
| ||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Security '04 Paper
[Security '04 Technical Program]
A Virtual Honeypot Framework
Niels Provos Date:
A honeypot is a closely monitored network decoy serving several
purposes: it can distract adversaries from more valuable machines on a
network, provide early warning about new attack and exploitation
trends, or allow in-depth examination of adversaries during and after
exploitation of a honeypot. Deploying a physical honeypot is often
time intensive and expensive as different operating systems require
specialized hardware and every honeypot requires its own physical
system. This paper presents Honeyd, a framework for virtual
honeypots that simulates virtual computer systems at the network
level. The simulated computer systems appear to run on unallocated
network addresses. To deceive network fingerprinting tools, Honeyd
simulates the networking stack of different operating systems and can
provide arbitrary routing topologies and services for an arbitrary
number of virtual systems. This paper discusses Honeyd's design and
shows how the Honeyd framework helps in many areas of system security,
e.g. detecting and disabling worms, distracting adversaries, or
preventing the spread of spam email.
|
![\begin{figure}
\centerline{
\includegraphics [width=8cm]{honeyd-overview}
}
{\sf}\end{figure}](img1.png) |
Honeyd must be able to handle virtual honeypots on multiple IP addresses simultaneously, in order to populate the network with numerous virtual honeypots simulating different operating systems and services. To increase the realism of our simulation, the framework must be able to simulate arbitrary network topologies. To simulate address spaces that are topologically dispersed and for load sharing, the framework also needs to support network tunneling.
Figure ![[*]](cross_ref_motif.png) shows a conceptual overview of the
framework's operation. A central machine intercepts network traffic
sent to the IP addresses of configured honeypots and simulates their
responses. Before we describe Honeyd's architecture, we explain how
network packets for virtual honeypots reach the Honeyd host.
shows a conceptual overview of the
framework's operation. A central machine intercepts network traffic
sent to the IP addresses of configured honeypots and simulates their
responses. Before we describe Honeyd's architecture, we explain how
network packets for virtual honeypots reach the Honeyd host.
Let A be the IP address of our router and B the IP address of the
Honeyd host. In the simplest case, the IP addresses of virtual
honeypots lie within our local network. We denote them
![]() . When an adversary sends a packet from the Internet
to honeypot Vi, router A receives and attempts to
forward the packet. The router queries its routing table to find the
forwarding address for Vi. There are three possible outcomes: the
router drops the packet because there is no route to Vi, router A
forwards the packet to another router, or Vi lies in local network
range of the router and thus is directly reachable by A.
. When an adversary sends a packet from the Internet
to honeypot Vi, router A receives and attempts to
forward the packet. The router queries its routing table to find the
forwarding address for Vi. There are three possible outcomes: the
router drops the packet because there is no route to Vi, router A
forwards the packet to another router, or Vi lies in local network
range of the router and thus is directly reachable by A.
To direct traffic for Vi to B, we can use the following two
methods. The easiest way is to configure routing entries for Vi
with ![]() that point to B. In that case, the router
forwards packets for our virtual honeypots directly to the Honeyd
host. On the other hand, if no special route has been configured, the
router ARPs to determine the MAC address of the virtual honeypot. As
there is no corresponding physical machine, the ARP requests go
unanswered and the router drops the packet after a few retries. We
configure the Honeyd host to reply to ARP requests for Vi with its
own MAC addresses. This is called Proxy ARP and allows the router to
send packets for Vi to B's MAC address.
that point to B. In that case, the router
forwards packets for our virtual honeypots directly to the Honeyd
host. On the other hand, if no special route has been configured, the
router ARPs to determine the MAC address of the virtual honeypot. As
there is no corresponding physical machine, the ARP requests go
unanswered and the router drops the packet after a few retries. We
configure the Honeyd host to reply to ARP requests for Vi with its
own MAC addresses. This is called Proxy ARP and allows the router to
send packets for Vi to B's MAC address.
In more complex environments, it is possible to tunnel network address
space to a Honeyd host. We use the generic routing
encapsulation (GRE) [11,12] tunneling protocol
described in detail in Section .
