Nikolay Topilski1 , Jeannie Albrecht2 , and Amin Vahdat1
1 University of California, San Diego
2 Williams College
{ntopilsk,vahdat}@cs.ucsd.edu
jeannie@cs.williams.edu
Aside from the difficulties associated with designing applications that can achieve the maximum performance possible in large-scale platforms, another often overlooked problem is configuring and managing the computers that will host the application. Even if the system designer successfully builds a scalable application, deploying, monitoring, and debugging the application running on thousands of high-performance computers introduces many new challenges. This is especially true in computing platforms where there is no common file system running on the computers. In these environments the developer must manually copy and install the necessary software for running the application to the cluster resources and cope with any problems or failures that occur during the file transfer and installation processes. Only after all software has been successfully installed and the computers correctly configured can the execution begin.
After the execution begins, developers need a way to detect and, if possible, recover from failures to ensure that the application runs to completion. When running an application on thousands of resources3 , failures--including both application-level failures and host- or network-level failures--are inevitable. If a failure is detected, the steps required for recovery vary, and largely depend on application-specific semantics. For some applications, recovery may simply be a matter of restarting a failed process on a single computer. For other applications, a single failure may require the entire application running across thousands of cluster resources to be aborted and restarted. For all applications, one fact holds true: a quick and efficient method for failure detection and recovery is needed for successful execution.
Distributed application management systems help ease the burdens associated with deploying and maintaining distributed applications in large-scale computing environments. They are designed to simplify many tasks associated with managing large-scale computations, including software installation, failure detection and recovery, and execution management. The goal is to hide the underlying details related to resource management and create a user-friendly way to manage distributed applications running on thousands of computers. In short, application management infrastructures allow the system designer to focus on fine-tuning the performance of their application, rather than managing and configuring the resources on which the application will run. There is, however, an important caveat regarding the use of an application management system: the management system itself must reliably scale at least as well as the application being managed.
Many existing application management systems scale to one or two hundred computers, but few achieve the scalability required in today's large-scale computing clusters. In addition, several of the existing systems focus on tasks associated with system administration, often making assumptions about the homogeneity of the computing resources that are not always valid in clusters with thousands of computers. Motivated by the limitations of existing approaches, our intent is to design and implement a scalable application management infrastructure that accomplishes the following four goals:
Rather than start from scratch, we chose to use an existing application management system as a basis for our work. In particular, we chose Plush [1,3], a distributed application management framework initially designed for PlanetLab. Plush provides several user-friendly interfaces and supports execution in a variety of environments, thus accomplishing the first two of our four goals. Plush does not provide adequate scalability or fault tolerance, however, based on the size of large-scale computing platforms in use today. The main problem in Plush is the design of the underlying communication infrastructure. The simple design achieves good performance and fault tolerance in small clusters, but is not resilient to failures and does not scale beyond approximately 300 resources. Hence, the majority of our work centers on addressing these limitations of Plush.
To this end, this paper describes the extensions required to improve the scalability and fault tolerance of Plush, and introduces an enhanced system called Plush-M. Plush-M extends Plush to incorporate a scalable and robust overlay tree in place of the existing star-based communication subsystem. We leverage the capabilities of Mace [15], a C++ language extension and library for building distributed systems, to build our overlay tree. Since Mace provides many useful features for designing scalable and robust overlay networks, the integration of Plush and Mace enables us to experiment with many different types of overlays for the communication infrastructure in Plush to ultimately determine the best design.
The remainder of this paper is organized as follows. Section 2 describes an overview of Plush and Mace, and motivates our design of Plush-M. Section 3 discusses some of the problems that had to be addressed during the implementation of Plush-M, and how we overcame these issues. Section 4 provides a preliminary evaluation of the scalability and fault tolerance of Plush-M, while Section 5 discusses related work. Finally, Section 6 describes future directions that we plan to explore and Section 7 concludes.
