| ||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Security '03 Paper
[Security '03 Technical Program]
Storage-based Intrusion Detection:
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Name | Description | Syscall redir. | Log scrub | Hidden dirs | Watched files | Total alerts |
| Ramen | Linux worm | - | - | X | 2 | 3 |
| 1ion | Linux worm | - | - | - | 10 | 10 |
| FK 0.4 | Linux LKM rootkit and trojan ssh | X | - | - | 1 | 1 |
| Taskigt | Linux LKM rootkit | - | - | - | 1 | 1 |
| SK 1.3a | Linux kernel rootkit via /dev/kmem | X | - | - | - | - |
| Darkside 0.2.3 | FreeBSD LKM rootkit | X | - | - | - | - |
| Knark 0.59 | Linux LKM rootkit | X | - | X | 1 | 2 |
| Adore | Linux LKM rootkit | X | - | - | - | - |
| lrk5 | User level rootkit from source | - | X | X | 20 | 22 |
| Sun rootkit | SunOS rootkit with trojan rlogin | - | - | - | 1 | 1 |
| FreeBSD Rootkit 2 | User level FreeBSD rootkit | - | X | X | 15 | 17 |
| t0rn | Linux user level rootkit | - | X | X | 20 | 22 |
| Advanced Rootkit | Linux user level rootkit | - | - | X | 10 | 11 |
| ASMD | Rootkit w/SUID binary trojan | - | - | X | 1 | 2 |
| Dica | Linux user level rootkit | - | X | X | 9 | 11 |
| Flea | Linux user level rootkit | - | X | X | 20 | 22 |
| Ohara | Rootkit w/PAM trojan | - | X | X | 4 | 6 |
| TK 6.66 | Linux user level rootkit | - | X | X | 10 | 12 |
| Table 1: | Visible actions of several intruder toolkits. For each of the tools, the table shows which of the following actions are performed: redirecting system calls, scrubbing the system log files, and creating hidden directories. It also shows how many of the files watched by our rule set are modified by a given tool. The final column shows the total number of alerts generated by a given tool. |
This section explores how well a storage IDS might fare in the face of actual compromises. To do so, we examined eighteen intrusion tools (Table 1) designed to be run on compromised systems. All were downloaded from public websites, most of them from Packet Storm [25].
Most of the actions taken by these tools fall into two categories. Actions in the first category involve hiding evidence of the intrusion and the rootkit’s activity. The second provides a mechanism for reentry into a system. Twelve of the tools operate by running various binaries on the host system and overwriting existing binaries to continue gaining control. The other six insert code into the operating system kernel.
For the analysis in this section, we focus on a subset of the rules supported by our prototype storage-based IDS described in Section 5. Specifically, we include the file/directory modification (Tripwire-like) rules, the append-only logfile rule, and the hidden filename rules. We do not consider any “suspicious content” rules, which may or may not catch a rootkit depending on whether its particular signature is known.1 In these eighteen toolkits, we did not find any instances of resource exhaustion attacks or of reverting inode times.
Of the eighteen toolkits tested, storage IDS rules would immediately detect fifteen based on their storage modifications. Most would trigger numerous alerts, highlighting their presence. The other three make no changes to persistent storage. However, they are removed if the system reboots; all three modify the kernel, but would have to be combined with system file changes to be re-inserted upon reboot.
Non-append changes to the system audit log. Seven of the eighteen toolkits scrub evidence of system compromise from the audit log. All of them do so by selectively overwriting entries related to their intrusion into the system, rather than by truncating the logfile entirely. All cause alerts to be generated in our prototype.
System file modification. Fifteen of the eighteen toolkits modify a number of watched system files (ranging from 1 to 20). Each such modification generates an alert. Although three of the rootkits replace the files with binaries that match the size and CRC checksum of the previous files, they do not foil cryptographically-strong hashes. Thus, Tripwire-like systems would be able to catch them as well, though the evasion mechanism described in Section 3.2 defeats Tripwire.
Many of the files modified are common utilities for system administration, found in /bin, /sbin, and /usr/bin on a UNIX machine. They are modified to hide the presence and activity of the intruder. Common changes include modifying ps to not show an intruder’s processes, ls to not show an intruder’s files, and netstat to not show an intruder’s open network ports and connections. Similar modifications are often made to grep, find, du, and pstree.
The other common reason for modifying system binaries is to create backdoors for system reentry. Most commonly, the target is telnetd or sshd, although one rootkit added a backdoored PAM module [32] as well. Methods for using the backdoor vary and do not impact our analysis.
Hidden file or directory names. Twelve of the rootkits make a hard-coded effort to hide their non-executable and working files (i.e., the files that are not replacing existing files). Ten of the kits use directories starting in a ‘.’ to hide from default ls listings. Three of these generate alerts by trying to make a hidden directory look like the reserved ‘.’ or ‘..’ directories by appending one or more spaces (‘. ’ or ‘.. ’). This also makes the path harder to type if a system administrator does not know the number of spaces.