![\begin{figure}
\centerline{
\includegraphics [width=8cm]{arch}
}
{\sf}\end{figure}](img4.png) |
.
Incoming packets are processed by the central packet dispatcher. It first checks the length of an IP packet and verifies the packet's checksum. The framework is aware of the three major Internet protocols: ICMP, TCP and UDP. Packets for other protocols are logged and silently discarded.
Before it can process a packet, the dispatcher must query the configuration database to find a honeypot configuration that corresponds to the destination IP address. If no specific configuration exists, a default template is used. Given a configuration, the packet and corresponding configuration is handed to the protocol specific handler.
The ICMP protocol handler supports most ICMP requests. By default,
all honeypot configurations respond to echo requests and
process destination unreachable messages. The handling of
other requests depends on the configured personalities as described in
Section .
For TCP and UDP, the framework can establish connections to arbitrary services. Services are external applications that receive data on stdin and send their output to stdout. The behavior of a service depends entirely on the external application. When a connection request is received, the framework checks if the packet is part of an established connection. In that case, any new data is sent to the already started service application. If the packet contains a connection request, a new process is created to run the appropriate service. Instead of creating a new process for each connection, the framework supports subsystems and internal services. A subsystem is an application that runs in the name space of the virtual honeypot. The subsystem specific application is started when the corresponding virtual honeypot is instantiated. A subsystem can bind to ports, accept connections, and initiate network traffic. While a subsystem runs as an external process, an internal service is a Python script that executes within Honeyd. Internal services require even less resources than subsystems but can only accept connections and not initiate them.
Honeyd contains a simplified TCP state machine. The three-way handshake for connection establishment and connection teardown via FIN or RST are fully supported, but receiver and congestion window management is not fully implemented.
UDP datagrams are passed directly to the application. When the framework receives a UDP packet for a closed port, it sends an ICMP port unreachable message unless this is forbidden by the configured personality. In sending ICMP port unreachable messages, the framework allows network mapping tools like traceroute to discover the simulated network topology.
In addition to establishing a connection to a local service, the framework also supports redirection of connections. The redirection may be static or it can depend on the connection quadruple (source address, source port, destination address and destination port). Redirection lets us forward a connection request for a service on a virtual honeypot to a service running on a real server. For example, we can redirect DNS requests to a proper name server. Or we can reflect connections back to an adversary, e.g. just for fun we might redirect an SSH connection back to the originating host and cause the adversary to attack her own SSH server. Evil laugh.
Before a packet is sent to the network, it is processed by the personality engine. The personality engine adjusts the packet's content so that it appears to originate from the network stack of the configured operating system.
 |
The framework uses Nmap's fingerprint database as its reference for a personality's TCP and UCP behavior; Xprobe's fingerprint database is used as reference for a personality's ICMP behavior.
Next, we explain how we use the information provided by Nmap's fingerprints to change the characteristics of a honeypot's network stack.
Each Nmap fingerprint has a format similar to the example shown in
Figure . We use the string after the
Fingerprint token as the personality name. The lines after the name
describe the results for nine different tests that Nmap performs to
determine the operating system of a remote host. The first test is
the most comprehensive. It determines how the network stack of the
remote operating system creates the initial sequence number
(ISN) for TCP SYN segments. Nmap indicates the difficulty of
predicting ISNs in the Class field. Predictable ISNs post a
security problem because they allow an adversary to spoof
connections [2]. The gcd and SI
field provide more detailed information about the ISN distribution.
The first test also determines how IP identification numbers and TCP
timestamps are generated.
The next seven tests determine the stack's behavior for packets that arrive on open and closed TCP ports. The last test analyzes the ICMP response packet to a closed UDP port.
The framework keeps state for each honeypot. The state includes information about ISN generation, the boot time of the honeypot and the current IP packet identification number. Keeping state is necessary so that we can generate subsequent ISNs that follow the distribution specified by the fingerprint.
