Our plugin isolation scheme is a clean re-implementation of a popular concept employed in a number of systems, both virtual machines and others, e.g. VMware [25], Palladium [8], etc. It exploits features of the segmentation and privilege checking hardware of the Intel x86 architecture to achieve address space isolation within the Linux kernel. We briefly describe the method next; for a full discussion, the reader is referred to the original papers and Intel documentation.
The fundamental idea is to allow application-specific code to run in the core kernel by placing it in a separate protection domain and relying on hardware to enforce it. The new domain is an address space - a proper subset of the Linux kernel's virtual address space. While the kernel itself can access the plugins' address space freely, plugins cannot, in general, access the larger kernel memory.
Segmentation
In practice, domains are implemented as protected
memory segments directly supported by the hardware MMU. Segments are
ranges of consecutive addresses described by base address and
length. The operating system maintains linear tables of `segment
descriptors' for all segments. In addition to base and length, each
segment descriptor stores privilege, access, and type information for
its segment. Two tables of descriptors are active at any given point
in time: the Global Descriptor Table (GDT) and a Local Descriptor
Table (LDT). While the former is static and immutable, the latter is a
per-process structure.
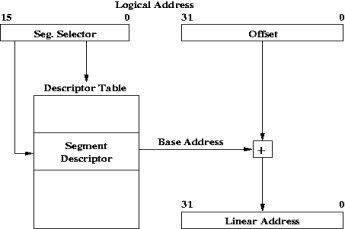
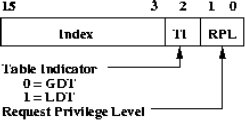
Figure 3 depicts how segmentation addressing works on the x86. Logical addresses are composed of a 16-bit segment selector and a 32-bit offset. Segment selector values are used to index into segment descriptor tables. The layout of a segment selector is shown in Figure 4. It contains a linear table index, a one-bit Table Indicator (TI), and a two-bit Requested Privilege Level (RPL). The TI determines which of the two currently active tables the selector is referring to, whereas the RPL is used in privilege checks. The chosen descriptor entry provides a base address, a limit to check the offset against, read/write/execute permissions, and a descriptor privilege level (DPL).
The CPU maintains a Current Privilege Level (CPL) for the currently executing instruction. The DPL is compared to the CPL and RPL for each memory access. In general, CPL and RPL need to be numerically less than or equal to the target segment's DPL (i.e. at the same or higher privilege) in order for access to be granted. For a complete explanation of access permission checks and motivation for the existence of the RPL the reader is referred to Intel documentation [1, pp. 105-140]. All access violations, such as pointer dereferences to memory outside of the ring-1 segment (including NULL pointer dereference), attempts to execute an illegal or protected instruction, etc., result in an exception being thrown and a trap to the kernel proper to handle it. Additionally, the owner service allows each plugin a quantum of time in which to complete. Overrunning that quantum is detected by a periodic timer interrupt and also results in forceful preemption and a trap to the kernel.
Our current method for dealing with offending plugins is immediate termination. An interesting future direction we are considering is to implement a recovery mechanism, allowing extensible services the choice to terminate or to continue a plugin based on custom per-service policies and the type of the failure or misbehavior.
Initialization
At boot time, the plugin facility allocates a
region of memory to be used exclusively for plugin code and data. A
simple first-fit private memory allocator is initialized with the
parameters of the pool and is used to allocate memory for structures
to be placed in the isolated area.
Two new segment descriptors are computed and installed in the GDT, each covering the whole isolated memory pool. Both descriptors are assigned the same ring-1 privileges but different types. The type of the first one is set to `code' and it is used to address executable plugin code. The type of the second one is set to `data', and it is used for data manipulations involving plugin stacks and heaps. This simple overlay scheme was chosen to ease the initial implementation effort by avoiding the need to parameterize the memory allocator for disjoint code and data memory pools. It could be replaced with a split code and data design in the future, to prevent the possibility for self-modifying plugin code and to limit the amount of damage a misbehaving plugin can wreak upon other plugins.
A third segment descriptor can be defined overlaying part or all of the kernel's ring-0 memory but accessible in read-only mode from ring-1. Although such a segment has the potential of simplifying or optimizing kernel/plugin data interactions it has to be used with great care because of possible security implications. It can be thought of as an optional feature for cases when performance benefits outweigh potential security concerns.
