| Contract | Disk | RAID | MEMS | SSD |
| 1. Sequential accesses are much better than random accesses | T | T | T | F (flash memory, no mechanical parts) |
| 2. Distant LBNs lead to longer seek times | T * | F | T | F (log-structured writes) |
| 3. LBN spaces can be interchanged | F | F | T | F (integration of SLC and MLC memory) |
| 4. Data written is equal to data issued (no write amplification) | T | F | T | F (ganging, striping, larger logical pages) |
| 5. Media does not wear down | T | T | T | F (semiconductor properties) |
| 6. Storage devices are passive with little background activity | T * | F | T | F (cleaning and wear-leveling) |
| Read | Write | |||||
| Device | Seq | Rand | Ratio | Seq | Rand | Ratio |
| HDD | 86.2 | 0.6 | 143.7 | 86.8 | 1.3 | 66.8 |
| S1slc | 205.6 | 18.7 | 11.0 | 169.4 | 53.8 | 3.1 |
| S2slc | 40.3 | 4.4 | 9.2 | 32.8 | 0.1 | 328.0 |
| S3slc | 72.5 | 29.9 | 2.4 | 75.8 | 0.5 | 151.6 |
| S4slc_sim | 30.5 | 29.1 | 1.1 | 24.4 | 18.4 | 1.3 |
| S5mlc | 68.3 | 21.3 | 3.2 | 22.5 | 15.3 | 1.5 |
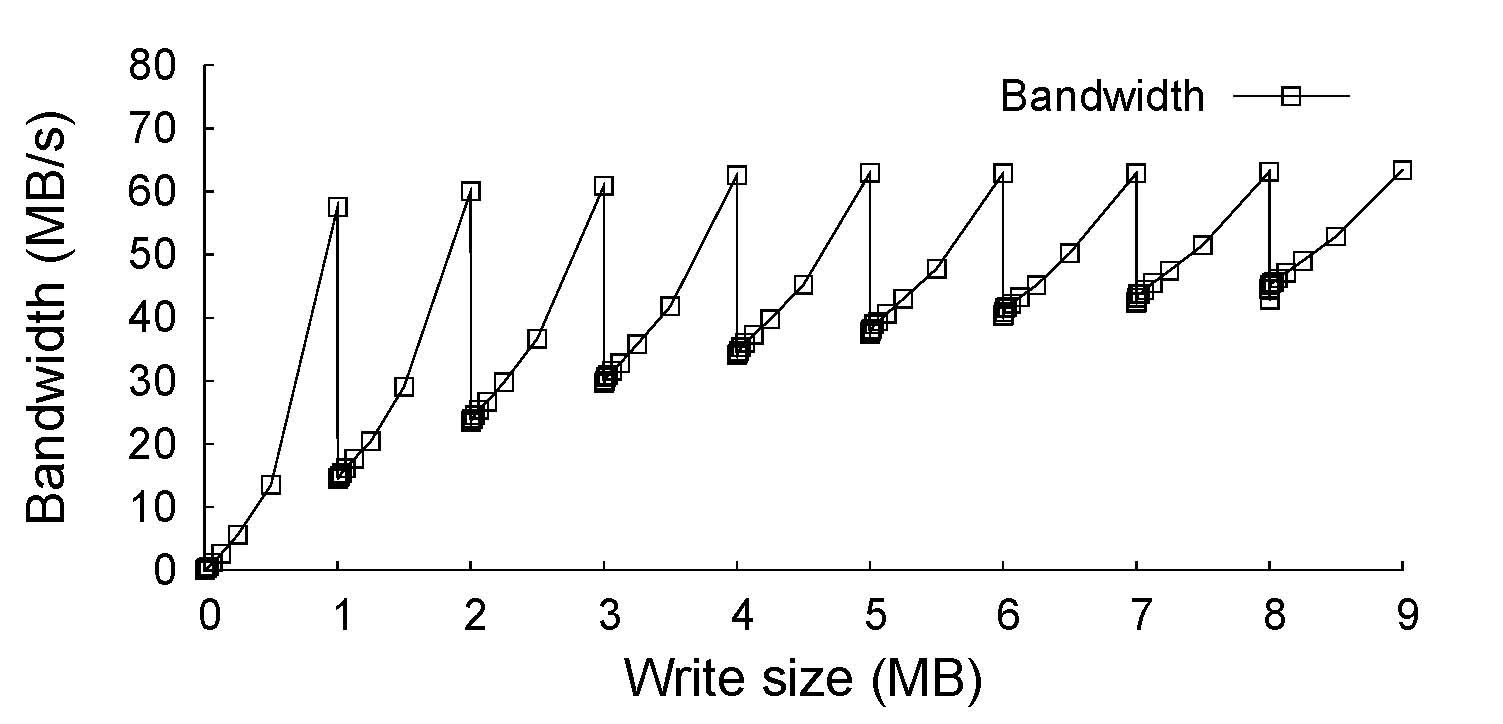
| Probability of sequential access | 0 | 0.2 | 0.4 | 0.6 | 0.8 |
| Unaligned | 10.6 | 10.6 | 10.5 | 10.2 | 10.5 |
| Aligned | 10.6 | 10.4 | 8.9 | 7.6 | 5.6 |
| Postmark | TPCC | Exchange | IOzone | |
| Improvement (%) | 1.15 | 3.08 | 4.89 | 36.54 |
| Transactions | 5000 | 6000 | 7000 | 8000 |
| Relative pages moved | 0.31 | 0.25 | 0.35 | 0.50 |
| Relative cleaning time | 0.69 | 0.60 | 0.63 | 0.69 |
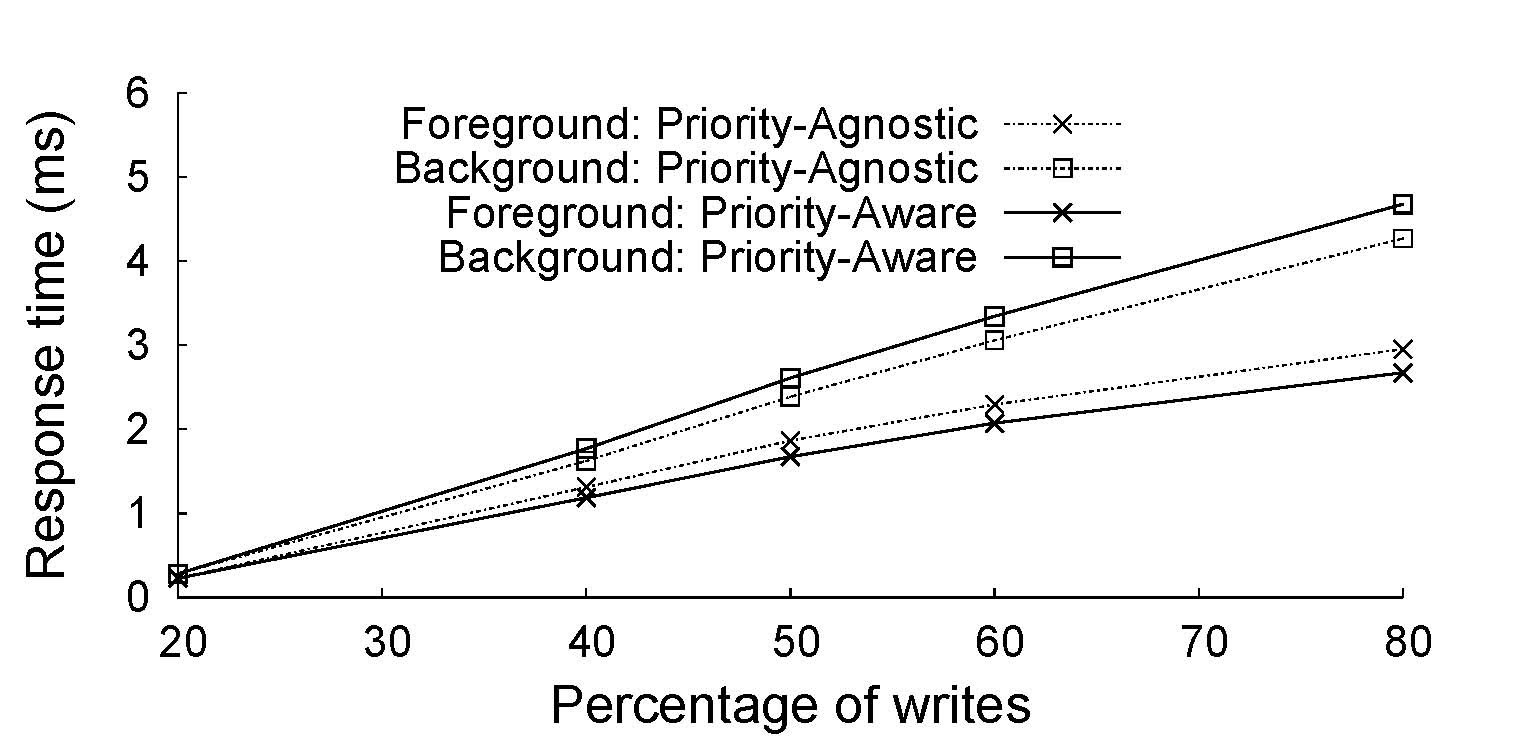
| Writes (%) | 20 | 40 | 50 | 60 | 80 |
| Improvement (%) | 0 | 9.56 | 10.27 | 9.61 | 9.47 |