Six of the eighteen toolkits modified the running operating system kernel. Five of these six “kernel rootkits” include loadable kernel modules (LKMs), and the other inserts itself directly into kernel memory by use of the /dev/kmem interface. Most of the kernel modifications allow intruders to hide as well as reenter the system, similarly to the file modifications described above. Especially interesting for this analysis is the use of exec() redirection by four of the kernel rootkits. With such redirection, the exec() system call uses a replacement version of a targeted program, while other system calls return information about or data from the original. As a result, any tool relying on the accuracy of system calls to check file integrity, such as Tripwire, will be fooled.
All of these rootkits are detected using our storage IDS rules--they all put their replacement programs in the originals’ directories (which are watched), and four of the six actually move the original file to a new name and store their replacement file with the original name (which also triggers an alert). However, future rootkits could be modified to be less obvious to a storage IDS. Specifically, the original files could be left untouched and replacement files could be stored someplace not watched by the storage IDS, such as a random user directory--neither would generate an alert. With this approach, file modification can be completely hidden from a storage IDS unless the rootkit wants to reinstall the kernel modification after a reboot. To accomplish this, some original files would need to be changed, which forces intruders to make an interesting choice: hide from the storage IDS or persist beyond the next reboot.
During the writing of this paper, one of the authors happened to be asked to analyze a system that had been recently compromised. Several modifications similar to those made by the above rootkits were found on the system. Root’s .bash_profile was modified to run the zap2 log scrubber, so that as soon as root logged into the system to investigate the intrusion, the related logs would be scrubbed. Several binaries were modified (ps, top, netstat, pstree, sshd, and telnetd). The binaries were setup to hide the existence of an IRC bot, running out of the directory `/dev/.. /'. This experience helps validate our choice of “rootkits” for study, as they appear to be representative of at least one real-world intrusion. This intrusion would have triggered at least 8 storage IDS rules.
To be useful in practice, a storage IDS must simultaneously achieve several goals. It must support a useful set of detection rules, while also being easy for human administrators to understand and configure. It must be efficient, minimizing both added delay and added resource requirements; some user communities still accept security measures only when they are “free.” Additionally, it should be invisible to users at least until an intrusion detection rule is matched.
This section describes four aspects of storage IDS design: specifying detection rules, administering a storage IDS securely, checking detection rules, and responding to suspicious activity.
Specifying rules for an IDS is a tedious, error prone activity. The tools an administrator uses to write and manipulate those rules should be as simple and straightforward as possible. Each of the four categories of suspicious activity presented earlier will likely need a unique format for rule specification.
The rule format used by Tripwire seems to work well for specifying rules concerned with data and attribute modification. This format allows an administrator to specify the pathname of a file and a list of properties that should be monitored for that file. The set of watchable properties are codified, and they include most file attributes. This rule language works well, because it allows the administrator to manipulate a well understood representation (pathnames and files), and the list of attributes that can be watched is small and well-defined.
The methods used by virus scanners work well for configuring an IDS to look for suspicious content. Rules can be specified as signatures that are compared against files’ contents. Similarly, filename expression grammars (like those provided in scripting languages) could be used to describe suspicious filenames.
Less guidance exists for the other two categories of warning signs: update patterns and content integrity. We do not currently know how to specify general rules for these categories. Our approach has been to fall back on Tripwire-style rules; we hard-code checking functions (e.g., for non-append update or a particular content integrity violation) and then allow an administrator to specify on which files they should be checked (or that they should be checked for every file). More general approaches to specifying detection rules for these categories of warning signs are left for future work.
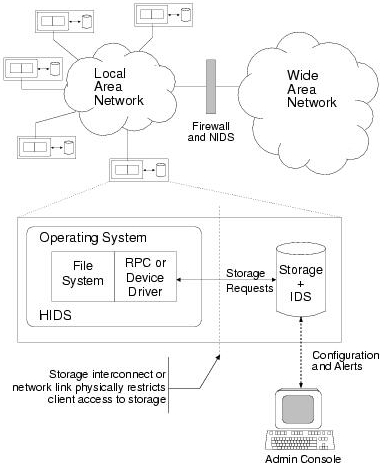
The security administrator must have a secure interface to the storage IDS. This interface is needed for the administrator to configure detection rules and to receive alerts. The interface must prevent client systems from forging or blocking administrative requests, since this could allow a crafty intruder to sneak around the IDS by disarming it. At a minimum, it must be tamper-evident. Otherwise, intruders could stop rule updates or prevent alerts from reaching the administrator. To maintain compromise independence, it must be the case that obtaining “superuser” or even kernel privileges on a client system is insufficient to gain administrative access to the storage device.
Two promising architectures exist for such administration: one based on physical access and one based on cryptography. For environments where the administrator has physical access to the device, a local administration terminal that allows the administrator to set detection rules and receive the corresponding alert messages satisfies the above goals.
