This choice of nodes may be dictated by a number of factors, depending on the application's characteristics. ``Compute-intensive'' applications might be particularly concerned about spare CPU, physical memory, and disk capacity on candidate nodes. ``Network-intensive'' applications, such as content distribution networks and security monitoring applications, might be particularly concerned about placing service instances at particular network locations--near potential users or at well-distributed locations in a topology--and on nodes with low-latency, high-bandwidth links among themselves. Other applications, such as distributed multiplayer games, may be concerned about both types of node attributes, e.g., low load for game logic processing and low latency to users for good interactive performance.
To automate this node selection process, we have built SWORD--a decentralized resource discovery service that is designed to satisfy queries over an extensible set of per-node and inter-node measurements that are relevant to deciding on which nodes of an infrastructure to place instances of distributed applications. This paper focuses on SWORD's PlanetLab deployment and the lessons we have learned from it. The key features of SWORD's operation on PlanetLab are its scalable, distributed query processor for satisfying the multi-attribute range queries that describe application resource requirements, and its ability to support queries over not just per-node characteristics such as load, but also over inter-node characteristics such as inter-node latency. Other features of SWORD are described in [11].
A SWORD user begins by specifying requirements for a set of nodes. Resources are described as a topology of interconnected groups with required intra-group, inter-group, and per-node characteristics. For example, a content distribution service for streaming media might want several ``virtual clusters'' of nodes, with each cluster near one portion of its geographically distributed user base. Each cluster is an equivalence class that would be composed of machines with sufficient disk space and with sufficiently low latency among nodes in each group to enable cooperative caching.
SWORD users specify a range of required and preferred values of per-node and inter-node resource measurements, with varying levels of penalties for selecting nodes that are within the required range but outside the preferred range. For example, the content distribution service might desire 20 ms latency or less among all nodes within each virtual cluster. However, under constraint, the service might be satisfied with latencies up to 40 ms, with correspondingly higher penalty. Latencies greater than 40 ms may be insufficient to support desired performance, corresponding to infinite penalty. SWORD endeavors to locate the lowest-penalty configuration that still meets the user's requirements.
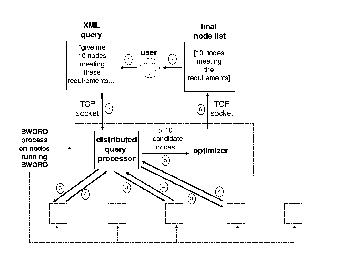
SWORD's high-level architecture appears in Figure 1. The user writes a query expressed in XML (1) and sends it over a TCP socket to any node running SWORD (2). The query is received by the SWORD distributed query processor component on that node, which issues a distributed range query corresponding to the requirements of the requested groups (3). Once all of the results are returned from the distributed range query (4), these ``candidate'' nodes and their associated measurements are passed to the optimizer (5). The optimizer selects a penalty-minimizing subset of the candidate nodes and returns a list of them (along with the attribute measurements that led to their being selected) to the user (6 and 7). Note that although the optimization algorithm is not parallelized, if users employ a mechanism such as DNS round-robin to choose the SWORD entry point node for each query, then the optimization is effectively parallelized on a per-query basis.