
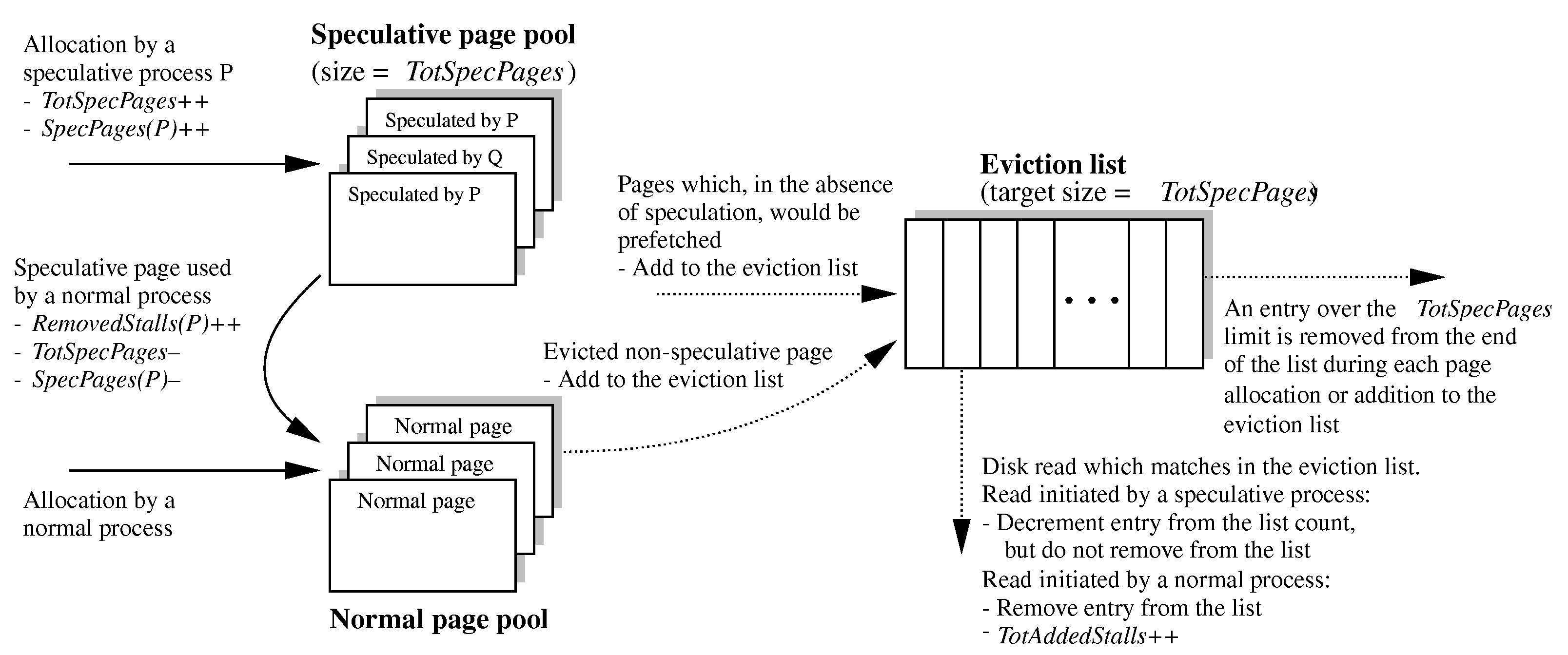
We estimate the cost and benefit of each speculative process with the assistance of an eviction list (or ghost buffer [8]). The eviction list tracks the non-resident pages that would most likely be in memory if no speculative execution had taken place. Each list entry uniquely identifies the disk block of one such page. To determine how many entries the list should contain, we track the number of speculative pages that are in memory only because of speculative execution. The eviction list is a FIFO to which we add an entry for each non-speculative page that is evicted from memory, and remove an entry if the FIFO is already full when a new page is added.