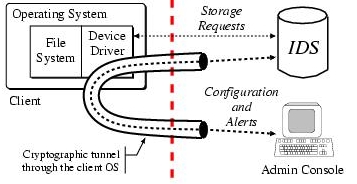
In environments where physical access to the device is not practical, cryptography can be used to secure communications. In this scenario, the storage device acts as an endpoint for a cryptographic channel to the administrative system. The device must maintain keys and perform the necessary cryptographic functions to detect modified messages, lost messages, and blocked channels. Architectures for such trust models in storage systems exist [13]. This type of infrastructure is already common for administration of other network-attached security components, such as firewalls or network intrusion detection systems. For direct-attached storage devices, cryptographic channels can be used to tunnel administrative requests and alerts through the OS of the host system, as illustrated in Figure 2. Such tunneling simply treats the host OS as an untrusted network component.
For small numbers of dedicated servers in a machine room, either approach is feasible. For large numbers of storage devices or components operating in physically insecure environments, cryptography is the only viable solution.
Checking detection rules can be non-trivial, because rules generally apply to full pathnames rather than inodes. Additional complications arise because rules can watch for files that do not yet exist.
For simple operations that act on individual files (e.g., READ and WRITE), rule verification is localized. The device need only check that the rules pertaining to that specific file are not violated (usually a simple flag comparison, sometimes a content check). For operations that affect the file system’s namespace, verification is more complicated. For example, a rename of a directory tree may impact a large number of individual files, any of which could have IDS rules that must be checked. Renaming a directory requires examining all files and directories that are children of the one being renamed.
In the case of rules pertaining to files that do not currently exist, this list of rules must be consulted when operations change the namespace. For example, the administrator may want to watch for the existence of a file named /a/b/c even if the directory named /a does not yet exist. However, a single file system operation (e.g., mv /z /a) could cause the watched file to suddenly exist, given the appropriate structure for z’s directory tree.
|
|
Since a detected “intruder action” may actually be legitimate user activity (i.e., a false alarm), our default response is simply to send an alert to the administrative system or the designated alert log file. The alert message should contain such information as the file(s) involved, the time of the event, the action being performed, the action’s attributes (e.g., the data written into the file), and the client’s identity. Note that, if the rules are set properly, most false positives should be caused by legitimate updates (e.g., upgrades) from an administrator. With the right information in alerts, an administrative system that also coordinates legitimate upgrades could correlate the generated alert (which can include the new content) with the in-progress upgrade; if this were done, it could prevent the false alarm from reaching the human administrator while simultaneously verifying that the upgrade went through to persistent storage correctly.
There are more active responses that a storage IDS could trigger upon detecting suspicious activity. When choosing a response policy, of course, the administrator must weigh the benefits of an active response against the inconvenience and potential damage caused by false alarms.
One reasonable active response is to slow down the suspected intruder’s storage accesses. For example, a storage device could wait until the alert is acknowledged before completing the suspicious request. It could also artificially increase request latencies for a client or user that is suspected of foul play. Doing so would provide increased time for a more thorough response, and, while it will cause some annoyance in false alarm situations, it is unlikely to cause damage. The device could even deny a request entirely if it violates one of the rules, although this response to a false alarm could cause damage and/or application failure. For some rules, like append-only audit logs, such access control may be desirable.
Liu, et al. proposed a more radical response to detected intrusions: isolating intruders, via versioning, at the file system level [21]. To do so, the file system forks the version trees to sandbox suspicious users until the administrator verifies the legitimacy of their actions. Unfortunately, such forking is likely to interfere with system operation, unless the intrusion detection mechanism yields no false alarms. Specifically, since suspected users modify different versions of files from regular users, the system faces a difficult reintegration [19, 40] problem, should the updates be judged legitimate. Still, it is interesting to consider embedding this approach, together with a storage IDS, into storage systems for particularly sensitive environments.
A less intrusive storage-embedded response is to start versioning all data and auditing all storage requests when an intrusion is detected. Doing so provides the administrator with significant information for post-intrusion diagnosis and recovery. Of course, some intrusion-related information will likely be lost unless the intrusion is detected immediately, which is why Strunk et al. [37] argue for always doing these things (just in case). Still, IDS-triggered employment of this functionality may be a useful trade-off point.
To explore the concepts and feasibility of storage-based intrusion detection, we implemented a storage IDS in an NFS server. Unmodified client systems access the server using the standard NFS version 2 protocol [39]2, while storage-based intrusion detection occurs transparently. This section describes how the prototype storage IDS handles detection rule specification, the structures and algorithms for checking rules, and alert generation.
The base NFS server is called S4, and its implementation is described and evaluated elsewhere [37]. It internally performs file versioning and request auditing, using a log-structured file system [31], but these features are not relevant here. For our purposes, it is a convenient NFS file server with performance comparable to the Linux and FreeBSD NFS servers. Secure administration is performed via the server’s console, using the physical access control approach.
| |||||||||||||||||||||||||||||||||||||||
In addition to per-file rules, an administrator can choose to enable any of three system-wide rules: one that matches on any operation that rolls-back a file’s modification time, one that matches on any operation that creates a “hidden” directory (e.g., a directory name beginning with ‘.’ and having spaces in it), and one that looks for known (currently hard-coded) intrusion tools by their sizes and SHA-1 digests. Although the system currently checks the digests on every file update, periodic scanning of the system would likely be more practical. These rules apply to all parts of the directory hierarchy and are specified as simply ON or OFF.
