
Our prototype Base implementation (written in Java) is called the MultiSpace. It serves to demonstrate the effectiveness of our architecture in terms of facilitating the construction of flexible services, and to allow us to begin explorations into the issues of our platform's scalability. The MultiSpace implementation has three layers: the bottom layer is a set of communications primitives (NinjaRMI); the middle layer is a single-node execution environment (the iSpace); and the top layer is a set of multiple node abstractions (the MultiSpace layer). We describe each of these in turn, from the bottom up.
A rich set of high performance communications primitives is a necessary component of any clustered environment. We chose to make heavy use of Java's Remote Method Invocation (RMI) facilities for performing RPC-like [5] calls across nodes in the cluster, and between clients and services. When a caller invokes an RMI method, stub code intercepts the invocation, marshalls arguments, and sends them to a remote ``skeleton'' method handler for unmarshalling and execution. Using RMI as the finest granularity communication data unit in our clustered environment has many useful properties. Because method invocations have completely encapsulated, atomic semantics, retransmissions or communication failures are easy to reason about--they correspond to either successful or failed method invocations, rather than partial data transmissions.
However, from the point of view of clients, if a remote method invocation does not successfully return, it can be impossible for the client to know whether or not the method was successfully invoked on the server. The client has two choices: it can reinvoke the method call (and risk calling the same method twice), or it can assume that the method was not invoked, risking that the method was in fact invoked, successfully or unsuccessfully with an exception, but results were not returned to the client. Currently, on failure our Redirector Stubs will retry using a different, randomly chosen service stub; in the case of many successive failures, the Redirector Stub will return an exception to the caller. It is because of the at-least-once semantics implied by these client-side reinvocations that we must require services to be idempotent. The exploration of different retry policies inside the Redirector Stubs is an area of future research.
NinjaRMI is a ground-up reimplementation of Sun's Java Remote Method Invocation for use by components within the Ninja system. NinjaRMI was designed to permit maximum flexibility in implementation options. NinjaRMI provides three interesting transport-level RMI enhancements. First, it provides a unicast, UDP-based RMI that allows clients to call methods with ``best-effort'' semantics. If the UDP packet containing the marshalled arguments successfully arrives at the service, the method is invoked; if not, no retransmissions are attempted. Because of this, we enforce the requirement that such methods do not have any return values. This transport is useful for beacons, log entries, or other such side-effect oriented uses that do not require reliability. Our second enhancement is a multicast version of this unreliable transport. RMI services can associate themselves with a multicast group, and RMI calls into that multicast group result in method invocations on all listening services. Our third enhancement is to provide very flexible certificate-based authentication and encryption support for reliable, unicast RMI. Endpoints in an RMI session can associate themselves with digital certificates issued by a certification authority. When the TCP-connection underlying an RMI session is established, these certificates are exchanged by the RMI layer and verified at each endpoint. If the certificate verification succeeds, the remainder of the communication over that TCP connection is encrypted using a Triple DES session key obtained from a Diffie-Hellman key exchange. These security enhancements are described in [12].
Packaged along with our NinjaRMI implementation is an interface compiler which, when given an object that exports an RMI interface, generates the client-side stub and server-side skeleton stubs for that object. All source code for stubs and skeletons can be generated dynamically at run-time, allowing the Ninja system to leverage the use of an intelligent code-generation step when constructing wrappers for service components. We use this to introduce the level of indirection needed to implement Redirector Stubs--stubs can be overloaded to cause method invocations to occur on many remote nodes, or for method invocations to fail over to auxiliary nodes in the case of a primary node's failure.
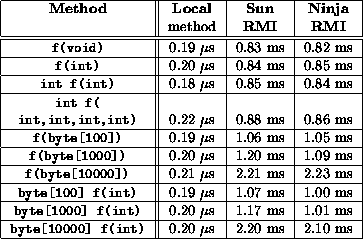
Table 1:
NinjaRMI microbenchmarks: These benchmarks were gathered on two
400Mhz Pentium II based machines, each with 128MB of physical memory,
connected by a switched 100 Mb/s Ethernet, and using Sun's JDK 1.1.6v2 with
the TYA just-in-time compiler on Linux 2.0.36. For the sake of comparison,
UDP round-trip times between two C programs were measured at 0.185 ms, and
between two Java programs at 0.316 ms.
As shown in table 1, NinjaRMI performs as well as or better than Sun's Java RMI package. Given that a null RMI invocation cost 0.82 ms and that a round-trip across the network and through the JVMs cost 0.316 ms, we conclude that the difference (roughly 0.5 ms) is RMI marshalling and protocol overhead. Profiling the code shows that the main contributor to this overhead is object serialization, specifically the use of methods such as java.io.ObjectInputStream.read().
A Base consists of a number of workstations, each running a suitable receptive execution environment for single-node service components. In our prototype, this receptive execution environment is the iSpace: a Java Virtual Machine (JVM) that runs a component loading service into which Java classes can be pushed as needed. The iSpace is responsible for managing component resources, naming, protection, and security. The iSpace exports the component loader interface via NinjaRMI; this interface allows a remote client to obtain a list of components running on the iSpace, obtain an RMI stub to a particular component, and upload a new service component or kill a component already running on the iSpace (subject to authentication). Service components running on the iSpace are protected from one another and from the surrounding execution environment in three ways:
Other assumptions must be made in order to make this approach viable. In essence, we are relying on the JVM to behave and perform like a miniature operating system, even though it was not designed as such. For example, the Java Virtual Machine does not provide adequate protection between threads of multiple components running within the same JVM: one component could, for example, consume the entire CPU by running indefinitely within a non-blocking thread. Here, we must assume that the JVM employs a preemptive thread scheduler (as is true in the Sun's Solaris Java environment) and that fairness can be guaranteed through its use. Likewise, the iSpace Security Manager must utilize a strategy for resource management which ensures both fairness and safety. In this respect iSpace has similar goals to other systems which provide multiple protection domains within a single JVM, such as the JKernel [16]. However, our approach does not necessitate a re-engineering of the Java runtime libraries, particularly because intra-JVM thread communication is not a high-priority feature.
