
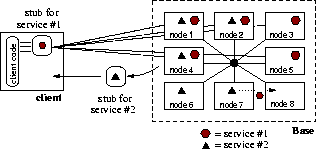
Figure 1: Architecture of a Base: a Base is comprised of a cluster of
workstations connected by a high-speed network. Each node houses an
execution environment into which code can be pushed. Services have many
instances within the cluster, but clients are shielded from this by a
service ``stub'' through which they interact with the cluster.
In this section we present three design principles that guided our service architecture development (shown at a high level in figure 1):
We now discuss each of these principles in turn.
The high availability and scalability ``utility'' requirements that Internet services require are difficult to deliver; our first principle is an attempt to simplify the problem of meeting them by carefully choosing the environment in which we tackle these issues. As in [11], we argue that clusters of workstations provide the best platform on which to build Internet services. Clusters allow incremental scalability through the addition of extra nodes, high availability through replication and failover, and cost-performance by using commodity building blocks as the basis of the computing environment.
Clusters are the backbone of a Base. Physically, a Base must include everything necessary to keep a mission-critical cluster running: system administrators, a physically secure machine room, redundant internal networks and external network feeds, UPS systems, and so on. Logically, a cluster-wide software layer provides data consistency, availability, and fault tolerance mechanisms.
The power of locating services inside a Base arises from the assumptions that service authors can now make when designing their services. Communication is fast and local, and network partitions are exceptionally rare. Individual nodes can be forced to be as homogeneous as necessary, and if a node dies, there will always be an identical replacement available. Storage is local, cheap, plentiful, and well-guarded. Finally, everything is under a single domain, simplifying administration.
Nothing outside of the Base should try to duplicate the fault-tolerance or data consistency guarantees of the Base. For example, e-mail clients should not attempt to keep local copies of mail messages except in the capacity of a cache; all messages are permanently kept by an e-mail service in the Base. Because services promise to be highly available, a user can rely on being able to access her email through it while she is network connected.
Internet services are generally built from a complex assortment of resources, including heterogeneous single-CPU and multiprocessor systems, disk arrays, and networks. In many cases these services are constructed by rigidly placing functionality on particular systems and statically partitioning resources and state. This approach represents the view that a service's design and implementation are ``sanctified'' and must be carefully planned and laid out across the available hardware. In such a regime, there is little tolerance for failures which disrupt the balance and structure of the service architecture.
To alleviate the problems associated with this approach, the Base
architecture employs the principle of receptive execution
environments--systems which can be dynamically configured to host a
component of the service software. A collection of receptive execution
environments can be constructed either from a set of homogeneous
workstations or more diverse resources as required by the service. The
distinguishing feature of a receptive execution environment, however, is
that the service is ``grown'' on top of a fertile platform; functionality
is pushed into each node as appropriate for the application. Each
node in the Base can be remotely and dynamically configured by uploading
service code components as needed, allowing us to delay the decision about
the details of a particular node's specialization as far as possible into
the service construction and maintenance lifecycle. As we will see in section 3, our approach has been to
make a single assumption of homogeneity across systems in a
Base: a Java Virtual Machine is available on each node. In doing so, we
raise the bar of service construction by providing a
common instruction set across all nodes, unified views on threading models,
underlying system APIs (such as socket and filesystem access), as well as
the usual strong typing and safety features afforded by the Java
environment. Because of these provisions, any service component can be
pushed into any node in our Base and be expected to execute, subject to
local resource considerations (such as whether a particular node has access
to a disk array or a CD drive). Assuming that every node is capable of
receiving Java bytecodes, however, means that techniques generally applied
to mobile code systems [21, 13, 28, 32, 18] can be employed internally to the Base: the
administrator can deploy service components by uploading Java classes into
nodes as needed, and the service can push itself towards resources
redistributing code amongst the participating nodes. Furthermore, because
in this environment we are restricting our use of code mobility to
deploying local code within the scope of a single, trusted administrative
domain, some of the security difficulties of mobile code are reduced.
As we will see in section 3, our approach has been to
make a single assumption of homogeneity across systems in a
Base: a Java Virtual Machine is available on each node. In doing so, we
raise the bar of service construction by providing a
common instruction set across all nodes, unified views on threading models,
underlying system APIs (such as socket and filesystem access), as well as
the usual strong typing and safety features afforded by the Java
environment. Because of these provisions, any service component can be
pushed into any node in our Base and be expected to execute, subject to
local resource considerations (such as whether a particular node has access
to a disk array or a CD drive). Assuming that every node is capable of
receiving Java bytecodes, however, means that techniques generally applied
to mobile code systems [21, 13, 28, 32, 18] can be employed internally to the Base: the
administrator can deploy service components by uploading Java classes into
nodes as needed, and the service can push itself towards resources
redistributing code amongst the participating nodes. Furthermore, because
in this environment we are restricting our use of code mobility to
deploying local code within the scope of a single, trusted administrative
domain, some of the security difficulties of mobile code are reduced.
One challenge for clustered servers is to present a single service interface to the outside world, and to mask load-balancing and failover mechanisms in the cluster. The naive solution is to have a single front-end machine that clients first contact; the front-end then dispatches these incoming requests to one of several back-end machines. Failures can be hidden through the selection of another back-end machine, and load-balancing can be directly controlled by the front-end's dispatch algorithm. Unfortunately, the front-end can become a performance bottleneck and a single point of failure [11, 8]. One solution to these problems is to use multiple front-end machines, but this introduces new problems of naming (how clients determine which front-end to use) and consistency (whether the front-ends mutually agree on the back-end state of the cluster). The naming problem can be addressed in a number of ways, such as round-robin DNS [6], static assignment of front-ends to clients, or ``lightweight'' redirection in the style of scalable Web servers [17]. The consistency problem can be solved through one of many distributed systems techniques [4] or ignored if consistent state is unimportant to the front-end nodes.
The Base architecture takes another approach to cluster access indirection: the use of dynamically-generated Redirector Stubs. A stub is client-side code which provides access to a service; a common example is the stub code generated for CORBA/IIOP [25] and Java Remote Method Invocation (RMI) [23] systems. The stub code runs on the client and converts client requests for service functionality (such as Java method calls) into network messages, marshalling request parameters and unmarshalling results. In the case of Java RMI, clients download stubs on-demand from the server.
Base services employ a similar technique to RPC stub generation except that the Redirector Stub for a service is dynamically generated at run-time and contains embedded logic to select from a set of nodes within the cluster (figure 2). Load balancing is implemented within this ``Redirector Stub'', and failover is accomplished by reissuing failed or timed-out service calls to an alternative back-end machine. The redirection logic and information about the state of the Base is built up by the Base and advertised to clients periodically; clients obtain the Redirector Stubs from a registry. This methodology has a number of significant implications about the nature of services, namely that they must be idempotent and maintain self-consistency across a service's instances on different nodes in the Base. In section 3.3.1, we will discuss an implementation of a cluster-wide distributed data structure that simplifies the task of satisfying these implications.
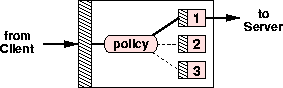
Figure 2: A ``Redirector Stub'': embedded inside a Redirectory Stub are
several RPC stubs with the same interface, each of which communicates with
a different service instance inside a Base.
Client applications can be coded without knowledge of the Redirector Stub logic; by moving failover and load-balancing functionality to the client, the use of front-end machines can be avoided altogether. This is similar to the notion of smart clients [34], but with the intelligence being injected into the client at run-time instead of being compiled in.