
| ||||||||||||||||||||||||||||||||||||||||||||||||||||
|
USENIX 2003 Annual Technical Conference, FREENIX Track — Paper
[USENIX Annual Conference '03 Tech Program Index]
NFS Tricks and Benchmarking TrapsDaniel Ellard, Margo Seltzer Harvard University {ellard,margo}@eecs.harvard.edu
AbstractWe describe two modifications to the FreeBSD 4.6 NFS server to increase read throughput by improving the read-ahead heuristic to deal with reordered requests and stride access patterns. We show that for some stride access patterns, our new heuristics improve end-to-end NFS throughput by nearly a factor of two. We also show that benchmarking and experimenting with changes to an NFS server can be a subtle and challenging task, and that it is often difficult to distinguish the impact of a new algorithm or heuristic from the quirks of the underlying software and hardware with which they interact. We discuss these quirks and their potential effects.
1 IntroductionDespite many innovations, file system performance is steadily losing ground relative to CPU, memory, and even network performance. This is due primarily to the improvement rates of the underlying hardware. CPU speed and memory density typically double every 18 months, while similar improvements in disk latency have taken the better part of a decade. Disks do keep pace in terms of total storage capacity, and to a lesser extent in total bandwidth, but disk latency has become the primary impediment to total system performance. To avoid paying the full cost of disk latency, modern file systems leverage the relatively high bandwidth of the disk to perform long sequential operations asynchronously and amortize the cost of these operations over the set of synchronous operations that would otherwise be necessary. For write operations, some techniques for doing this are log-structured file systems (18), journalling, and soft updates (21). For reading, the primary mechanism is read-ahead or prefetching. When the file system detects that a process is reading blocks from a file in a predictable pattern, it may optimistically read blocks that it anticipates will be requested soon. If the blocks are arranged sequentially on disk, then these ``extra'' reads can be performed relatively efficiently because the incremental cost of reading additional contiguous blocks is small. This technique can be beneficial even when the disk blocks are not adjacent, as shown by Shriver et al. (23). Although there has been research in detecting and exploiting arbitrary access patterns, most file systems do not attempt to recognize or handle anything more complex than simple sequential access - but because sequential access is the common case, this is quite effective for most workloads. The Fast File System (FFS) was the pioneering implementation of these ideas on UNIX (12). FFS assumes that most file access patterns are sequential, and therefore attempts to arrange files on disk in such a way that they can be read via a relatively small number of large reads, instead of block by block. When reading, it estimates the sequentiality of the access pattern and, if the pattern appears to be sequential, performs read-ahead so that subsequent reads can be serviced from the buffer cache instead of from disk. In an earlier study of NFS traffic, we noted that many NFS requests arrive at the server in a different order than originally intended by the client (8). In the case of read requests, this means that the sequentiality metric used by FFS is undermined; read-ahead can be disabled by a small percentage of out-of-order requests, even when the overall access pattern is overwhelmingly sequential. We devised two sequentiality metrics that are resistant to small perturbations in the request order. The first is a general method and is described in our earlier study. The second, which we call SlowDown, is a simplification of the more general method that makes use of the existing FFS sequentiality metric and read-ahead code as the basis for its implementation. We define and benchmark this method in Section 6. The fact that the computation of the sequentiality metric is isolated from the rest of the code in the FreeBSD NFS server implementation provides an interesting testbed for experiments in new methods to detect access patterns. Using this testbed, we demonstrate a new algorithm for detecting sequential subcomponents in a simple class of regular but non-sequential read access patterns. Such access patterns arise when there is more than one reader concurrently reading a file, or when there is one reader accessing the file in a ``stride'' read pattern. Our algorithm is described and benchmarked in Section 7. Despite the evidence from our analysis of several long-term NFS traces that these methods would enhance read performance, the actual benefit of these new algorithms proved quite difficult to quantify. In our efforts to measure accurately the impact of our changes to the system, we discovered several other phenomena that interacted with the performance of the disk and file system in ways that had far more impact on the overall performance of the system than our improvements. The majority of this paper is devoted to discussing these effects and how to control for them. In truth, we feel that aspects of this discussion will be more interesting and useful to our audience than the description of our changes to the NFS server. Note that when we refer to NFS, we are referring only to versions 2 (RFC 1094) and 3 (RFC 1813) of the NFS protocol. We do not discuss NFS version 4 (RFC 3010) in this paper, although we believe that its performance will be influenced by many of the same issues. The rest of this paper is organized as follows: In section 2 we discuss related work, and in Section 3, we give an overview of file system benchmarking. We describe our benchmark and our testbed in Section 4. In Section 5, we discuss some of the properties of modern disks, disk scheduling algorithms, and network transport protocols that can disrupt NFS benchmarks. We return to the topic of optimizing NFS read performance via improved read-ahead, and define and benchmark the SlowDown heuristic in Section 6. Section 7 gives a new cursor-based method for improving the performance of stride access patterns and measures its effectiveness. In Section 8, we discuss plans for future work and then conclude in Section 9.