![\begin{figure}
\centerline{
\includegraphics [width=8cm]{tcp}
}
{\sf}\end{figure}](img6.png) |
Nmap's fingerprinting is mostly concerned with an operating system's TCP implementation. TCP is a stateful, connection-oriented protocol that provides error recovery and congestion control [20]. TCP also supports additional options, not all of which implemented by all systems. The size of the advertised receiver windows varies between implementations and is used by Nmap as part of the fingerprint.
When the framework sends a packet for a newly established TCP connection, it uses the Nmap fingerprint to see the initial window size. After a connection has been established, the framework adjusts the window size according to the amount of buffered data.
If TCP options present in the fingerprint have been negotiated during connection establishment, then Honeyd inserts them into the response packet. The framework uses the fingerprint to determine the frequency with which TCP timestamps are updated. For most operating systems, the update frequency is 2 Hz.
Generating the correct distribution of initial sequence numbers is tricky. Nmap obtains six ISN samples and analyzes their consecutive differences. Nmap recognizes several ISN generation types: constant differences, differences that are multiples of a constant, completely random differences, time dependent and random increments. To differentiate between the latter two cases, Nmap calculates the greatest common divisor (gcd) and standard deviation for the collected differences.
The framework keeps track of the last ISN that was generated by each honeypot and its generation time. For new TCP connection requests, Honeyd uses a formula that approximates the distribution described by the fingerprint's gcd and standard deviation. In this way, the generated ISNs match the generation class that Nmap expects for the particular operating system.
For the IP header, Honeyd adjusts the generation of the identification number. It can either be zero, increment by one, or random.
![\begin{figure}
\centerline{
\includegraphics [width=8cm]{icmp}
}
{\sf}\end{figure}](img7.png) |
For ICMP packets, the personality engine uses the PU test entry
to determine how the quoted IP header should be modified using the
associated Xprobe fingerprint for further information. Some operating
systems modify the incoming packet by changing fields from network to
host order and as a result quote the IP and UDP header incorrectly.
Honeyd introduces these errors if necessary. Figure
shows an example for an ICMP destination unreachable message. The
framework also supports the generation of other ICMP messages, not
described here due to space considerations.
Normally, the virtual routing topology is a tree rooted where packets enter the virtual routing topology. Each interior node of the tree represents a router and each edge a link that contains latency and packet loss characteristics. Terminal nodes of the tree correspond to networks. The framework supports multiple entry points that can exit in parallel. An entry router is chosen by the network space for which it is responsible.
To simulate an asymmetric network topology, we consult the routing
tables when a packet enters the framework and again when it leaves the
framework; see Figure . In this case, the network
topology resembles a directed acyclic graph![[*]](foot_motif.png) .
.
When the framework receives a packet, it finds the correct entry routing tree and traverses it, starting at the root until it finds a node that contains the destination IP address of the packet. Packet loss and latency of all edges on the path are accumulated to determine if the packet is dropped and how long its delivery should be delayed.
The framework also decrements the time to live (TTL) field of the packet for each traversed router. If the TTL reaches zero, the framework sends an ICMP time exceeded message with the source IP address of the router that causes the TTL to reach zero.
 |
For network simulations, it is possible to integrate real systems into the virtual routing topology. When the framework receives a packet for a real system, it traverses the topology until it finds a virtual router that is directly responsible for the network space that the real machine belongs to. The framework sends an ARP request if necessary to discover the hardware address of the system, then encapsulates the packet in an Ethernet frame. Similarly, the framework responds with ARP replies from the corresponding virtual router when the real system sends ARP requests.
We can split the routing topology using GRE to tunnel networks. This
allows us to load balance across several Honeyd installations by
delegating parts of the address space to different Honeyd hosts.
Using GRE tunnels, it is also possible to delegate networks that
belong to separate parts of the address space to a single Honeyd host.
For the reverse route, an outgoing tunnel is selected based both on
the source and the destination IP address. An example of such a
configuration is described in Section .