Rules are communicated to the server through the use of an administrative RPC. This RPC interface has two commands (see Table 3). The setRule() RPC gives the IDS two values: the path of the file to be watched, and a set of flags describing the specific rules for that file. Rules are removed through the same mechanism, specifying the path and an empty rule set.
|
This subsection describes the core of the storage IDS. It discusses how rules are stored and subsequently checked during operation.
Three new structures allow the storage IDS to efficiently support the detection rules: the reverse lookup table, the inode watch flags, and the non-existent names table.
Reverse lookup table: The reverse lookup table serves two functions. First, it serves as a list of rules that the server is currently enforcing. Second, it maps an inode number to a pathname. The alert generation mechanism uses the latter to provide the administrator with file names instead of inode numbers, without resorting to a brute-force search of the namespace.
The reverse lookup table is populated via the setRule() RPC. Each rule’s full pathname is broken into its component names, which are stored in distinct rows of the table. For each component, the table records four fields: inode-number, directory-inode-number, name, and rules. Indexed by inode-number, an entry contains the name within a parent directory (identified by its directory-inode-number). The rules associated with this name are a bitmask of the attributes and patterns to watch. Since a particular inode number can have more than one name, multiple entries for each inode may exist. A given inode number can be translated to a full pathname by looking up its lowest-level name and recursively looking up the name of the corresponding directory inode number. The search ends with the known inode number of the root directory. All names for an inode can be found by following all paths given by the lookup of the inode number.
Inode watchflags field: During the setRule() RPC, in addition to populating the reverse lookup table, a rule mask of 16 bits is computed and stored in the watchflags field of the watched file’s inode. Since multiple pathnames may refer to the same inode, there may be more than one rule for a given file, and the mask contains the union. The inode watchflags field is a performance enhancement designed to co-locate the rules governing a file with that file’s metadata. This field is not necessary for correctness since the pertinent data could be read from the reverse lookup table. However, it allows efficient verification of detection rules during the processing of an NFS request. Since the inode is read as part of any file access, most rule checking becomes a simple mask comparison.
Non-existent names table: The non-existent names table lists rules for pathnames that do not currently exist. Each entry in the table is associated with the deepest-level (existing) directory within the pathname of the original rule. Each entry contains three fields: directory-inode-number, remaining-path, and rules. Indexed by directory-inode-number, an entry specifies the remaining-path. When a file or directory is created or removed, the non-existent names table is consulted and updated, if necessary. For example, upon creation of a file for which a detection rule exists, the rules are checked and inserted in the watchflags field of the inode. Together, the reverse lookup table and the non-existent names table contain the entire set of IDS rules in effect.
|
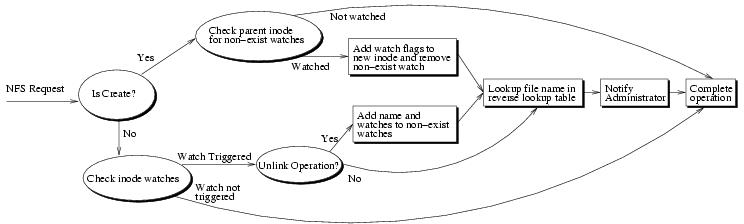
We now describe the flow of rule checking, much of which is diagrammed in Figure 3, in two parts: changes to individual files and changes to the namespace.
Checking rules on individual file operations: For each NFS operation that affects only a single file, a mask of rules that might be violated is computed. This mask is compared, bitwise, to the corresponding watchflags field in the file’s inode. For most of the rules, this comparison quickly determines if any alerts should be triggered. If the “password file” or “append only” flags are set, the corresponding verification function executes to determine if the rule is violated.
Checking rules on namespace operations: Namespace operations can cause watched pathnames to appear or disappear, which will usually trigger an alert. For operations that create watched pathnames, the storage IDS moves rules from the non-existent names table to the reverse lookup table. Conversely, operations that delete watched pathnames cause rules to move between tables in the opposite direction.
When a name is created (via CREATE, MKDIR, LINK, or SYMLINK) the non-existent names table is checked. If there are rules for the new file, they are checked and placed in the watchflags field of the new inode. In addition, the corresponding rule is removed from the non-existent names table and is added to the reverse lookup table. During a MKDIR, any entries in the non-existent names table that include the new directory as the next step in their remaining path are replaced; the new entries are indexed by the new directory’s inode number and its name is removed from the remaining path.
When a name is removed (via UNLINK or RMDIR), the watchflags field of the corresponding inode is checked for rules. Most such rules will trigger an alert, and an entry for them is also added to the non-existent names table. For RMDIR, the reverses of the actions for MKDIR are necessary. Any non-existent table entries parented on the removed directory must be modified. The removed directory’s name is added to the beginning of each remaining path, and the directory inode number in the table is modified to be the directory’s parent.