| ||||||||||||||||||||||||||||||||||||||||||||||
|
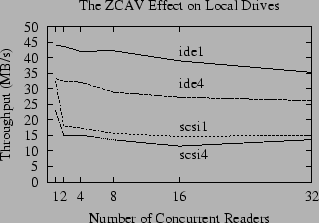
The ZCAV effect is illustrated in Figure 1, which shows the results of running the same benchmark on different areas of a disk. For our benchmarks, we have divided each of our test disks into four partitions of approximately equal size, numbered 1 through 4. The files in tests scsi1 and ide1 are positioned in the outer cylinders of the SCSI and IDE drives, respectively, while the scsi4 and ide4 test files are placed in the inner cylinders. For both disks, it is clear that ZCAV has a strong effect. The effect is clearly pronounced for the IDE drive. The SCSI drive shows a weaker effect - but as we will see in Section 5.2, this is because there is another effect that obscures the ZCAV effect for simple benchmarks on our SCSI disk. For both drives the ZCAV effect is more than enough to obscure the impact of any small change to the performance of the file system.
The best method to control ZCAV effects is to use the largest disk available and run your benchmark in the smallest possible partition (preferably the outermost partition). This will minimize the ZCAV effect by minimizing the difference in capacity and transfer rate between the longest and shortest tracks used in your benchmark.
One of the features touted by SCSI advocates is the availability of tagged command queues (also known as tagged queues). This feature permits the host to send several disk operation requests to the disk and let the disk execute them asynchronously and in whatever order it deems appropriate. Modern SCSI disks typically have an internal command queue with as many as 256 entries. Some recent IDE drives support a feature conceptually identical to tagged command queues, but our IDE drive does not.

|
The fact that the tagged command queue allows the disk to reorder requests is both a boon for ordinary users and a source of headaches for system researchers. With tagged queues enabled, the disk may service its requests in a different order than they arrive at the disk, and its heuristics for reordering requests may be different from what the system researcher desires (or expects). For example, many disks will reorder or reschedule requests in order to reduce the total power required to position the disk head. Some disks even employ heuristics to reduce the amount of audible noise they generate - many users would prefer to have a quiet computer than one that utilizes the full positioning speed of the disk. The same model of disk drive may exhibit different performance characteristics depending on the firmware version, and on whether it is intended for a desktop or a server.
The SCSI disk in our system supports tagged queues, and the default FreeBSD kernel detects and uses them. We instrumented the FreeBSD kernel to compare the order that disk requests are sent to the disk to the order in which they are serviced, and found that when tagged queues are disabled, the two orders are the same, but when tagged queues are enabled, the disk does reorder requests. Note that this instrumentation was disabled during our timed benchmarks.
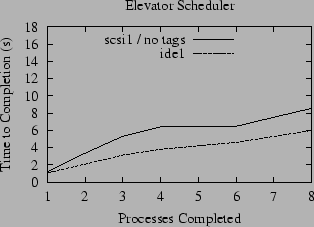
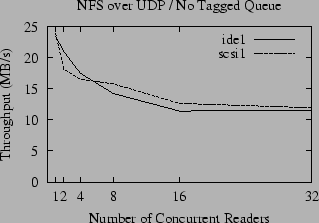
To explore the interaction between the FreeBSD disk scheduler and the disk's scheduler, we ran a benchmark with the tagged queues disabled. The results are shown in Figure 2. For our benchmark, the performance is significantly increased when tagged queues are disabled. When tagged queues are enabled, the performance for the default configuration has a dramatic spike for the single-reader case, but then quickly falls away for multiple readers. With the tagged command queue disabled, however, the throughput for multiple concurrent readers decreases slowly as the number of readers increases, and is almost equal to the spike for the single reader in the default configuration. For example, the throughput for scsi1 levels off just above 15 MB/s in the default configuration, but barely dips below 27 MB/s when tagged command queues are disabled.