Plush's architecture primarily consists of two key components: the controller and the clients. The Plush controller, which usually runs directly on the application developer's desktop computer (also called the control node), issues instructions to the clients to help direct the flow of control for the duration of the execution. All computers aside from the controller that are involved in the application become Plush clients (or participants). At the start of an execution, all clients connect directly to the server using standard TCP connections. Plush maintains these connections for the lifetime of the application. The controller then directs the execution of the application by issuing commands to each client which are then executed on behalf of the developer. This simple client-server design results in quick and efficient failure detection and recovery, which are both important aspects of application execution management.
The original design of Plush targeted applications running on PlanetLab. PlanetLab is a volatile, resource-constrained wide-area testbed with no distributed file system. The initial version of Plush provided a minimal set of automated failure recovery mechanisms to help application developers deal with the most common problems experienced on PlanetLab. Over the past few years, Plush was extended to provide generic application management support in a variety of computing environments. In particular, Plush now supports execution on Xen virtual machines [4], emulated ModelNet virtual clients [20], and cluster computers. However, since the size of PlanetLab during the initial development of Plush was approximately 400 computers worldwide, the current design does not scale well beyond a few hundred computers. Thus before Plush will be useful in large-scale clusters, scalability must be revisited.
For applications running in large-scale clusters, Plush was extended to use a simple tree topology for communication rather than a star. The tree topology supports a maximum depth of only two levels, which results in ``bushy" trees where each non-leaf node has a large number of children. The goal was to reduce the number of connections to the control node while also minimizing the number of network hops between the controller and all clients. Unfortunately, while the basic tree topology achieves relatively good performance and scalability, it is not very robust to failures. The failure of intermediate and leaf nodes can lead to unbalanced trees, unaccounted loss of participant nodes, and large tree reconfiguration penalties. Furthermore, imposing a maximum tree depth limitation of two requires intermediate nodes (children of the root) to have sufficient CPU and bandwidth resources available to support large numbers of children (leaf nodes), similar to the resource requirements necessary at the control node.
Thus, in failure prone environments Plush is essentially limited to utilizing the star topology with 300 nodes or less. The only way to use the tree topology effectively is to carefully select reliable and well-connected non-leaf nodes for successful execution of distributed applications. In order to use Plush in large-scale environments, the shortcomings of this tree building mechanism must be addressed.
Mace is fully operational and has been in development for over four years. Many distributed systems have been built using Mace during this time, including several that involve the creation of robust overlay networks for data storage and dissemination [18]. As a result, Mace provides built-in support for the common operations used in overlay network creation and maintenance. One particularly useful protocol provided by Mace is RandTree. RandTree is a protocol that constructs an overlay network based on a random tree. Participants in a RandTree overlay network use the RanSub protocol [17] to distribute fixed-size random subsets of global state to all overlay participants, overcoming scaling limitations and improving routing performance. This allows the RandTree protocol to dynamically adapt to changing network conditions and reconfigure in the face of failures. In short, RandTree creates a random tree with a predefined maximum degree, and automatically handles reconfiguration when any participating node fails, including the root.