By far, the most complex namespace operation is a RENAME. For a RENAME of an individual file, modifying the rules is the same as a CREATE of the new name and a REMOVE of the old. When a directory is renamed, its subtrees must be recursively checked for watched files. If any are found, and once appropriate alerts are generated, their rules and pathname up to the parent of the renamed directory are stored in the non-existent names table, and the watchflags field of the inode is cleared. Then, the non-existent names table must be checked (again recursively) for any rules that map into the directory’s new name and its children; such rules are checked, added to the inode’s watchflags field, and updated as for name creation.
Alerts are generated and sent immediately when a detection rule is triggered. The alert consists of the original detection rule (pathname and attributes watched), the specific attributes that were affected, and the RPC operation that triggered the rule. To get the original rule information, the reverse lookup table is consulted. If a single RPC operation triggers multiple rules, one alert is sent for each.
Because NFS traffic goes over a traditional network, the detection rules described for our prototype storage IDS could be implemented in a NIDS. However, this would involve several new costs. First, it would require the NIDS to watch the LAN links that carry NFS activity. These links are usually higher bandwidth than the Internet uplinks on which most NIDSs are used.3 Second, it would require that the NIDS replicate a substantial amount of work already performed by the NFS server, increasing the CPU requirements relative to an in-server storage IDS. Third, the NIDS would have to replicate and hold substantial amounts of state (e.g. mappings of file handles to their corresponding files). Our experiences checking rules against NFS traces indicate that this state grows rapidly because the NFS protocol does not expose to the network (or the server) when such state can be removed. Even simple attribute updates cannot be checked without caching the old values of the attributes, otherwise the NIDS could not distinguish modified attributes from reapplied values. Fourth, rules cannot always be checked by looking only at the current command. The NIDS may need to read file data and attributes to deal with namespace operations, content integrity checks, and update pattern rules. In addition to the performance penalty, this requires giving the NIDS read permission for all NFS files and directories.
Given all of these issues, we believe that embedding storage IDS checks directly into the storage component is more appropriate.
This section evaluates the costs of our storage IDS in terms of performance impact and memory required--both costs are minimal.
All experiments use the S4 NFS server, with and without the new support for storage-based intrusion detection. The client system is a dual 1 GHz Pentium III with 128 MB RAM and a 3Com 3C905B 100 Mbps network adapter. The server is a dual 700 MHz Pentium III with 512 MB RAM, a 9 GB 10,000 RPM Quantum Atlas 10K II drive, an Adaptec AIC-7896/7 Ultra2 SCSI controller, and an Intel EtherExpress Pro 100 Mb network adapter. The client and server are on the same 100 Mb network switch. The operating system on all machines is Red Hat Linux 6.2 with Linux kernel version 2.2.14.
SSH-build was constructed as a replacement for the Andrew file system benchmark [14, 35]. It consists of 3 phases: The unpack phase, which unpacks the compressed tar archive of SSH v. 1.2.27 (approximately 1 MB in size before decompression), stresses metadata operations on files of varying sizes. The configure phase consists of the automatic generation of header files and makefiles, which involves building various small programs that check the existing system configuration. The build phase compiles, links, and removes temporary files. This last phase is the most CPU intensive, but it also generates a large number of object files and a few executables. Both the server and client caches are flushed between phases.
PostMark was designed to measure the performance of a file system used for electronic mail, netnews, and web based services [16]. It creates a large number of small randomly-sized files (between 512 B and 16 KB) and performs a specified number of transactions on them. Each transaction consists of two sub-transactions, with one being a create or delete and the other being a read or append. The default configuration used for the experiments consists of 100,000 transactions on 20,000 files, and the biases for transaction types are equal.
|
The storage IDS checks a file’s rules before any operation that could possibly trigger an alert. This includes READ operations, since they may change a file’s last access time. Additionally, namespace-modifying operations require further checks and possible updates of the non-existent names table. To understand the performance consequences of the storage IDS design, we ran PostMark and SSH-Build tests. Since our main concern is avoiding a performance loss in the case where no rule is violated, we ran these benchmarks with no relevant rules set. As long as no rules match, the results are similar with 0 rules, 1000 rules on existing files, or 1000 rules on non-existing files. Table 4 shows that the performance impact of the storage IDS is minimal. The largest performance difference is for the configure and build phases of SSH-build, which involve large numbers of namespace operations.
Microbenchmarks on specific filesystem actions help explain the overheads. Table 5 shows results for the most expensive operations, which all affect the namespace. The performance differences are caused by redundancy in the implementation. The storage IDS code is kept separate from the NFS server internals, valuing modularity over performance. For example, name removal operations involve a redundant directory lookup and inode fetch (from cache) to locate the corresponding inode’s watchflags field.