There is no question that tagged command queues are effective in many situations. For our benchmark, however, the kernel disk scheduler makes better use of the disk than the on-disk scheduler. This is undoubtedly due in part to the fact that the geometry the disk advertises to the kernel does, in fact, closely resemble its actual geometry. This is not necessarily the case - for example, it is not the case for many RAID devices or similar systems that use several physical disks or other hardware (perhaps distributed over a network) to implement one logical disk. In a hardware implementation of RAID, an access to a single logical block may require accessing several physical blocks whose addresses are completely hidden from the kernel. In the case of SAN devices or storage devices employing a dynamic or adaptive configuration the situation is even more complex; in such devices the relationship between logical and physical block addresses may be arbitrary, or even change from one moment to the next (29). For these situations it is better to let the device schedule the requests because it has more knowledge than the kernel.
Even for ordinary single-spindle disks, there is a small amount of re-mapping due to bad block substitution. This almost always constitutes a very small fraction of the total number of disk blocks and it is usually done in such a manner that it has a negligible effect on performance.
|
The FreeBSD disk scheduling algorithm, implemented in the bufqdisksort function, is based on a cyclical variant of the SCAN or
elevator scan algorithm, as described in the BSD 4.4 documentation
(13).
This algorithm can achieve high sustained throughput, and is
particularly well suited to the access patterns created by the FFS
read-ahead heuristics. Unfortunately, if the CPU can process data
faster than the I/O subsystem can deliver it, then this algorithm can
create unfair scheduling. In the worst case, imagine that the disk
head is positioned at the outermost cylinder, ready to begin a scan
inward, and the disk request queue contains two requests: one for a
block on the outermost cylinder, requested by process ![]() , and
another for a block on the innermost cylinder, requested by process
, and
another for a block on the innermost cylinder, requested by process
![]() . The request for the first block is satisfied, and
. The request for the first block is satisfied, and ![]() immediately requests another block in the same cylinder.
If
immediately requests another block in the same cylinder.
If ![]() requests a sequence of blocks that are laid out
sequentially on disk, and does so faster than the disk can reposition,
its requests will continue to be placed in the disk request queue
before the request made by
requests a sequence of blocks that are laid out
sequentially on disk, and does so faster than the disk can reposition,
its requests will continue to be placed in the disk request queue
before the request made by
![]() . In the worst case,
. In the worst case, ![]() may have to wait until
may have to wait until ![]() has scanned the entire disk.
Somewhat perversely, an optimal file system layout greatly increases
the probability of long sequential disk accesses, with a corresponding
increase in the probability of unfair scheduling of this kind.
has scanned the entire disk.
Somewhat perversely, an optimal file system layout greatly increases
the probability of long sequential disk accesses, with a corresponding
increase in the probability of unfair scheduling of this kind.
This problem can be reduced by the use of tagged command queues,
depending on how the on-disk scheduler is implemented. In our test
machine, the on-board disk scheduler of the SCSI disks is in effect
more fair than the FreeBSD scheduler. In this example, it will
process ![]() 's request before much time passes.
's request before much time passes.
The unfairness of the elevator scan algorithm is also somewhat reduced by the natural fragmentation of file systems that occurs over time as files are added, change size, or are deleted. Although FFS does a good job of reducing the impact of fragmentation, this effect is difficult to avoid entirely.
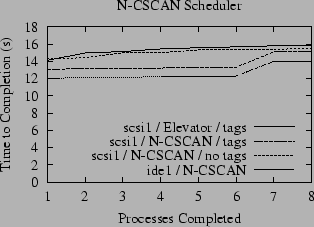
The primary symptom of this problem is a large variation in time required by concurrent readers, and therefore this behavior is easily visible in the variance of the run times of each subprocess in our simple benchmark. Each subprocess starts at the same time, and reads the same amount of data, so intuition suggests that they will all finish at approximately the same time. This intuition is profoundly wrong when the default scheduler is used. Figure 3 illustrates the distribution of the individual process times for runs for the benchmark that runs eight concurrent processes, each reading a different 32 MB file. Note that the cache is flushed after each run. The plot of the time required to complete 1 through 8 processes using the elevator scan scheduler on the ide1 partition shows that the average time required to complete the first process is 1.04 seconds, while the second finishes in 1.98 seconds, the third in 2.94, and so on until the last job finishes after an average of 5.97 seconds. With tagged queues disabled, a similar distribution holds for the scsi1 partition, ranging from 1.18 through 8.54 seconds, although the plot for scsi1 is not as straight as that for ide1. The difference between the time required by the fastest and slowest jobs is almost a factor 6 for ide1, and even higher for scsi1.
