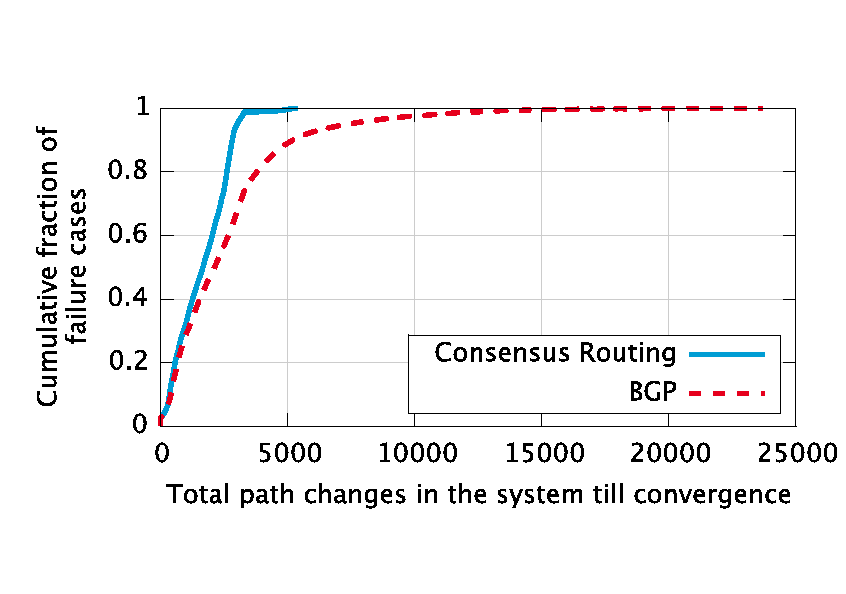
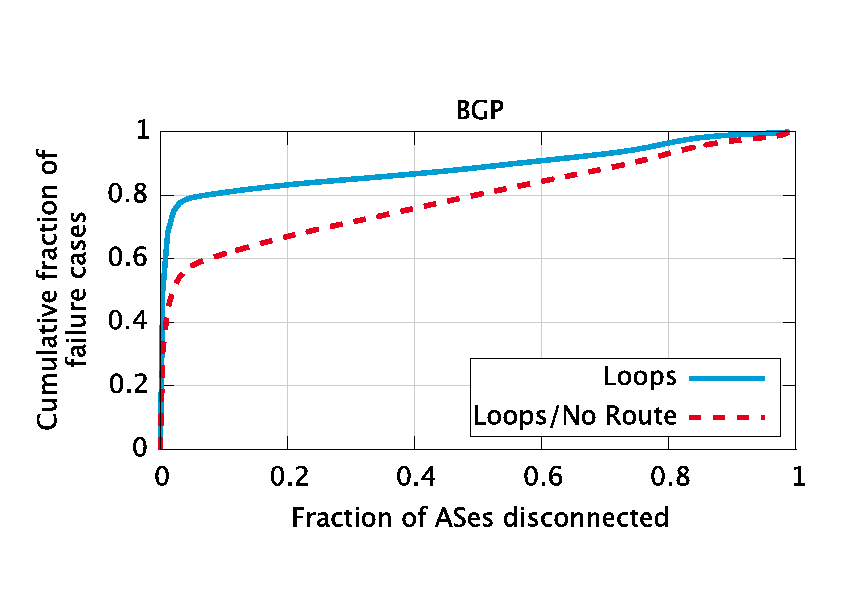
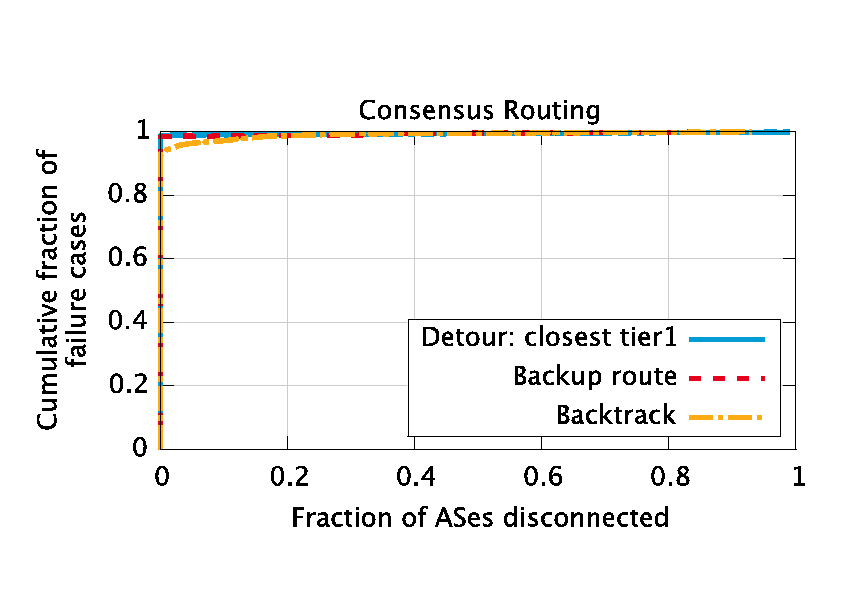
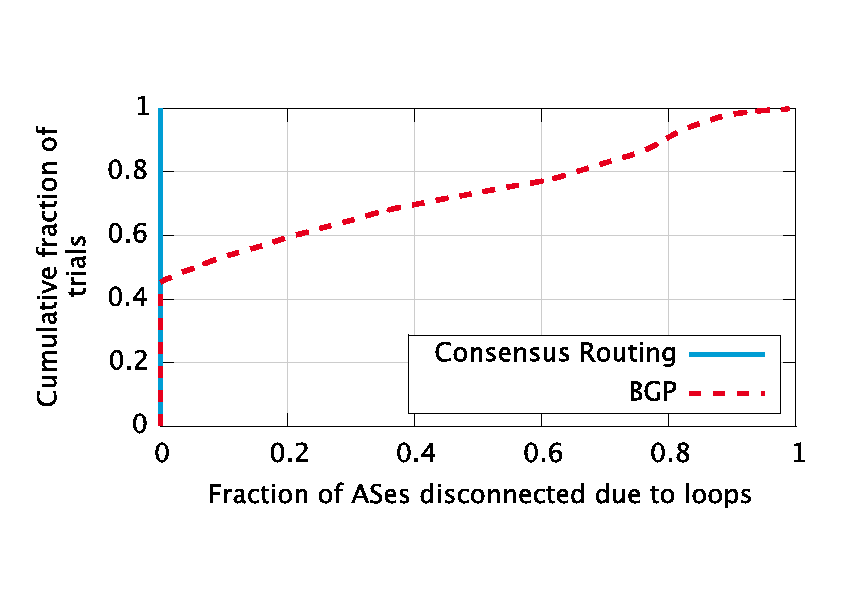
|
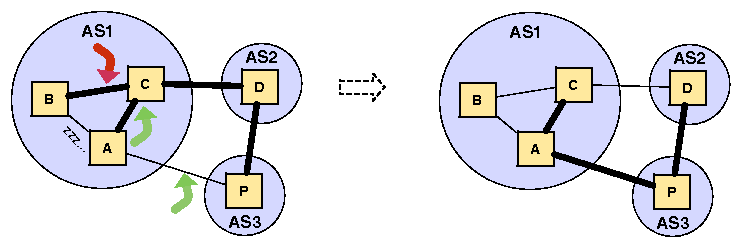
PROCESS_UPDATE(B, r, t):
- Add the update's trigger t to the local set of
incomplete triggers IA.
- Process the update as in BGP. Let old and
new be the best route to the prefix before and
after the update. We define next_hop for a route to be the
first AS in the route.
- Add the received update (t, r) to the
head of the History list. Consider the following cases:
- old.next_hop is not B, and new.next_hop is not B:
do nothing since the best route has not changed.
- old.next_hop is not B, and new.next_hop is B:
propagate new to neighbors with trigger t', where
t' is a newly generated trigger. Add the selected update
(t', new) to the start of History.
- old.next_hop is B: propagate new to neighbors with unchanged trigger t.
Add the selected update (t, new) to the start of History.
- Remove t from IA.
|
|