| Mechanism | Function | Goals | Section |
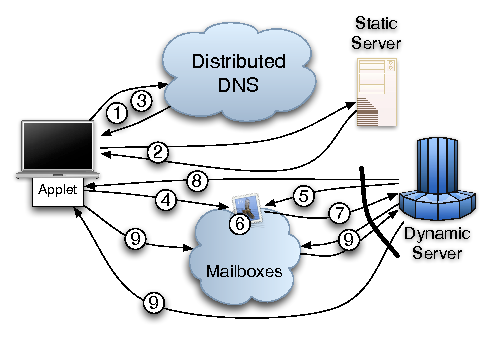
| Mailboxes | lightweight network indirection primitive | Unilateral Deployment, Autoconfig | 3.2 |
| Iterated Hash Sequences | pseudo-random mailbox sequences | Protect Established Connections, Resistance to Compromise | 3.2.1 |
| Scalable Mailbox Sets | provide both efficiency and resilience according to current conditions | Efficiency | 3.2.2 |
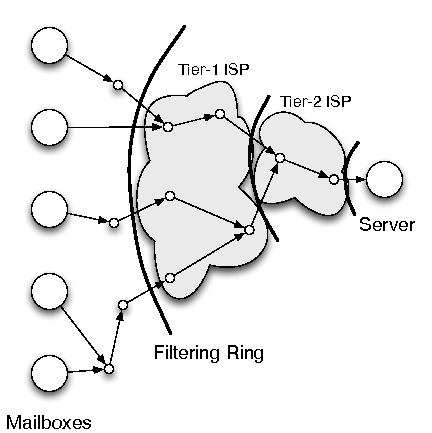
| Filtering Ring | drop unrequested traffic before it can cause damage | Unilateral Deployment, Resistance to Compromise | 3.3 |
| General Purpose Nonces | allow small numbers of unrequested packets through the filtering ring | Eventual Communication | 3.4.1 |
| Cryptographic Puzzles | approximate fair queueing for connection establishment | Eventual Communication | 3.4.3 |
| Authentication Tokens | allow for pre-authentication of trusted flows | Eventual Communication | 3.4.2 |
| Congestion Control | adapt to access link heterogeneity | Autoconfig | 3.5 |
| Symbol | Meaning |
| h | cryptographic hash function |
| x,y | shared secret to generate mailbox sequences |
| C | client, endpoint instigating the connection |
| S | server, endpoint receiving the connection |
| xi | ith element of the sequence based on h and x |
| M | the set of mailboxes {Mi,ﺙ,M|M|} |
| M[xi] | mailbox corresponding to xi (Mxi mod |M|) |
| KY | the public key belonging to Y |
| kY | the private key belonging to Y |
| (z)KY | z encrypted using Y's public key |
| (z)kY | z signed using Y's private key |
| w | the window size for requesting packets |
| putPacket(packet p) |
| places a packet in the local packet buffer |
| getPacket(nonce n) |
| places a request in the local packet buffer; when/if a |
| packet arrives or has arrived it is returned |
| requestConnection(serverKey KS) |
| asks for a challenge to earn access to establish a |
| connection; returns a random nonce |
| submitSolution(string a, integer b) |
| provides a cryptographic puzzle solution to the |
| challenge as a resource proof |
| submitToken(authentication token t) |
| provides proof of pre-authentication |
| issueNonces(signed nonce list N) |
| registers a set of general purpose nonces to be used for |
| initial packet contact with the signing destination |
|
|
|
|
|
|
|