Rules take very little time to generate alerts. For example, a write to a file with a rule set takes 4.901 milliseconds if no alert is set off. If an alert is set off the time is 4.941 milliseconds. These represent the average over 1000 trials, and show a .8% overhead.
|
The storage IDS structures are stored on disk. To avoid extra disk accesses for most rule checking, though, it is important that they fit in memory.
Three structures are used to check a set of rules. First, each inode in the system has an additional two-byte field for the bitmask of the rules on that file. There is no cost for this, because the space in the inode was previously unused. Linux’s ext2fs and BSD’s FFS also have sufficient unused space to store such data without increasing their inode sizes. If space were not available, the reverse lookup table can be used instead, since it provides the same information. Second, for each pathname component of a rule, the reverse lookup table requires 20 + N bytes: a 16-byte inode number, 2 bytes for the rule bitmask, and N + 2 bytes for a pathname component of length N. Third, the non-existent names table contains one entry for every file being watched that does not currently exist. Each entry consumes 274 bytes: a 16-byte inode number, 2 bytes for the rule bitmask, and 256 bytes for the maximum pathname supported.
To examine a concrete example of how an administrator might use this system, we downloaded the open source version of Tripwire [41]. Included with it is an example rule file for Linux, containing (after expanding directories to lists of files) 4730 rules. We examined a Red Hat Linux 6.1 [30] desktop machine to obtain an idea of the number of watched files that actually exist on the hard drive. Of the 4730 watched files, 4689 existed on our example system. Using data structure sizes from above, reverse lookup entries for the watched files consume 141 KB. Entries in the non-existent name table for the remaining 41 watched files consume 11 KB. In total, only 152 KB are needed for the storage IDS.
We have explored the false positive rate of storage-based intrusion detection in several ways.
To evaluate the file watch rules, two months of traces of all file system operations were gathered on a desktop machine in our group. We compared the files modified on this system with the watched file list from the open source version of Tripwire. This uncovered two distinct patterns where files were modified. Nightly, the user list (/etc/passwd) on the machine was overwritten by a central server. Most nights it does not change but the create and rename performed would have triggered an alert. Additionally, multiple binaries in the system were replaced over time by the administrative upgrade process. In only one case was a configuration file on the system changed by a local user.
For alert-triggering modifications arising from explicit administrative action, a storage IDS can provide an added benefit. If an administrator pre-informs the admin console of updated files before they are distributed to machines, the IDS can verify that desired updates happen correctly. Specifically, the admin console can read the new contents via the admin channel and verify that they are as intended. If so, the update is known to have succeeded, and the alert can be suppressed.
We have also performed two (much) smaller studies. First, we have evaluated our “hidden filename” rules by examining the entire filesystems of several desktops and servers--we found no uses of any of them, including the ‘.’ or ‘..’ followed by any number of spaces discussed above. Second, we evaluated our “inode time reversal” rules by examining lengthy traces of NFS activity from our environment and from two Harvard environments [8]--we found a sizable number of false positives, caused mainly by unpacking archives with utilities like tar. Combined with the lack of time reversal in any of the toolkits, use of this rule may be a bad idea.
Much related work has been discussed within the flow of the paper. For emphasis, we note that there have been many intrusion detection systems focused on host OS activity and network communication; Axelsson [1] recently surveyed the state-of-the-art. Also, the most closely related tool, Tripwire [17], was used as an initial template for our prototype’s file modification detection ruleset.
Garfinkel et al. [12] suggest using a virtual machine (VM) for building a secure host-based IDS. Since an operating system inside of a VM has strong isolation from its host, an IDS running outside of the VM is protected from intruder actions. They give their IDS knowledge of the operating system structures inside the VM. This gives their system the power of a HIDS, it has the ability to watch all operating system actions, but similar compromise independence to storage-based intrusion detection.
Perhaps the most closely related work is the original proposal for self-securing storage [37], which argued for storage-embedded support for intrusion survival. Self-securing storage retains every version of all data and a log of all requests for a period of time called the detection window. For intrusions detected within this window, security administrators have a wealth of information for post-intrusion diagnosis and recovery.
Such versioning and auditing complements storage-based intrusion detection in several additional ways. First, when creating rules about storage activity for use in detection, administrators can use the latest audit log and version history to test new rules for false alarms. Second, the audit log could simplify implementation of rules looking for patterns of requests. Third, administrators can use the history to investigate alerts of suspicious behavior (i.e., to check for supporting evidence within the history). Fourth, since the history is retained, a storage IDS can delay checks until the device is idle, allowing the device to avoid performance penalties for expensive checks by accepting a potentially longer detection latency.
A storage IDS watches system activity from a new viewpoint, which immediately exposes some common intruder actions. Running on separate hardware, this functionality remains in place even when client OSes or user accounts are compromised. Our prototype storage IDS demonstrates both feasibility and efficiency within a file server. Analysis of real intrusion tools indicates that most would be immediately detected by a storage IDS. After adjusting for storage IDS presence, intrusion tools will have to choose between exposing themselves to detection or being removed whenever the system reboots.