The set and add commands change the configuration of a
template. The set command assigns a personality from the Nmap
fingerprint file to a template. The personality determines the
behavior of the network stack, as discussed in
Section . The set command also defines the
default behavior for the supported network protocols. The default
behavior is one of the following values: block, reset, or
open. Block means that all packets for the specified protocol
are dropped by default. Reset indicates that all ports are closed by
default. Open means that they are all open by default. The latter
settings make a difference only for UDP and TCP.
We specify the services that are remotely accessible with the add command. In addition to the template name, we need to specify the protocol, port and the command to execute for each service. Instead of specifying a service, Honeyd also recognizes the keyword proxy that allows us to forward network connections to a different host. The framework expands the following four variables for both the service and the proxy statement: $ipsrc, $ipdst, $sport, and $dport. Variable expansion allows a service to adapt its behavior depending on the particular network connection it is handling. It is also possible to redirect network probes back to the host that is doing the probing.
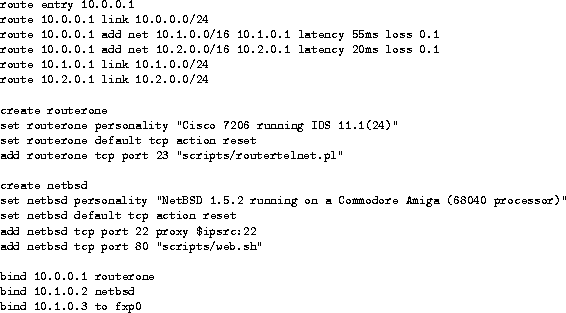
The bind command assigns a template to an IP address. If no
template is assigned to an IP address, we use the default
template. Figure shows an example
configuration that specifies a routing topology and two templates.
The router template mimics the network stack of a Cisco 7206 router
and is accessible only via telnet. The web server template runs two
services: a simple web server and a forwarder for SSH connections. In
this case, the forwarder redirects SSH connections back to the
connection initiator. A real machine is integrated into the virtual
routing topology at IP address 10.1.0.3.
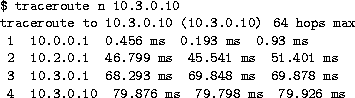
and use traceroute to find the routing
path to a virtual host. We notice that the measured latency is double
the latency that we configured. This is correct because packets have
to traverse each link twice.
 |
Running Nmap 3.00 against IP addresses 10.0.0.1 and 10.1.0.2 results in the correct identification of the configured personalities. Nmap reports that 10.0.0.1 seems to be a Cisco router and that 10.1.0.2 seems to run NetBSD. Xprobe identifies 10.0.0.1 as Cisco router and lists a number of possible operating systems, including NetBSD, for 10.1.0.2.
To fully test if the framework deceives Nmap, we set up a B-class network populated with virtual honeypots for every fingerprint in Nmap's fingerprint file. After removing duplicates, we found 600 distinct fingerprints. The honeypots were configured so that all but one port was closed; the open port ran a web server. We then launched Nmap 3.00 against all configured IP addresses and checked which operating systems Nmap identified. For 555 fingerprints, Nmap uniquely identified the operating system simulated by Honeyd. For 37 fingerprints, Nmap presented a list of possible choices that included the simulated personality. Nmap failed to identify the correct operating system for only eight fingerprints. This might be a problem of Honeyd, or it could be due to a badly formed fingerprint database. For example, the fingerprint for a SMC Wireless Broadband Router is almost identical to the fingerprint for a Linksys Wireless Broadband Router. When evaluating fingerprints, Nmap always prefers the latter over the former.
![\begin{figure}
\centerline{
\includegraphics [width=8cm]{performance/ping-performance}
}
{\sf}\end{figure}](img10.png) |
Currently available fingerprinting tools are usually stateless because they neither open TCP connections nor explore the behavior of the TCP state machine for states other than LISTEN or CLOSE. There are several areas like congestion control and fast recovery that are likely to be different between operating systems and are not checked by fingerprinting tools. An adversary who measures the differences in TCP behavior for different states across operating system would notice that they do not differ in Honeyd and thus be able to detect virtual honeypots.