N-step CSCAN (N-CSCAN) is a fair variation of the Elevator scheduler that prohibits changes to the schedule for the current scan - in effect, it is always planning the schedule for the next scan (5). The resulting scheduler is fair in the sense that the expected latency of each disk operation is proportional to the length of the request queue at the time the disk begins its next sweep. Only a small patch is needed to change the current FreeBSD disk scheduler to N-CSCAN. We have implemented this change, along with a switch that can be used to toggle at runtime which disk scheduling algorithm is in use. As illustrated again in Figure 3, this dramatically reduces the variation in the run times for each reader process: for both ide1 and scsi1, the difference in elapsed time between the slowest and the fastest readers is less than 20%.
Unfortunately, fairness comes at a high price: although all of the reading processes make progress at nearly the same rate, the overall average throughput achieved is less than half the bandwidth delivered by the unfair elevator algorithm. In fact, for these two cases, the slowest reading process for the elevator scan algorithm requires approximately 50% less time to run than the fastest reading process using the N-step CSCAN algorithm. For this particular case, it is hard to argue convincingly in favor of fairness. In the most extreme case, however, it is possible to construct a light workload that causes a process to wait for several minutes for the read of a single block to complete. As a rule of thumb, it is unwise to allow a single read to take longer than it takes for a user to call the help desk to complain that their machine is hung. At some point human factors can make a fair division of file system bandwidth as important as overall throughput.
Also shown in Figure 3 is the impact of these disk scheduling algorithms on scsi1 when the tagged command queue is enabled. As described in Section 5.2, the on-disk tagged command queue can override many of the scheduling decisions made by the host disk scheduler. In this measurement, the on-disk scheduling algorithm appears to be fairer than N-step CSCAN (in terms of the difference in elapsed time between the slowest and fastest processes), but even worse in terms of overall throughput.
Although the plots in Figure 3 are relatively flat, they still exhibit an interesting quirk - there is a notable jump between the mean run time of the sixth and seventh processes to finish for N-CSCAN for ide1 and scsi1 with tagged queues disabled. We did not investigate this phenomenon.
The tradeoffs between throughput, latency, fairness and other factors in disk scheduling algorithms have been well studied and are still the subject of research (3,20). Despite this research, choosing the most appropriate algorithm for a particular workload is a complex decision, and apparently a lost art. We find it disappointing that modern operating systems generally do not acknowledge these tradeoffs by giving their administrators the opportunity to experiment and choose the algorithm most appropriate to their workload.
|
|
SUN RPC, upon which the first implementation of NFS was constructed, used UDP for its transport layer, in part because of the simplicity and efficiency of the UDP protocol. Beginning with NFS version 3, however, many vendors began offering TCP-based RPC, including NFS over TCP. This has advantages in some environments, particularly WAN systems, due to the different characteristics of TCP versus UDP. UDP is a lightweight and connectionless datagram protocol. A UDP datagram may require several lower-level packets (such as Ethernet frames) to transmit, and the loss of any one of these packets will cause the entire datagram to be lost. In contrast, TCP provides a reliable connection-based mechanism for communication and can, in many cases, detect and deal with packet corruption, loss, or reordering more efficiently than UDP. TCP provides mechanisms for intelligent flow control that are appropriate for WANs.
On a wide-area network, or a local network with frequent packet loss or collision, TCP connections can provide better performance than UDP. Modern LANs are nearly always fully switched, and have very low packet loss rates, so the worst-case behavior of UDP is rarely observed. However, mixed-speed LANs do experience frequent packet loss at the junctions between fast and slow segments, and in this case the benefits of TCP are also worth considering. In our testbed, we have only a single switch, so we do not observe these effects in our benchmarks.
The RPC transport protocol used by each file system mounted via NFS is chosen when the file system is mounted. The default transport protocol used by mount_nfs is UDP. Many system administrators use amd instead of mount_nfs, however, and amd uses a different implementation of the mount protocol. On FreeBSD, NetBSD, and many distributions of GNU/Linux, amd uses TCP by default, but on other systems, such as OpenBSD, amd uses UDP. This choice can be overridden, but often goes unnoticed.