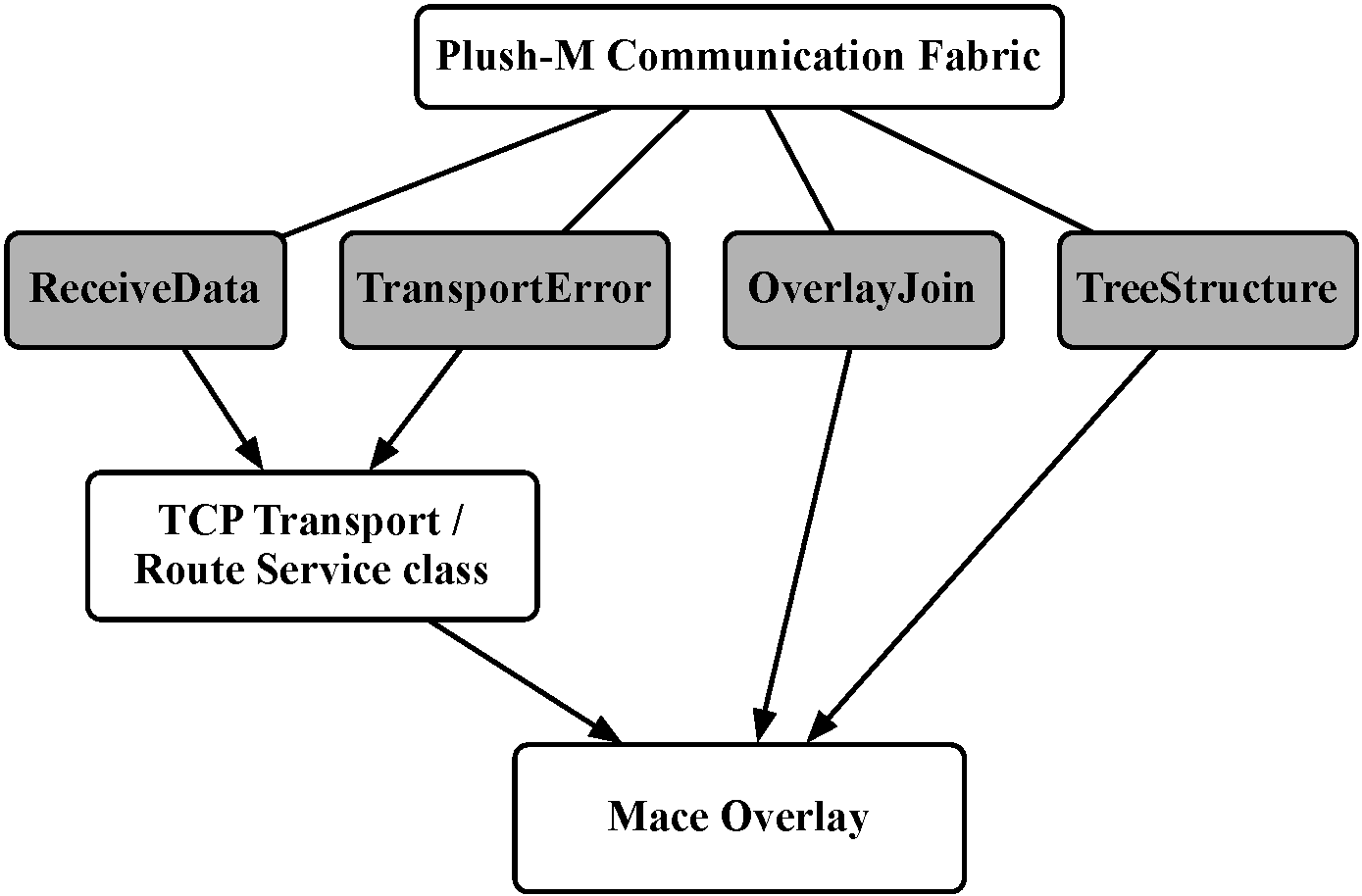
Plush is designed as a monolithic layered application. To utilize an overlay provided by Mace, the entire communication subsystem in Plush must be replaced. However, we still want to maintain the layer integrity within Plush itself. We accomplish these goals by treating the Mace overlay as a black box underneath of Plush, exposing only a simple API for interacting with the overlay network. In the original design of Plush, the controller had to manage the topology of the communication fabric. By inserting a Mace overlay as a black box that is used for communication, the details of the overlay construction and maintenance are hidden from the controller. The Plush controller is mostly unaware of the topology of the hosts that are involved in an execution; the controller knows only the identity of the participating nodes.