Another method to detect virtual honeypots is to analyze their performance in relation to other hosts. Sending network traffic to one virtual honeypot might affect the performance of other virtual honeypots but would not affect the performance of a real host. In the following section, we present a performance analysis of Honeyd.
We analyze Honeyd's performance on a 1.1 GHz Pentium III over an idle 100 MBit/s network. To determine the aggregate bandwidth supported by Honeyd, we configure it to route the 10/8 network and measure its response rate to ICMP echo requests sent to IP addresses at different depths within a virtual routing topology. To get a base of comparison, we first send ICMP echo requests to the IP address of the Honeyd host because the operating system responds to these requests directly. We then send ICMP echo requests to virtual IP addresses at different depths of the virtual routing topology.
Figure shows the fraction of returned ICMP echo replies
for different request rates. The upper graph shows the results for
sending 400 byte ICMP echo request packets. We see that Honeyd starts
dropping reply packets at a bandwidth of 30 MBit/s. For packets sent
to Honeyd's entry router, we measure a 10% reply packet loss. For
packets sent to IP addresses deeper in the routing topology, the loss
of reply packets increases to up to 30%. The lower graph shows the
results for sending 800 byte ICMP echo request packets. Due to the
larger packet size, the rate of packets is reduced by half and we see
that for any destination IP address, the packet loss is only up to
10%.
![\begin{figure}
\centerline{
\includegraphics [width=8.5cm]{latency}
}
{\sf}\end{figure}](img11.png) |
To understand how Honeyd's performance depends on the number of
configured honeypots, we use a micro-benchmark that measures how the
processing time per packet changes with an increasing number of
configured templates. The benchmark chooses a random destination
address from the configured templates and sends a TCP SYN segment to a
closed port. We measure how long it takes for Honeyd to process the
packet and generate a TCP RST segment. The measurement is repeated
80,000 times. Figure shows that for one thousand
templates the processing time is about 0.022 ms per packet which is
equivalent to about 45,000 packets per second. For 250,000 templates,
the processing time increases to 0.032 ms or about 31,000 packets
per second.
To evaluate Honeyd's TCP end-to-end performance, we create a simple internal echo service. When a TCP connection has been established, the service outputs a single line of status information and then echos all the input it receives. We measure how many TCP requests Honeyd can support per second by creating TCP connections from 65536 random source IP addresses in 10.1/16 to 65536 random destination addresses in 10.1/16. To decrease the client load, we developed a tool that creates TCP connections without requiring state on the client. A request is successful when the client sees its own data packet echoed by the echo service running under Honeyd. A successful transaction between a random client address Cr and a random virtual honeypot Hr requires the following exchange:
The client does not close the TCP connection via a FIN segment as this would require state. Depending on the load of the Honeyd machine, it is possible that the banner and echoed data payload may arrive in the same segment.
![\begin{figure}
\centerline{
\includegraphics [width=8cm]{performance/tcp-performance}
}
{\sf}\end{figure}](img14.png) |
Figure shows the results from our TCP
performance measurement. We repeated our measurements at least five
times and show the average result including standard deviation. The
upper graph shows the performance when using the default template for
all honeypots compared to the performance when using an individual
template for each honeypot. Performance decreases slightly when each
of the 65K honeypots is configured individually. In both cases,
Honeyd is able to sustain over two thousand TCP transactions per
second. The lower graph shows the performance for contacting
honeypots at different levels of the routing topology. The
performance decreases most noticeably for honeypots that are
three hops away from the sender. We do not have a convincing
explanation for the drop in performance around six hundred
requests per second.