The highest layer in our implementation is the MultiSpace layer, which tethers together a collection of iSpaces (figure 3). A primary function of this layer is to provide each iSpace with a replicated registry of all service instances running in the cluster.
A MultiSpace service inherits from an abstract MultiSpaceService class,
whose constructor registers each service instance with a
``MultiSpaceLoader'' running on the local iSpace. All MultiSpaceLoaders in
a cluster cooperate to maintain the replicated registry; each one
periodically sends out a multicast beacon that carries its list of local services to all other nodes in the
MultiSpace, and also listens for multicast messages from other MultiSpace
nodes. Each MultiSpaceLoader builds an independent version of the registry
from these beacons. The registries are thus soft-state, similar in nature
to the cluster state maintained in [11] and [1]--if an
iSpace node goes down and comes back up, its MultiSpaceLoader simply has to
listen to the multicast channel to rebuild its state. Registries on
different nodes may see temporary periods of inconsistency as services are
pushed into the MultiSpace or moved across nodes in the MultiSpace, but in
steady state, all nodes asymptotically approach consistency. This
consistency model is similar in nature to that of Grapevine
[10].
that carries its list of local services to all other nodes in the
MultiSpace, and also listens for multicast messages from other MultiSpace
nodes. Each MultiSpaceLoader builds an independent version of the registry
from these beacons. The registries are thus soft-state, similar in nature
to the cluster state maintained in [11] and [1]--if an
iSpace node goes down and comes back up, its MultiSpaceLoader simply has to
listen to the multicast channel to rebuild its state. Registries on
different nodes may see temporary periods of inconsistency as services are
pushed into the MultiSpace or moved across nodes in the MultiSpace, but in
steady state, all nodes asymptotically approach consistency. This
consistency model is similar in nature to that of Grapevine
[10].
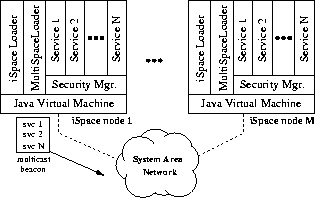
Figure 3: The MultiSpace implementation: MultiSpace services are
instantiated on top of a sandbox (the Security Manager), and run inside the
context of a Java virtual machine (JVM).
The multicast beacons also carry RMI stubs for each local service
component, which implies that any service instance running on any node in
the MultiSpace can identify and contact any other service in the
MultiSpace. It also means that the MultiSpaceLoader on every node has
enough information to construct Redirector Stubs for all of the services in
the MultiSpace, and advertise those Redirector Stubs to off-cluster clients
through a ``service discovery service''[9]. Each RMI stub embedded in a multicast beacon is (based on
our observations) roughly 500 bytes in average length; there is therefore
an important tradeoff between the beacon frequency (and therefore freshness
of information in the MultiSpaceLoaders) and the number of services whose
stubs are being beaconed that will ultimately affect the scalability of the
MultiSpace.
Service instances can elect to receive multicast beacons from other MultiSpace nodes; a service can use this mechanism to become aware of its peers running elsewhere in the cluster. If a service overrides the standard beacon class, it can augment its beacons with additional information, such as the load that it is currently experiencing. Services that want to call out to other services could thus make coarse grained load balancing decisions without requiring a centralized load manager.
Included with the MultiSpace implementation are two services that enrich the functionality available to other MultiSpace services: the distributed hash table, and the uptime monitoring service.
Distributed hash table: as mentioned in section 2.3, due to the Redirector Stub mechanism MultiSpace service instances must maintain self-consistency across the nodes of the cluster. To make this task simpler, we have provided service authors with a distributed, replicated, fault-tolerant hash table that is implemented in C for the sake of efficiency. The hash table is designed to present a consistent view of data across all nodes in the cluster, and as such, services may use it to rendezvous in a style similar to Linda [2] or IBM's T-Spaces [33]. The current implementation is moderately fast (it can handle more than 1000 insertions per second of 500 byte entries on a 4 node 100Mb/s MultiSpace cluster), is fault tolerant, and transparently mask multiple node failures. However, it does not yet provide all of the consistency guarantees that some services would ideally prefer, such as on-line recovery of crashed state or transactions across multiple operations. The currently implementation is, however, suitable for many Internet-style services for which this level of consistency is not essential.
Uptime monitoring service: Even with the service beaconing mechanism, it is difficult to detect the failure of individual nodes in the cluster. This is partly because of the lack of a clear failure model in Java: a Java service is just a collection of objects, not necessarily even possessing a thread of execution. A service failure may just imply that a set of objects has entered a mutually inconsistent state. The absence of beacons doesn't necessarily mean that a service instance failure has occurred; the beacons may be lost due to congestion in the internal network, or the beacons may not have been generated because the service instance is overloaded and is busy processing other tasks.
For this reason, we have provided an uptime monitoring abstraction to service authors. If a service running in the MultiSpace implements a well-known Java interface, the infrastructure automatically detects this and begins periodically calling the doProbe() method in that interface. By implementing this method, service authors promise to perform an application-level task that demonstrates that the service is accepting and successfully processing requests. By using this application-level uptime check, the infrastructure can explicitly detect when a service instance has failed. Currently, we only log this failure in order to generate uptime statistics, and we rely on the Redirector Stub failover mechanisms to mask these failures.