In continuing work, we are developing a prototype storage IDS embedded in a device exporting a block-based interface (SCSI). To implement the same rules as our augmented NFS server, such a device must be able to parse and traverse the on-disk metadata structures of the file system it holds. For example, knowing whether /usr/sbin/sshd has changed on disk requires knowing not only whether the corresponding data blocks have changed, but also whether the inode still points to the same blocks and whether the name still translates to the same inode. We have developed this translation functionality for two popular file systems, Linux’s ext2fs and FreeBSD’s FFS. The additional complexity required is small (under 200 lines of C code for each), simple (under 3 days of programming effort each), and changes infrequently (about 5 years between incompatible changes to on-disk structures). The latter, in particular, indicates that device vendors can deploy firmware and expect useful lifetimes that match the hardware. Sivathanu et al. [36] have evaluated the costs and benefits of device-embedded FS knowledge more generally, finding that it is feasible and valuable.
Another continuing direction is exploration of less exact rules and their impact on detection and false positive rates. In particular, the potential of pattern matching rules and general anomaly detection for storage remains unknown.
[1] Stefan Axelsson. Research in intrusion-detection systems: a survey. Technical report 98-17. Department of Computer Engineering, Chalmers University of Technology, December 1998.
[2] Matt Bishop and Michael Dilger. Checking for race conditions in file accesses. Computing Systems, 9(2):131-152, Spring 1996.
[3] Miguel Castro and Barbara Liskov. Proactive recovery in a Byzantine-fault-tolerant system. Symposium on Operating Systems Design and Implementation (San Diego, CA, 23-25 October 2000), pages 273-287. USENIX Association, 2000.
[4] Peter M. Chen and Brian D. Noble. When virtual is better than real. Hot Topics in Operating Systems (Elmau, Germany, 20-22 May 2001), pages 133-138. IEEE Comput. Soc., 2001.
[5] B. Cheswick and S. Bellovin. Firewalls and Internet security: repelling the wily hacker. Addison-Wesley, Reading, Mass. and London, 1994.
[6] Dorothy Denning. An intrusion-detection model. IEEE Transactions on Software Engineering, SE-13(2):222-232, February 1987.
[7] Dorothy E. Denning. Information warfare and security. Addison-Wesley, 1999.
[8] Daniel Ellard, Jonathan Ledlie, Pia Malkani, and Margo Seltzer. Passive NFS tracing of an email and research workload. Conference on File and Storage Technologies (San Francisco, CA, 31 March-2 April 2003), pages 203-217. USENIX Association, 2003.
[9] Dan Farmer. What are MACtimes? Dr. Dobb’s Journal, 25(10):68-74, October 2000.
[10] Stephanie Forrest, Setven A. Hofmeyr, Anil Somayaji, and Thomas A. Longstaff. A sense of self for UNIX processes. IEEE Symposium on Security and Privacy (Oakland, CA, 6-8 May 1996), pages 120-128. IEEE, 1996.
[11] Gregory R. Ganger, Gregg Economou, and Stanley M. Bielski. Finding and Containing Enemies Within the Walls with Self-securing Network Interfaces. Carnegie Mellon University Technical Report CMU-CS-03-109. January 2003.
[12] Tal Garfinkel and Mendel Rosenblum. A virtual machine introspection based architecture for intrusion detection. NDSS (San Diego, CA, 06-07 February 2003). The Internet Society, 2003.
[13] Howard Gobioff. Security for a high performance commodity storage subsystem. PhD thesis, published as TR CMU-CS-99-160. Carnegie-Mellon University, Pittsburgh, PA, July 1999.
[14] John H. Howard, Michael L. Kazar, Sherri G. Menees, David A. Nichols, M. Satyanarayanan, Robert N. Sidebotham, and Michael J. West. Scale and performance in a distributed file system. ACM Transactions on Computer Systems, 6(1):51-81, February 1988.
[15] Y. N. Huang, C. M. R. Kintala, L. Bernstein, and Y. M. Wang. Components for software fault-tolerance and rejuvenation. AT&T Bell Laboratories Technical Journal, 75(2):29-37, March-April 1996.
[16] Jeffrey Katcher. PostMark: a new file system benchmark. Technical report TR3022. Network Appliance, October 1997.
[17] Gene H. Kim and Eugene H. Spafford. The design and implementation of Tripwire: a file system integrity checker. Conference on Computer and Communications Security (Fairfax, VA, 2-4 November 1994), pages 18-29. ACM, 1994.
[18] Calvin Ko, Manfred Ruschitzka, and Karl Levitt. Execution monitoring of security-critical programs in distributed systems: a specification-based approach. IEEE Symposium on Security and Privacy (Oakland, CA, 04-07 May 1997), pages 175-187. IEEE, 1997.
[19] Puneet Kumar and M. Satyanarayanan. Flexible and safe resolution of file conflicts. USENIX Annual Technical Conference (New Orleans, LA, 16-20 January 1995), pages 95-106. USENIX Association, 1995.
[20] Robert Lemos. Putting fun back into hacking. ZDNet News, 5 August 2002. http: //zdnet.com.com/2100-1105-948404.html.