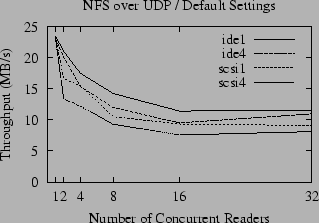
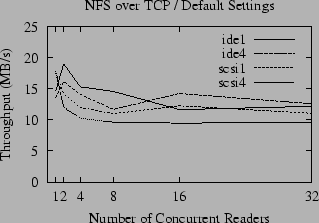
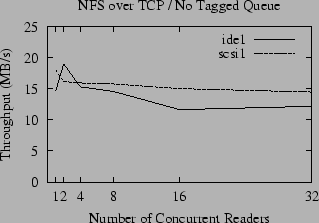
A comparison of the raw throughput of NFS for large reads over TCP and UDP is given in Figures 4 and 5. Compared to the performance of the local file system, shown in Figure 1, the throughput of NFS is disappointing; for concurrent readers the performance is about half that of the local file system and only a fraction of the potential bandwidth of the gigabit Ethernet. The throughput for small numbers of readers is substantially better for UDP than TCP, but the advantage of UDP is attenuated as the number of concurrent readers increases until it has no advantage over TCP (and in some cases is actually slower). In contrast, the throughput of accesses to the local disk slightly increases as the number of readers increases. We postulate that this is due to a combination of the queuing model used by the disk drive, and the tendency of the OS to perform read-ahead when it perceives that the access pattern is sequential, but also to throttle the read-ahead to a fixed limit. When reading a single file, a fixed amount of buffer space is set aside for read-ahead, and only a fixed number of disk requests are made at a time. As the number of open files increases, the total amount of memory set aside for read-ahead increases proportionally (until another fixed limit is reached) and the number of disk accesses queued up for the disk to process also grows. This allows the disk to be kept busier, and thus the total throughput can increase.
Unlike UDP, the throughput of NFS over TCP roughly parallels the throughput of the local file system, although it is always significantly slower, even over gigabit Ethernet. This leads to the question of why UDP and TCP implementations of NFS have such different performance characteristics as the number of readers increases - and whether it is possible to improve the performance of UDP for multiple readers.
As illustrated in Figures 4 and 5, the effects of ZCAV and tagged queues are clearly visible in the NFS benchmarks. Even though network latency and the extra overhead of RPC typically reduces the bandwidth available to NFS to half the local bandwidth, these effects must be considered because they can easily obscure more subtle effects.
In addition to the effects we have uncovered here, there is a new mystery - the anomalous slowness of the ide1 and ide4 partitions when accessed via NFS over TCP by one reader. We suspect that this is a symptom of TCP flow control.
Having now detailed some of the idiosyncrasies that we encountered with our simple benchmark, let us return to the task at hand, and evaluate the benefit of a more flexible sequentiality metric to trigger read-ahead in NFS.
The heuristics employed by NFS and FFS begin to break down when used on UDP-based NFS workloads because many NFS client implementations permit requests to be reordered between the time that they are made by client applications and the time they are delivered to the server. This reordering is due most frequently to queuing issues in the client nfsiod daemon, which marshals and controls the communication between the client and the server. This reordering can also occur due to network effects, but in our system the reorderings are attributable to nfsiod.
It must be noted that because this problem is due entirely to the implementation of the NFS client, a direct and pragmatic approach would be to fix the client to prevent request reordering. This is contrary to our research agenda, however, which focuses on servers. We are more interested in studying how servers can handle arbitrary and suboptimal client request streams than optimizing clients to generate request streams that are easier for servers to handle.
The fact that NFS requests are reordered means that access patterns that are in fact entirely sequential from the perspective of the client may appear, to the server, to contain some element of randomness. When this happens, the default heuristic causes read-ahead to be disabled (or diminished significantly), causing considerable performance degradation for sequential reads.
The frequency at which request reordering takes place increases as the number of concurrent readers, the number of nfsiods, and the total CPU utilization on the client increases. By using a slow client and a fast server on a congested network, we have been able to create systems that reorder more than 10% of their requests for long periods of time, and during our analysis of traces from production systems we have seen similar percentages during periods of peak traffic. On our benchmark system, however, we were unable to exceed 6% request reordering on UDP and 2% on TCP on our gigabit network with anything less than pathological measures. This was slightly disappointing, because lower probabilities of request reordering translate into less potential for improvement by our algorithm, but we decided to press ahead and see whether our algorithm is useful in our situation and thus might be even more useful to users on less well-mannered networks.