This ``black box" design not only allows for the independent upgrade of Plush and Mace, but also gives us the ability to use a variety of overlay services and protocols provided by Mace since most use the same API (shown in Figure 1). We hope to eventually provide developers with the functionality required to select the overlay network protocol that is best suited to handle the communication needs of their application. It is important to realize that since Mace is a general purpose framework for designing distributed applications, its integration into Plush-M may introduce a slight overhead when compared to the simple tree that Plush provides, but we believe that this is a small price to pay for the improved scalability and fault tolerance.
 |
Although the functionality provided by Mace allows developers to build a variety of overlay networks, we chose to integrate the RandTree protocol into Plush-M. There are several reasons why we chose RandTree instead of other tree-building protocols [14,12]. In particular, RandTree provides the following benefits:
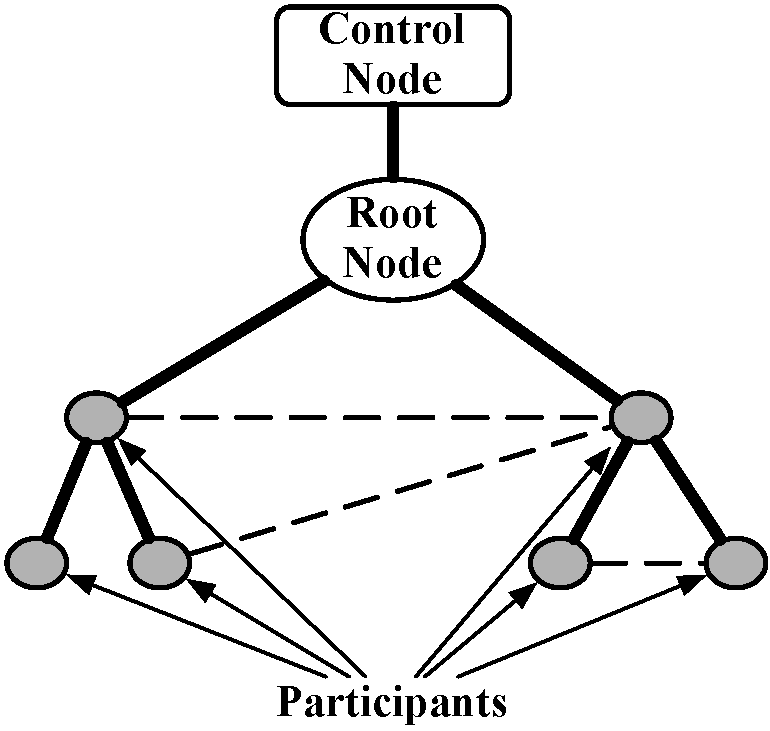 |
The application developer designates the identity of the control node when Plush-M is started. Typically this node is chosen to be the developer's desktop computer. When managing an application using the original design of Plush, the control node establishes a connection to the required number of computers and invites them to participate in the execution of the application. Since the root of the tree is no longer the same computer as the control node, this process is a bit more complex in Plush-M. First, the control node randomly selects a root node and sends it an invitation. Once the control node connects to the newly chosen root, the controller sends all subsequent invitations that it creates on to the root node for forwarding. The process of extending an invitation involves first verifying the liveness of the invited node, and then starting the Plush-M client process on it. For large-scale clusters, the number of outstanding invitations can grow quite large. Thus, in order to reduce the load at the root, the controller limits the number of outstanding invitations to a predetermined maximum value.
Through the lifetime of the application, different participant nodes may join and leave the overlay. The root of the tree can also change in Plush-M, which is something that never occurred in the original design of Plush. When changes to the overlay occur, Plush-M receives upcalls from Mace. If the root of the tree changes, Mace notifies the old root node (via an upcall) that it is no longer the root. The old root must make sure the new root knows the identity of the control node. Thus the old root then sends a SETCTRL message through the overlay to the new root using a multicast ''collect call'' provided by Mace. The collect call ensures that the message is successfully delivered to the new root of the overlay. Upon receiving a SETCTRL message, the newly elected root node must inform the control node of its identity. To accomplish this, the new root sends a SETROOT message to the control node. When the control node receives the SETROOT message, it updates its state with the new root's identity, initiates a connection to the new root, and closes its connection to the former root.
Furthermore, to ensure that the control node stays connected to the acting root node of the overlay, the control node also periodically sends a SETCTRL message to the node that it believes is the root of the tree. The SETCTRL message is then processed in the usual way, using a multicast collect call to traverse the tree up to the root. The root responds with its SETROOT message as usual. If the control node receives a SETROOT message from a node other than the one it thought was the root, it updates its state. This same procedure is used to update the control node when it reconnects after a disconnection.