The eviction list allows the system to estimate the number of I/O stalls that speculative executions added to, or removed from, normal executions. In particular, when a normal process requests a disk read, if there is a matching entry in the eviction list, then we have identified an added stall that would not have occurred in the absence of speculative execution. Conversely, when a normal process avoids a disk read by using a speculative page, we have identified a removed stall that was prevented by speculative execution. The eviction list further aids accurate identification of removed stalls by allowing the system to detect when a speculative prefetch is merely refetching previously-resident data that was only evicted because of speculative memory use. Figure 4 describes the updates and accesses that can occur to the eviction list and associated performance counts in greater detail.
|
With the resulting per-process counts of removed stalls
(![]() ),
and the system-wide count of added stalls (
),
and the system-wide count of added stalls (
![]() ), we could
estimate the net overhead of each speculative process as the overall
cost/benefit for its execution so far.
We could then use this measure to disable a speculative process whenever
its net estimated overhead is above some selected threshhold. Unfortunately,
this approach would be unresponsive to changes in the
effectiveness of a speculative process. Such changes might be caused
by different phases within the application which affect prefetching accuracy,
or simply by varying memory contention from concurrent processes. We therefore
use an approach that not only bounds the estimated
overhead of enabled speculative processes, but also is responsive to changes
in the estimated overhead of speculative processes.
), we could
estimate the net overhead of each speculative process as the overall
cost/benefit for its execution so far.
We could then use this measure to disable a speculative process whenever
its net estimated overhead is above some selected threshhold. Unfortunately,
this approach would be unresponsive to changes in the
effectiveness of a speculative process. Such changes might be caused
by different phases within the application which affect prefetching accuracy,
or simply by varying memory contention from concurrent processes. We therefore
use an approach that not only bounds the estimated
overhead of enabled speculative processes, but also is responsive to changes
in the estimated overhead of speculative processes.
The remainder of this section describes the reactive approach that we implemented and evaluated. Many other possibilities exist, but a survey is beyond the scope of this paper.
We divide system time into periodic intervals, where ![]() denotes
the current interval. At the end of each interval, a pair of cost-benefit
estimates are updated for each speculative process based on the estimates
and accumulated stall counts from the previous interval, and whether the
speculative process was enabled or disabled during that interval.
We use these estimates (and any accumulated stall counts since the last
interval) to estimate the overhead at any time, in order to decide when
to enable or disable each speculative process, as follows.
denotes
the current interval. At the end of each interval, a pair of cost-benefit
estimates are updated for each speculative process based on the estimates
and accumulated stall counts from the previous interval, and whether the
speculative process was enabled or disabled during that interval.
We use these estimates (and any accumulated stall counts since the last
interval) to estimate the overhead at any time, in order to decide when
to enable or disable each speculative process, as follows.
If a speculative process was enabled (i.e. marked runnable), we
exponentially decay the previous stall estimates at the end of each interval:
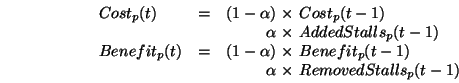
Per-process counts of removed stalls are maintained directly by observing
when speculative pages are first referenced by a normal process. However,
to calculate per-process added stalls, the system-wide total for each
interval is divided among the speculative processes in proportion to their
memory use:
We then combine the cost-benefit estimates in the simplest manner to obtain the overhead of each enabled speculative process:
If a speculative process's estimated overhead is non-negligible, we mark
it non-runnable and reclaim its memory.
Therefore, if memory is tight, speculative processes that consume more
memory will need to prefetch more effectively to remain runnable.
If a speculative process was disabled (i.e. marked non-runnable),
we simply add to the previous cost and benefit estimates at the end of each
interval:
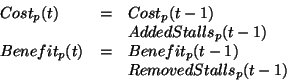
Our overhead calculation then includes the period over which the process
has been stopped. Let ![]() be the interval during which non-runnable process
be the interval during which non-runnable process
![]() was last executed:
was last executed:
Thus we decay the overhead estimate over time, which allows the system to set an upper bound on the net estimated overhead before a speculative process should be allowed to run again. Notice that this property is independent of the manner in which the stall counts are decayed for enabled speculative processes.
There is some scope for investigating more informed techniques for reenabling speculative processes; for example, we could allow a speculative process to continue running and issuing prefetch requests, but prevent these requests from reaching the disk or allocating memory. This would reduce resource pressure compared with a fully-enabled speculative process, while providing us with more information to help determine when it would be worthwhile to reenable speculative execution. However, a major benefit of our current approach is its conservativism -- a more informed approach would risk a harmful increase in resource pressure for just those applications that require most care.