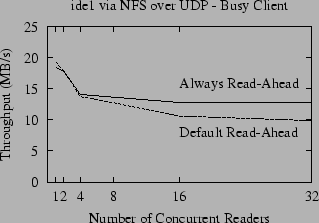
|
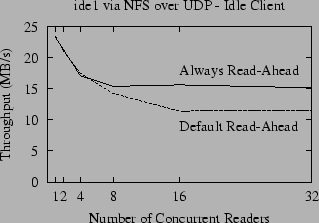
Figure 6 shows the NFS throughput for the default implementation compared to the throughput when we hardwire the sequentiality metric to always force read-ahead to occur. The difference between the ``Always Read-ahead'' and ``Default Read-ahead'' lines shows the potential improvement. In theory, for large sequential reads (such as our benchmarks) the NFS server should detect the sequential access pattern and perform read-ahead. As shown in Figure 6, however, for more than four concurrent readers the default and optimal lines diverge. This is due in part to the increased number of packet reorderings that occur when the number of concurrent readers increases, but it is also due to contention for system resources, as we will discuss in Section 6.3.
In our own experiments, we noticed that the frequency of packet reordering increases in tandem with the number of active processes on the client (whether those processes are doing any I/O or not), so Figure 6 also shows throughput when the client is running four ``infinite loop'' processes during the benchmark. Not surprisingly, the throughput of NFS decreases when there is contention for the client CPU (because NFS does have a significant processing overhead). Counter to our intuition, however, the gap between the ``Always Read-ahead'' line and the ``Default Read-ahead'' lines is actually smaller when the CPU is loaded, even though we see more packet reordering.
There are many ways that the underlying sequentiality of an access pattern may be measured, such as the metrics developed in our earlier studies of NFS traces. For our preliminary implementation, however, we wish to find a simple heuristic that does well in the expected case and not very badly in the worst case, and that requires a minimum of bookkeeping and computational overhead.
Our current heuristic is named SlowDown and is based on the idea
of allowing the sequentiality index to rise in the same manner as the
ordinary heuristic, but fall less rapidly. Unlike the default
behavior (where a single out-of-order request can drop the
sequentiality score to zero), the SlowDown heuristic is resilient to
``slightly'' out-of-order requests. At the same time, however, it
does not waste read-ahead on access patterns that do not have a
strongly sequential component - if the access pattern is truly random,
it will quickly disable read-ahead. The default metric for computing
the heuristic, as implemented in FreeBSD 4.x, is essentially the
following: when a new file is accessed, it is given an initial
sequentiality metric seqCount ![]() (or sometimes a different
constant, depending on the context). Whenever the file is accessed,
if the current offset currOffset is the same as the offset after
the last operation (prevOffset), then increment seqCount.
Otherwise, reset seqCount to a low value.
(or sometimes a different
constant, depending on the context). Whenever the file is accessed,
if the current offset currOffset is the same as the offset after
the last operation (prevOffset), then increment seqCount.
Otherwise, reset seqCount to a low value.
The seqCount is used by the file system to decide how much read-ahead to perform - the higher seqCount rises, the more aggressive the file system becomes. Note that in both algorithms, seqCount is never allowed to grow higher than 127, due to the implementation of the lower levels of the operating system.
The SlowDown heuristic is nearly identical in concept to the additive-increase/multiplicative-decrease used by TCP/IP to implement congestion control, although its application is very different. The initialization is the same as for the default algorithm, and when prevOffset matches currOffset, seqCount is incremented as before. When prevOffset differs from currOffset, however, the response of SlowDown is different:
In the first case, we do not know whether the access pattern is becoming random, or whether we are simply seeing jitter in the request order, so we leave seqCount alone. In the second case, we want to start to cut back on the amount of read-ahead, and so we reduce seqCount, but not all the way to zero. If the non-sequential trend continues, however, repeatedly dividing seqCount in half will quickly chop it down to zero.
It is possible to invent access patterns that cause SlowDown to erroneously trigger read-ahead of blocks that will never be accessed. To counter this, more intelligence (requiring more state, and more computation) could be added to the algorithm. However, in our trace analysis we did not encounter any access patterns that would trick SlowDown to perform excessive read-ahead. The only goal of SlowDown is to help cope with small reorderings in the request stream. An analysis of the values of seqCount show that SlowDown accomplishes this goal.