The control node in Plush-M also plays the role of the execution controller and barrier manager, just like the control node in Plush. The control node ensures that all participants in the overlay receive any required application-specific software or data, and if synchronization barriers are specified, ensures the synchronized execution of the application on all participating nodes. The control node can be disconnected if it is not actively inviting nodes or controlling an execution, such as during a long-running computation. Once the control node reconnects, the root tells it the list of participating nodes in the overlay. Unfortunately, in the current implementation of Plush-M, if the control node fails while there are outstanding invitations, all of its active state is lost. In such cases, the control node must reconnect to the root, destroy the existing overlay, and start over. We are currently exploring ways to restore the state of the control node without requiring a complete restart of the existing execution.
Upon receiving a SETPEER message, each potential participant makes a downcall to Mace asking to join the overlay. Once the node has successfully joined, Mace notifies the parent of the newly joined node via the peerJoinedOverlay upcall in Plush-M. The parent node then informs the new child of any relevant Plush-M specific details. The parent sends SETROOT, INVITE, and SETCTRL messages to the child to inform it of the identity of the controller and root nodes. The child node processes these messages, and responds to the INVITE by sending a JOIN message to the root. The root node processes the JOIN message and adds the newly joined host to the table of participating nodes.
The original design of Plush uses ''connection" objects internally to help keep track of the connection status of participating hosts. Retaining this functionality in Plush-M required the addition of several new Mace upcall methods. Mace calls the notifyParentChanged method on overlay participants every time there is a change in a parent node. This method provides the identity of the new parent. The notifyChildrenChanged method is called on overlay participants whenever a child of the participant changes, and it provides the identities of all actively connected children. Both of these methods help keep Plush-M's internal host and connection structures current, by invalidating old connections and creating new ones as needed. The notifyRootChanged method is called at the new and former root when the root is switched. This causes the former root to send a SETCTRL message, which eventually reaches the new root, and notifies it of the control node's identity.
During an application's execution, some nodes might experience network outages and be reported as DISCONNECTED to the root and control nodes. Depending on the length of the execution, the control node may later try to re-establish connection to the DISCONNECTED node(s). If the reconnection is unsuccessful, the disconnected node is marked as FAILED and is permanently removed from the execution. If the reconnection is successful, the node is reincorporated into the execution. However, if this node continues to disconnect frequently, it is assumed to have an unreliable network connection. After a preset number of disconnects within a specified timeframe, the node is marked as FAILED and is never re-invited to participate.
To address the problems involving conflicting hostnames and ensure the proper operation of Plush-M, we had to reconcile the two addressing systems. The first step in this reconciliation involved adding a MaceKey object as a member of the HostID structure. Since Plush-M extensively relies on HostID objects throughout the duration of the execution, many additional changes were also required. Plush only resolves hostnames into IP addresses when a new connection is initialized to a new participant. Following the same principle in Plush-M, the MaceKey object is initialized, which includes resolving the hostname into an IP address, for all nodes that are invited to participate in the overlay. Initializing a MaceKey object for all available cluster nodes is expensive and wasteful, especially if only a fraction of them are required for execution. Thus MaceKey objects are only initialized for nodes that are involved in an execution. One caveat of this approach is ensuring that HostIDs with initialized MaceKeys are never compared to HostIDs without initialized MaceKeys in the Plush-M implementation. (This can only occur on the control node.) The results of this comparison are not valid, and can lead to incorrect behavior.
To further speed-up the process of overlay dismantling, each node in the overlay starts a two minute timer upon receiving a new DISCONNECT message. When the timer expires the Plush-M client terminates, even if the node still has connected children. This scenario, and some other situations involving uncommon errors, has the potential to leave individual unconnected nodes in an active state running the Plush-M client. These unattended nodes eventually detect that they have no active connections left, causing them to set their two minute expiration timer. If the node does not receive any messages or start any new connections within the expiration time, the Plush-M client will be terminated. Note that the process of overlay dismantling on large topologies and trees of greater maximum depths does take longer due to the increased number of network hops between the root node and the leaf participants. However, with the disconnection timeout mechanisms described above, the control node is safe to terminate without waiting for hosts to report their disconnection.