[21] Peng Liu, Sushil Jajodia, and Catherine D. McCollum. Intrusion confinement by isolation in information systems. IFIP Working Conference on Database Security (Seattle, WA, 25-28 July 1999), pages 3-18. IFIP, 2000.
[22] Teresa F. Lunt and R. Jagannathan. A prototype real-time intrusion-detection expert system. IEEE Symposium on Security and Privacy (Oakland, CA, 18-21 April 1988), pages 59-66. IEEE, 1988.
[23] McAfee NetShield for Celerra. EMC Corporation, August 2002. https://www.emc.com/ pdf/partnersalliances/einfo/McAfee_netshield.pdf.
[24] NFR Security. https://www.nfr.net/, August 2002.
[25] Packet Storm Security. Packet Storm, 26 January 2003. https://www. packetstormsecurity.org/.
[26] Vern Paxson. Bro: a system for detecting network intruders in real-time. USENIX Security Symposium (San Antonio, TX, 26-29 January 1998), pages 31-51. USENIX Association, 1998.
[27] John Phillips. Antivirus scanning best practices guide. Technical report 3107. Network Appliance Inc. https://www.netapp.com/tech_library/3107.html.
[28] Phillip A. Porras and Peter G. Neumann. EMERALD: event monitoring enabling responses to anomalous live disturbances. National Information Systems Security Conference, pages 353-365, 1997.
[29] Wojciech Purczynski. GNU fileutils - recursive directory removal race condition. BugTraq mailing list, 11 March 2002.
[30] Red Hat Linux 6.1, 4 March 1999. ftp://ftp.redhat.com/pub/redhat/linux/6.1/.
[31] Mendel Rosenblum and John K. Ousterhout. The design and implementation of a log-structured file system. ACM Transactions on Computer Systems, 10(1):26-52. ACM Press, February 1992.
[32] Vipin Samar and Roland J. Schemers III. Unified login with pluggable authentication modules (PAM). Open Software Foundation RFC 86.0. Open Software Foundation, October 1995.
[33] Joel Scambray, Stuart McClure, and George Kurtz. Hacking exposed: network security secrets & solutions. Osborne/McGraw-Hill, 2001.
[34] Bruce Schneier and John Kelsey. Secure audit logs to support computer forensics. ACM Transactions on Information and System Security, 2(2):159-176. ACM, May 1999.
[35] Margo I. Seltzer, Gregory R. Ganger, M. Kirk McKusick, Keith A. Smith, Craig A. N. Soules, and Christopher A. Stein. Journaling versus Soft Updates: Asynchronous Meta-data Protection in File Systems. USENIX Annual Technical Conference (San Diego, CA, 18-23 June 2000), 2000.
[36] Muthian Sivathanu, Vijayan Prabhakaran, Florentina I. Popovici, Timothy E. Denehy, Andrea C. Arpaci-Dusseau, and Remzi H. Arpaci-Dusseau. Semantically-smart disk systems. Conference on File and Storage Technologies (San Francisco, CA, 31 March-2 April 2003), pages 73-89. USENIX Association, 2003.
[37] John D. Strunk, Garth R. Goodson, Michael L. Scheinholtz, Craig A. N. Soules, and Gregory R. Ganger. Self-securing storage: protecting data in compromised systems. Symposium on Operating Systems Design and Implementation (San Diego, CA, 23-25 October 2000), pages 165-180. USENIX Association, 2000.
[38] Jeremy Sugerman, Ganesh Venkitachalam, and Beng-Hong Lim. Virtualizing I/O Devices on VMware Workstation’s Hosted Virtual Machine Monitor. USENIX Annual Technical Conference (Boston, MA, 25-30 June 2001), pages 1-14. USENIX Association, 2001.
[39] Sun Microsystems. NFS: network file system protocol specification, RFC-1094, March 1989.
[40] Douglas B. Terry, Marvin M. Theimer, Karin Petersen, Alan J. Demers, Mike J. Spreitzer, and Carl H. Hauser. Managing update conflicts in Bayou, a weakly connected replicated storage system. ACM Symposium on Operating System Principles (Copper Mountain Resort, CO, 3-6 December 1995). Published as Operating Systems Review, 29(5), 1995.
[41] Tripwire Open Souce 2.3.1, August 2002. https://ftp4.sf.net/sourceforge/tripwire/ tripwire-2.3.1-2.tar.gz.
[42] Kalyanaraman Vaidyanathan, Richard E. Harper, Steven W. Hunter, and Kishor S. Trivedi. Analysis and implementation of software rejuvenation in cluster systems. ACM SIGMETRICS Conference on Measurement and Modeling of Computer Systems (Cambridge, MA, 16-20 June 2002). Published as Performance Evaluation Review, 29(1):62-71. ACM Press, 2002.
|
This paper was originally published in the
Proceedings of the 12th USENIX Security Symposium,
August 4–8, 2003,
Washington, DC, USA
Last changed: 19 Dec. 2003 ch |
|