NFS versions 2 and 3 are stateless protocols, and do not contain any primitives analogous to the open and close system calls of a local file system. Because of the stateless nature of NFS, most NFS server implementations do not maintain a table of the open file descriptors corresponding to the files that are active at any given moment. Instead, servers typically maintain a cache of information about files that have been accessed recently and therefore are believed likely to be accessed again in the near future. In FreeBSD, the information used to compute and update the sequentiality metric for each active file is cached in a small table named nfsheur.
Our benchmarks of the SlowDown heuristic showed no improvement over the default algorithm, even though instrumentation of the kernel showed that the algorithm was behaving correctly and updated the sequentiality metric properly even when many requests were reordered. We discovered that our efforts to calculate the sequentiality metric correctly were rendered futile because the nfsheur table was too small.
The nfsheur table is implemented as a hash table, using open hashing with a small and limited number of probes. If the number of probes necessary to find a file handle is larger than this limit, the least recently used file handle from among those probed is ejected and the new file handle is added in its place. This means that entries can be ejected from the table even when it is less than full, and in the worst case a small number of active files can thrash nfsheur. Even in the best case, if the number of active files exceeds the size of the table, active file handles will constantly be ejected from the table. When a file is ejected from the table, all of the information used to compute its sequentiality metric is lost.
The default hash table scheme works well when a relatively small number of files are accessed concurrently, but for contemporary NFS servers with many concurrently active files the default hash table parameters are simply too small. This is not particularly surprising, because network bandwidth, file system size, and NFS traffic have increased by two orders of magnitude since the parameters of the nfsheur hash table were chosen. For our SlowDown experiment, it is clear that there is no benefit to properly updating the sequentiality score for a file if the sequentiality score for that file is immediately ejected from the cache.
To address this problem, we enlarged the nfsheur table, and improved the hash table parameters to make ejections less likely when the table is not full. As shown in Figure 7, with the new table implementation SlowDown matches the ``Always Read-ahead'' heuristic. We were also surprised to discover that with the new table, the default heuristic also performs as well as ``Always Read-Ahead''. It is apparently more important to have an entry in nfsheur for each active file than it is for those entries to be completely accurate.
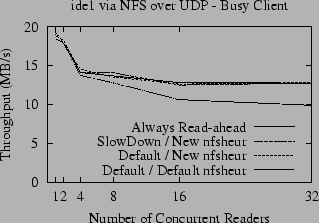
|
The conventional implementation of the sequentiality metric in the
FreeBSD implementation of NFS (and in fact, in many implementations of
FFS) uses a single descriptor structure to encapsulate all information
about the observed read access patterns of a file. This can cause
suboptimal read-ahead when there are several readers of the same file,
or a single reader that reads a file in a regular but non-sequential
pattern. For example, imagine a process that strides through a file,
reading blocks
![]() .
This
pattern is the composition of two completely
sequential read access patterns (
.
This
pattern is the composition of two completely
sequential read access patterns (
![]() and
and
![]() ), each of which can benefit from read-ahead.
Unfortunately, neither the default sequentiality metric nor SlowDown
recognizes this pattern, and this access pattern will be treated as
non-sequential, with no read-ahead. Variations on the stride pattern
are common in engineering and out-of-core workloads, and optimizing
them has been the subject of considerable research, although it is
usually attacked at the application level or as a virtual memory
issue (2,17).
), each of which can benefit from read-ahead.
Unfortunately, neither the default sequentiality metric nor SlowDown
recognizes this pattern, and this access pattern will be treated as
non-sequential, with no read-ahead. Variations on the stride pattern
are common in engineering and out-of-core workloads, and optimizing
them has been the subject of considerable research, although it is
usually attacked at the application level or as a virtual memory
issue (2,17).
In the ordinary implementation, the nfsheur contains a single offset and sequentiality count for each file handle. In order to handle stride read patterns, we add the concept of cursors to the nfsheur. Each active file handle may have several cursors, and each cursor contains its own offset and sequentiality count. When a read occurs, the sequentiality metric searches the nfsheur for a matching cursor (using the same approximate match as SlowDown to match offsets). If it finds a matching cursor, the cursor is updated and its sequentiality count is used to compute the effective seqCount for the rest of the operation, using the SlowDown heuristic. If there is no cursor matching a given read, then a new cursor is allocated and added to the nfsheur. There is a limit to the number of active cursors per file, and when this limit is exceeded the least recently used cursor for that file is recycled.