Our measurements show that a 1.1 GHz Pentium III can simulate
thousands of virtual honeypots. However, the performance depends on
the complexity and number of simulated services available for each
honeypot. The setup for studying spammers described in
Section simulates two C-class networks on a
666 MHz Pentium III.
![\begin{figure*}
\centerline{
\includegraphics [width=8cm]{wormnewd1hr}
\includegraphics [width=8cm]{wormnewd025hr}
}
{\sf}\end{figure*}](img15.png) |
To intercept probes from worms, we instrument virtual honeypots on unallocated network addresses. The probability of receiving a probe depends on the number of infected machines i, the worm propagation chance and the number of deployed honeypots h. The worm propagation chance depends on the worm propagation algorithm, the number of vulnerable hosts and the size of the address space. In general, the larger our honeypot deployment the earlier one of the honeypots receives a worm probe.
To detect new worms, we can use the Honeyd framework in two different ways. We may deploy a large number of virtual honeypots as gateways in front of a smaller number of high-interaction honeypots. Honeyd instruments the virtual honeypots. It forwards only TCP connections that have been established and only UDP packets that carry a payload that fail to match a known fingerprint. In such a setting, Honeyd shields the high-interaction honeypots from uninteresting scanning or backscatter activity. A high-interaction honeypot like ReVirt [7] is used to detect compromises or unusual network activity. Using the automated NIDS signature generation proposed by Kreibich et al. [14], we can then block the detected worm or exploit at the network border. The effectiveness of this approach has been analyzed by Moore et al. [17]. To improve it, we can configure Honeyd to replay packets to several high-interaction honeypots that run different operating systems and software versions.
On the other hand, we can use Honeyd's subsystem support to expose regular UNIX applications like OpenSSH to worms. This solution is limiting as we are restricted to detecting worms only for the operating system that is running the framework and most worms target Microsoft Windows, not UNIX.
Moore et al. show that containing worms is not practical on an Internet scale unless a large fraction of the Internet cooperates in the containment effort [17]. However, with the Honeyd framework, it is possible to actively counter worm propagation by immunizing infected hosts that contact our virtual honeypots. Analogous to Moore et al. [17], we can model the effect of immunization on worm propagation by using the classic SIR epidemic model [13]. The model states that the number of newly infected hosts increases linearly with the product of infected hosts, fraction of susceptible hosts and contact rate. The immunization is represented by a decrease in new infections that is linear in the number of infected hosts:
where at time t, i(t) is the fraction of infected hosts, s(t)
the fraction of susceptible hosts and r(t) the fraction of immunized
hosts. The propagation speed of the worm is characterized by the
contact rate ![]() and the immunization rate is represented by
and the immunization rate is represented by ![]() .
.
We simulate worm propagation based on the parameters for a Code-Red
like worm [15,17]. We use 360,000
susceptible machines in a 232 address space and set the initial
worm seed to 150 infected machines. Each worm launches 50 probes per
second and we assume that the immunization of an an infected machine
takes one second after it has contacted a honeypot. The simulation
measures the effectiveness of using active immunization by virtual
honeypots. The honeypots start working after a time delay. The time
delay represents the time that is required to detect the worm and
install the immunization code. We expect that immunization code can
be prepared before a vulnerability is actively exploited.
Figure shows the worm propagation resulting from a
varying number of instrumented honeypots. The graph on the left shows
the results if the honeypots are brought online an hour after the worm
started spreading. The graph on the right shows the results if the
honeypots can be activated within twenty minutes. If we wait for an
hour, all vulnerable machines on the Internet will be infected. Our
chances are better if we start the honeypots after twenty minutes. In
that case, a deployment of about 262,000 honeypots is capable of
stopping the worm from spreading to all susceptible hosts. Ideally,
we detect new worms automatically and immunize infected machines when
a new worm has been detected.
Alternatively, it would be possible to scan the Internet for vulnerable systems and remotely patch them. For ethical reasons, this is probably unfeasible. However, if we can reliably detect an infected machine with our virtual honeypot framework, then active immunization might be an appropriate response. For the Blaster worm, this idea has been realized by Oudot et al. [18].
In general, spammers abuse two Internet services: proxy servers [10] and open mail relays. Open proxies are often used to connect to other proxies or to submit spam email to open mail relays. Spammers can use open proxies to anonymize their identity to prevent tracking the spam back to its origin. An open mail relay accepts email from any sender address to any recipient address. By sending spam email to open mail relays, a spammer causes the mail relay to deliver the spam in his stead.