Runtimes are created at the request of kernel services. Each runtime's control structure contains pointers to its stack and heap as well as a symbol table of registered plugins. The control structure is allocated in ring-0 kernel memory to protect it from being tampered with by plugins. The built-in plugins are implemented as trusted kernel subroutines enabling them to modify the control structures during operations like creation or deletion of dynamic plugins. In contrast, the heap, stack, and code of plugins are all allocated within ring-1 memory.
Control Transfers
Passing control from a plugin in ring-1 to
the kernel in ring-0 is straightforward, by use of a trap gate
similar to the one implementing system calls from user-space
(ring-3). The hardware handles the trap and passes control to the
kernel in a protected fashion. Any state needed for returning to
ring-1 is saved on the kernel stack. If the control transfer is to be
one way (e.g. return from a plugin) rather than two way (e.g. kernel
callback), then that state is simply cleaned up by the kernel
trap handler.
Passing control from the kernel to a plugin, unfortunately, is more difficult. There is an inherent asymmetry in control transfers between privilege levels because the hardware is designed to prohibit high-privileged code from invoking lower-privileged code. To sidestep the problem, a stack frame is carefully forged (on the ring-0 stack) that emulates the state the stack would have had if it had been called from ring-1 and then executes a ret instruction to the forged return address. This causes the CPU to switch into ring-1 and start execution of the targeted plugin function.
Interrupts
x86 interrupt handlers run in ring-0. In case an
interrupt occurs while the CPU is already executing in kernel mode,
the interrupt simply grows the current stack. If, however, the CPU is
executing in a privilege level different from ring-0, then it switches
to ring-0 immediately, performing the necessary stack swap to the bottom of the kernel stack. This behavior is predicated on the
premise that an interrupt occurring while in user-space has no kernel
state to preserve, so the new frame can start from the base of the
kernel stack.
It is not hard to see how this otherwise normal behavior can cause trouble when interacting with ring-1 plugins, however. The aforementioned premise is negated because plugins are, in effect, a part of the kernel, yet they execute outside of ring-0. If an interrupt fires while a plugin is running, the CPU switches immediately to a ring-0 handler and uses the kernel stack. Unfortunately, starting from the base of the stack it overwrites the state already there, accumulated prior to invoking the plugin. This effect is due to the unconventional use of privilege rings to implement what amounts to protected upcalls of which the hardware is unaware.
There are a few possible solutions to this problem: (1) disable interrupts while plugins are running, (2) save and restore the kernel stack before and after plugin invocations, and (3) trick the hardware to grow the stack upon an interrupt in ring-1.
While the first solution does not add any overhead to plugin execution, it has the undesirable effect of blocking interrupts for potentially non-trivial lengths of time. In the kernel, blocking of all interrupts is allowed only for the shortest times, since it could lead to loss of important device interrupts and disrupt the operation of peripherals. Moreover, such a solution would also prevent the implementation of plugin preemption, which relies on a periodic hardware timer interrupt. Clearly, this approach is unsuitable.
The second solution, saving the kernel stack's state before plugin invocation and restoring it immediately after that, is workable. It was our first implementation, but it increased plugin invocation overheads and introduced significant irregularities in their cost, due to the unpredictable amount of state (up to a page frame in the worst case) that needs to be saved and restored each time.
These disadvantages led us to come up with our final solution. It is based on an architectural programming trick that fools the interrupt handling hardware into growing the kernel stack rather than overwriting its bottom, despite the fact that the interrupt occurs outside of ring-0. The trick involves careful manipulation of the stack base pointer in the task state segment structure (TSS) of the CPU [1]. This allows us to continue servicing interrupts while plugins are running, yet, at the same time avoid the unpredictability of kernel stack saving and restoring. As an added bonus, the overhead of this method is extremely small, its implementation consisting of only a few assembly instructions.
A Remaining Issue
A discussion of kernel plugins would not be
complete without mention of any remaining issues with their current
implementation. One such issue is the lack of protection across
multiple plugins. Thanks to the compartmentalization of each client's
plugins into a separate runtime, plugins have no means of naming
symbols in other runtimes. This, however, does not provide firm
isolation guarantees, even though it raises the bar for how difficult
it would be for a plugin to interfere with plugins in other runtimes.
To address this issue, we are considering developing our scheme further to include two GDT descriptors per runtime, to describe each runtime's code and data separately from other runtimes. In this way, we can exploit the segmentation hardware further and achieve isolation not only between the kernel proper and plugins but also among runtimes. Such an enhancement would not add any runtime overhead and is under active development.