Although the use of the maintenance script and the automatic client upgrade mechanism works as desired and accomplishes our goals, we find that the upgrade procedure can be quite expensive, especially if the node has a slow or lossy network connection to the software repository. In addition, our experience shows that it is important to provide a way to disable the automatic client upgrade mechanism, since clusters that run a common file system do not need to download updates. We do believe that automating software upgrades is an important aspect of application management, however further investigation and experimentation is required to improve performance. We revisit the performance of the automatic upgrade feature in more detail in Section 4.
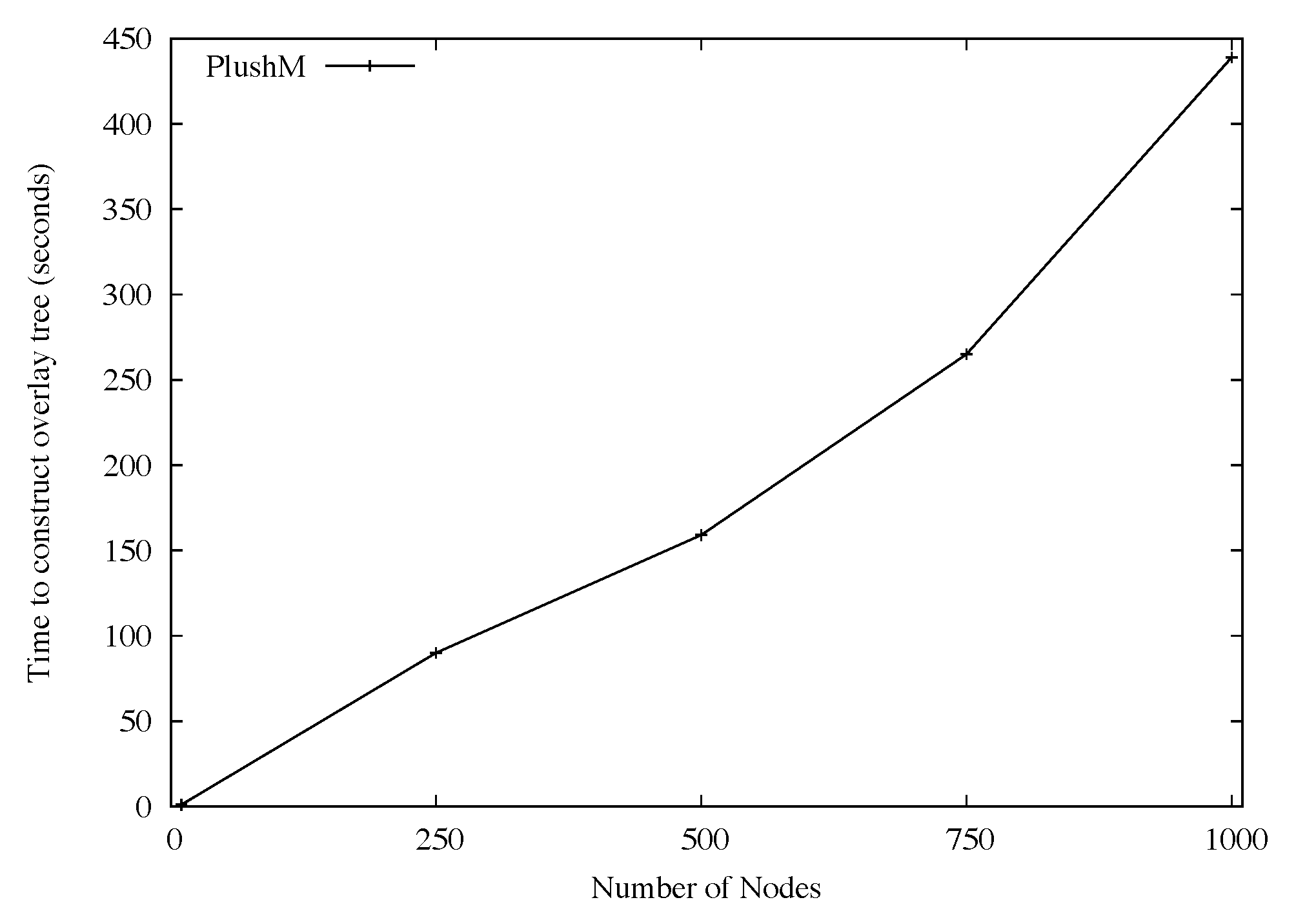
Our first set of experiments tested the scalability of Plush-M for varying numbers of ModelNet emulated clients. The goal was to show that Plush-M scales beyond Plush's limit, which is approximately 300 nodes. To verify Plush-M's scalability, we measured the completion time for the following two operations: 1) the time to construct the overlay tree, and 2) the roundtrip time for a message sent from the control nodes to all participants and then back to the control node. We ran these experiments for 10, 250, 500, 750, and 1000 clients. The results are shown in Figures 3 and 4. In both sets of experiments, we limited the construction of RandTree to allow a maximum of twelve children per node. Therefore, for a perfectly balanced tree, the depth would be approximately 3. In addition, we limited the number of concurrent outstanding invitations to 50. The length of time required for the control node to connect to the root of the overlay is not included in our measurements. Also note that the auto-upgrade mechanism was disabled during these experiments.