To understand how spammers operate we use the Honeyd framework to instrument networks with open proxy servers and open mail relays. We make use of Honeyd's GRE tunneling capabilities and tunnel several C-class networks to a central Honeyd host.
We populate our network space with randomly chosen IP addresses and a random selection of services. Some virtual hosts may run an open proxy and others may just run an open mail relay or a combination of both.
When a spammer attempts to send spam email via an open proxy or an open mail relay, the email is automatically redirected to a spam trap. The spam trap then submits the collected spam to a collaborative spam filter.
At this writing, Honeyd has received and processed more than six million spam emails from over 1,500 different IP addresses. A detailed evaluation is the subject of future work.
![\begin{figure}
\centerline{
\includegraphics [width=8cm]{spam}
}
{\sf}\end{figure}](img18.png) |
There are several areas of research in TCP/IP stack fingerprinting, among them: effective methods to classify the remote operating system either by active probing or by passive analysis of network traffic, and defeating TCP/IP stack fingerprinting by normalizing network traffic.
Fyodor's Nmap uses TCP and UDP probes to determine the operating system of a host [9]. Nmap collects the responses of a network stack to different queries and matches them to a signature database to determine the operating systems of the queried host. Nmap's fingerprint database is extensive and we use it as the reference for operating system personalities in Honeyd.
Instead of actively probing a remote host to determine its operating systems, it is possible to identify the remote operating system by passively analyzing its network packets. P0f [29] is one such tool. The TCP/IP flags inspected by P0f are similar to the data collected in Nmap's fingerprint database.
On the other hand, Smart et al. show how to defeat fingerprinting tools by scrubbing network packets so that artifacts identifying the remote operating system are removed [22]. This approach is similar to Honeyd's personality engine as both systems change network packets to influence fingerprinting tools. In contrast to the fingerprint scrubber that removes identifiable information, Honeyd changes network packets to contain artifacts of the configured operating system.
High-interaction virtual honeypots can be constructed using User Mode Linux (UML) or Vmware [27]. One example is ReVirt which can reconstruct the state of the virtual machine for any point in time [7]. This is helpful for forensic analysis after the virtual machine has been compromised. Although high-interaction virtual honeypots can be fully compromised, it is not easy to instrument thousands of high-interaction virtual machines due to their overhead. However, the Honeyd framework allows us to instrument unallocated network space with thousands of virtual honeypots. Furthermore, we may use a combination of Honeyd and virtual machines to get the benefit of both approaches. In this case, Honeyd provides network facades and selectively proxies connections to services to backends provided by high-interaction virtual machines.
We gave an overview of Honeyd's design and architecture and showed how Honeyd's personality engine can modify packets to match the fingerprints of other operating systems and how it is possible to create arbitrary virtual routing topologies.
Our performance measurements showed that a single 1.1 GHz Pentium III can simulate thousands of virtual honeypots with an aggregate bandwidths of over 30 MBit/s and that it can sustain over two thousand TCP transactions per second. Our experimental evaluation showed that Honeyd is effective in creating virtual routing topologies and successfully fools fingerprinting tools.
We showed how the Honeyd framework can be deployed to help in different areas of system security, e.g., worm detection, worm countermeasures, or spam prevention.
Honeyd is freely available as source code and can be downloaded from https://www.citi.umich.edu/u/provos/honeyd/.
This document was generated using the LaTeX2HTML translator Version 97.1 (release) (July 13th, 1997)
Copyright © 1993, 1994, 1995, 1996, 1997, Nikos Drakos, Computer Based Learning Unit, University of Leeds.
The command line arguments were:
latex2html -split 0 -show_section_numbers -local_icons honeyd.tex.
The translation was initiated by Niels Provos on 5/18/2004
|
This paper was originally published in the
Proceedings of the 13th USENIX Security Symposium,
August 9–13, 2004 San Diego, CA Last changed: 23 Nov. 2004 aw |
|