitous. For instance, we observed
a route from a host in St. Louis to one in Indiana (328 km away) that
traverses a total distance of over 3500 km (Section
4.2.1). By tracing the geographic
path, we are able to automatically flag such anomalous routes, which
would be difficult to do using purely network-centric information such
as delay. We compute the linearized distance between two hosts
as the sum of the geographic lengths of the individual links of the
path. We then compute the ratio of the linearized distance of the path
to the geographic distance between the source and destination hosts, which we term the distance ratio. A
large ratio would be indicative of a circuitous and possibly anomalous
route. In Section 4, we study circuitousness of paths as a
function of the geographic and network locations of the end-hosts.
Our results indicate that the presence of multiple ISPs in a path is
an important contributor to circuitous routing. We also find intra-ISP
routing to be far less circuitous than inter-ISP routing. Our study of
circuitousness of paths provides some insights into the peering and
routing policies of ISPs. Although circuitousness may not always
relate to performance, it can often be indicative of a routing problem
that deserves more careful examination.
There are two extremes to the routing policy that an ISP may employ:
hot-potato routing and cold-potato routing. In hot-potato
routing, the ISP hands off packets to the next ISP as quickly as
possible. In cold-potato routing, the ISP carries packets on its own
network as far as possible before handing them off to the next
ISP. The former policy minimizes the burden on the ISP's network
whereas the latter gives the ISP greater control over the end-to-end
quality of service experienced by the packets.
As we discuss in Section 5.4, geographic information
provides a means to quantify these notions by using the geographic
distance traversed within an ISP as a proxy for the amount of work
performed by the ISP. In addition, we can also evaluate the degree to
which an individual ISP contributes in the routing of packets
end-to-end. Our analysis of properties of paths that traverse
multiple ISPs is presented in Section 5.
Another aspect of routing that bears careful examination is its fault
tolerance. Fault tolerance has generally been studied in the context
of node or link failures based on network-level topology
information. However, such topology information may be incomplete in
that two seemingly independent nodes may actually be susceptible to
correlated failures. For instance, a catastrophic event such as an
earthquake or a major power outage might knock out all of an ISP's routers
in a geographic region. Geographic information can help in
identifying routers that are co-located. In order to analyze the
impact of correlated failures, we consider ISP topologies at the geographic
level, where each node represents a geographic region such as a city.
Using the geographic topology information of several commercial ISPs
gathered from CAIDA [24], we analyze the fault tolerance
properties of individual topologies and the topology resulting from
the combination of the individual ISP networks (Section
6). We find that many tier-1 ISPs
are highly susceptible to single geographic node failures. The
combined topology however exhibits better tolerance to such failures.
In summary, we believe geography is an interesting means for analyzing
and quantifying network properties. In some cases, our analysis
provides additional evidence for existing intuition about certain
properties of Internet routing (e.g., hot-potato routing, circuitous paths). An important contribution of our work
is a methodology for quantifying such intuitions using geographic information. Such quantification enables us, for instance, to automatically flag circuitous paths, something that would be hard to using purely network-centric metrics (and no geographic information).
San Francisco
New York Boston
Cambridge. The level of detail in the geographic path would depend on
how precisely we are able to determine the locations of the
intermediate routers in the path. In Section 3, we
describe GeoTrack [13], a tool we have developed for determining
the geographic path of routes. Our study is based on extensive
traceroute data gathered from 20 hosts distributed across the U.S. and
Europe and also traceroute data gathered by Paxson [26] in 1995.
Internet routes can be highly circuitous. For instance, we observed
a route from a host in St. Louis to one in Indiana (328 km away) that
traverses a total distance of over 3500 km (Section
4.2.1). By tracing the geographic
path, we are able to automatically flag such anomalous routes, which
would be difficult to do using purely network-centric information such
as delay. We compute the linearized distance between two hosts
as the sum of the geographic lengths of the individual links of the
path. We then compute the ratio of the linearized distance of the path
to the geographic distance between the source and destination hosts, which we term the distance ratio. A
large ratio would be indicative of a circuitous and possibly anomalous
route. In Section 4, we study circuitousness of paths as a
function of the geographic and network locations of the end-hosts.
Our results indicate that the presence of multiple ISPs in a path is
an important contributor to circuitous routing. We also find intra-ISP
routing to be far less circuitous than inter-ISP routing. Our study of
circuitousness of paths provides some insights into the peering and
routing policies of ISPs. Although circuitousness may not always
relate to performance, it can often be indicative of a routing problem
that deserves more careful examination.
There are two extremes to the routing policy that an ISP may employ:
hot-potato routing and cold-potato routing. In hot-potato
routing, the ISP hands off packets to the next ISP as quickly as
possible. In cold-potato routing, the ISP carries packets on its own
network as far as possible before handing them off to the next
ISP. The former policy minimizes the burden on the ISP's network
whereas the latter gives the ISP greater control over the end-to-end
quality of service experienced by the packets.
As we discuss in Section 5.4, geographic information
provides a means to quantify these notions by using the geographic
distance traversed within an ISP as a proxy for the amount of work
performed by the ISP. In addition, we can also evaluate the degree to
which an individual ISP contributes in the routing of packets
end-to-end. Our analysis of properties of paths that traverse
multiple ISPs is presented in Section 5.
Another aspect of routing that bears careful examination is its fault
tolerance. Fault tolerance has generally been studied in the context
of node or link failures based on network-level topology
information. However, such topology information may be incomplete in
that two seemingly independent nodes may actually be susceptible to
correlated failures. For instance, a catastrophic event such as an
earthquake or a major power outage might knock out all of an ISP's routers
in a geographic region. Geographic information can help in
identifying routers that are co-located. In order to analyze the
impact of correlated failures, we consider ISP topologies at the geographic
level, where each node represents a geographic region such as a city.
Using the geographic topology information of several commercial ISPs
gathered from CAIDA [24], we analyze the fault tolerance
properties of individual topologies and the topology resulting from
the combination of the individual ISP networks (Section
6). We find that many tier-1 ISPs
are highly susceptible to single geographic node failures. The
combined topology however exhibits better tolerance to such failures.
In summary, we believe geography is an interesting means for analyzing
and quantifying network properties. In some cases, our analysis
provides additional evidence for existing intuition about certain
properties of Internet routing (e.g., hot-potato routing, circuitous paths). An important contribution of our work
is a methodology for quantifying such intuitions using geographic information. Such quantification enables us, for instance, to automatically flag circuitous paths, something that would be hard to using purely network-centric metrics (and no geographic information).
Next: Related work
Up: Geographic Properties of Internet
Previous: Geographic Properties of Internet
Lakshminarayanan Subramanian
2002-04-14