The overlay tree construction times measured (and shown in Figure 3) were longer than we expected them to be. We speculate that this is due to the start-up time of the client on the participating nodes. Preliminary testing revealed that increasing the maximum size of the outstanding invitation queue from 50 to 100 invitations did not have a significant effect on the connection time. Similarly, changing the maximum out-degree of the nodes from 12 to 50 also did not have a noticeable effect. Further investigation of the issue indicated that the problem resulted from a limitation in our experimental setup. Since multiple ModelNet clients are emulated on a single machine, there is a limit on how many processes the machine can start simultaneously, and thus some clients experience a delay when starting the Plush-M process. We believe that the construction time would be much faster if more machines were available for experimentation.
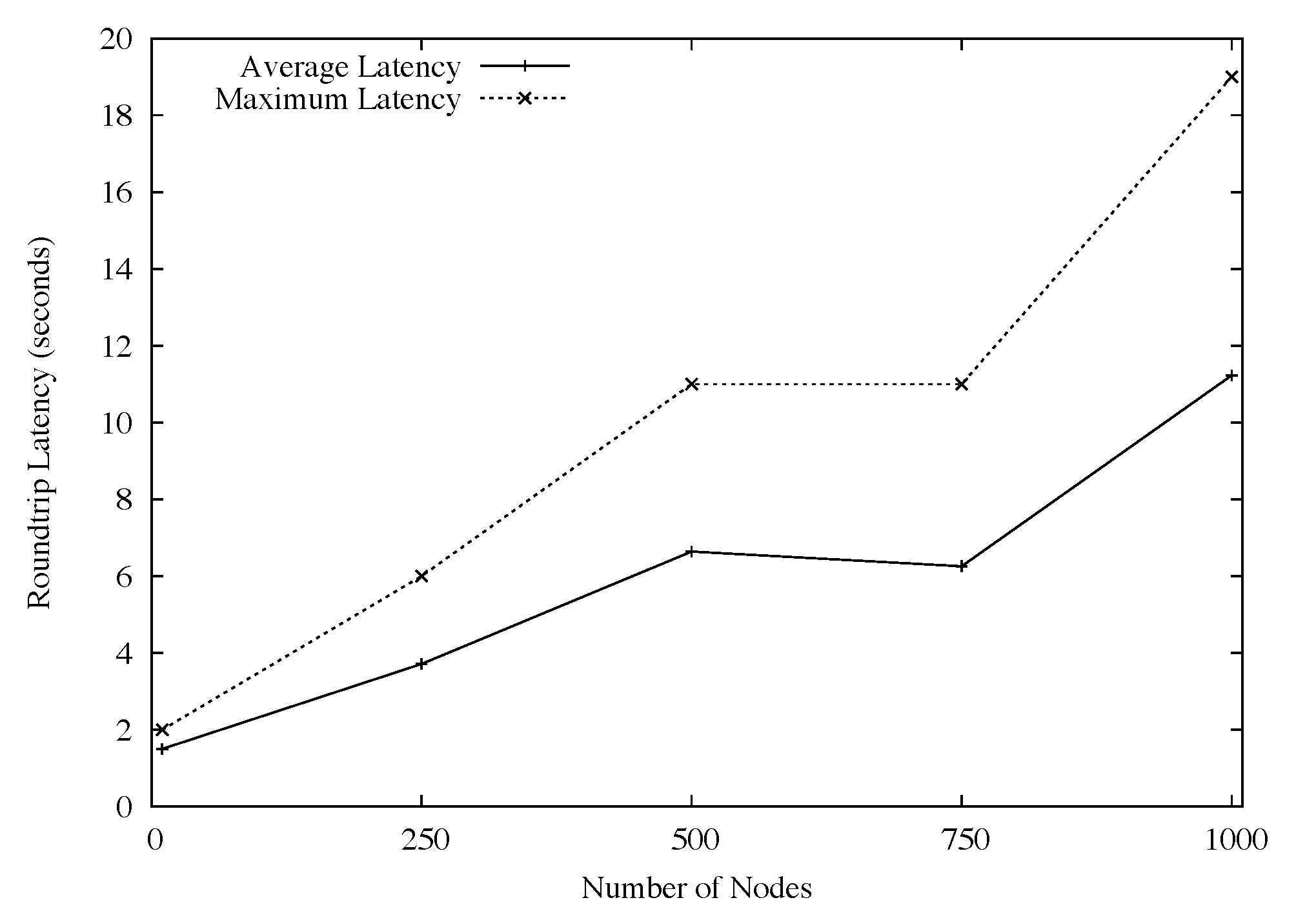
To test the message propagation time in the overlay, we first waited until the tree was completely constructed. Then we broadcast a message from the control node out to all participants and waited for a reply. We measured the time between when we sent the message until each node replied. The broadcast message triggered the execution of the `hostname' command on each remote node. By default, all terminal output is sent back up the tree to the root and then passed to the control node. Figure 4 shows our results. One line indicates the maximum time measured, and the other line indicates the average time across all participants for the reply