If the access pattern is truly random, then many cursors are created, but their sequentiality counts do not grow and no extra read-ahead is performed. In the worst case, a carefully crafted access pattern can trick the algorithm into maximizing the sequentiality count for a particular cursor just before that cursor dies (and therefore potentially performing read-ahead for many blocks that are never requested), but the cost of reading the extraneous blocks can be amortized over the increased efficiency of reading the blocks that were requested (and caused the sequentiality count to increase in the first place).
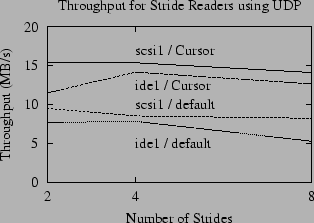
|
|
| ||||||||||||||||||||||||||||||
The performance of this method for a small set of stride read patterns is
shown in Figure 8 and Table 1.
For the ``2'' stride for a file of length ![]() , there are two
sequential subcomponents, beginning at offsets 0 and
, there are two
sequential subcomponents, beginning at offsets 0 and ![]() , for
the ``4'' stride there are four beginning at offsets 0,
, for
the ``4'' stride there are four beginning at offsets 0, ![]() ,
, ![]() ,
and
,
and ![]() , and for the ``8'' stride there are eight sequential subcomponents
beginning at offsets 0,
, and for the ``8'' stride there are eight sequential subcomponents
beginning at offsets 0, ![]() ,
, ![]() ,
, ![]() ,
, ![]() ,
, ![]() ,
, ![]() , and
, and
![]() . To the ordinary sequentiality or SlowDown heuristics,
these appear to be completely random access patterns, but our
cursor-based algorithm detects them and induces the proper amount of
read-ahead for each cursor. As shown in this figure, the time
required to read the test files using the cursor-based method is
at least 50% faster than using the default method. In the most
extreme case, the cursor-based method is 140% faster for the
8-stride reader on ide1.
. To the ordinary sequentiality or SlowDown heuristics,
these appear to be completely random access patterns, but our
cursor-based algorithm detects them and induces the proper amount of
read-ahead for each cursor. As shown in this figure, the time
required to read the test files using the cursor-based method is
at least 50% faster than using the default method. In the most
extreme case, the cursor-based method is 140% faster for the
8-stride reader on ide1.
We plan to investigate the effect SlowDown and the cursor-based read-ahead heuristics on a more complex and realistic workload (for example, adding a large number of metadata and write requests to the workload).
In our implementation of nfsheur cursors, no file handle may have more than a small and constant number of cursors open at any given moment. Access patterns such as those generated by Grid or MPI-like cluster workloads can benefit from an arbitrary number of cursors, and therefore would not fully benefit from our implementation.
In our simplistic architecture, it is inefficient to increase the number of cursors, because every file handle will reserve space for this number of cursors (whether they are ever used or not). It would be better to share a common pool of cursors among all file handles.
It would be interesting to see if the cursor heuristics are beneficial to file-based database systems such as MySQL (7) or Berkeley DB (25).
We have shown the effect of two new algorithms for computing the sequentiality count used by the read-ahead heuristic in the FreeBSD NFS server.
We have shown that improving the read-ahead heuristic by itself does not improve performance very much unless the nfsheur table is also made larger, and making nfsheur larger by itself is enough to achieve optimal performance for our benchmark. In addition, our changes to nfsheur are very minor and add no complexity to the NFS server.
We have also shown that a cursor-based algorithm for computing the read-ahead metric can dramatically improve the performance of stride-pattern readers.
Perhaps more importantly, we have discussed several important causes of variance or hidden effects in file system benchmarks, including the ZCAV effect, the interaction between tagged command queues and the disk scheduling algorithm, and the effect of using TCP vs UDP, and demonstrated the effects they may have on benchmarks.
The paper benefited enormously from the thoughtful comments from our reviewers and Chuck Lever, our paper shepherd. This work was funded in part by IBM.
The source code and documentation for the changes to
the NFS server and disk scheduler
described in
this paper, relative to FreeBSD 4.6 (or later),
are available at
https://www.eecs.harvard.edu/~ellard/NFS.
|
This paper was originally published in the
Proceedings of the
USENIX Annual Technical Conference (FREENIX Track),
June 9 – 14, 2003,
San Antonio, TX, USA
Last changed: 3 Jun 2003 aw |
|