message to be received by the control node. In summary, we were relatively pleased with the measured times, since we were able to receive replies from most hosts in less than 10 seconds (on average) for our 1000-node topology. Note that in this experiment we were unable to compare to Plush, since Plush does not support execution on more than 300 nodes.
 |
Providing fault tolerance in Plush-M largely depends on being able to detect and recover from failures quickly. Thus, we conducted several experiments to measure the failure recovery time for participants in the overlay when a host-level failure occurred. The goal was to see how long it took for the failed nodes to rejoin the overlay tree after being manually disconnected to simulate failure. By using RandTree instead of the default star in Plush, Plush-M incurs some overhead associated with tree communication and reconfiguration. We wanted to verify that this overhead did not negatively impact Plush-M's ability to detect and recovery from failures quickly.
To test failure recovery and fault tolerance in Plush-M, first we started an application on all nodes that just executed ''sleep" for a sufficiently long period of time. During the execution of the sleep command, one quarter of the participating nodes were failed, which essentially amounted to manually killing the Plush-M client process. We then measured the time required for the failed hosts to detect the failure, restart Plush-M, and rejoin the overlay (possibly causing a tree reconfiguration). We repeated the experiment with varying numbers of nodes to explore how the total number of participants affected the recovery time. Plush-M was again run with RandTree using a maximum of twelve children per node.
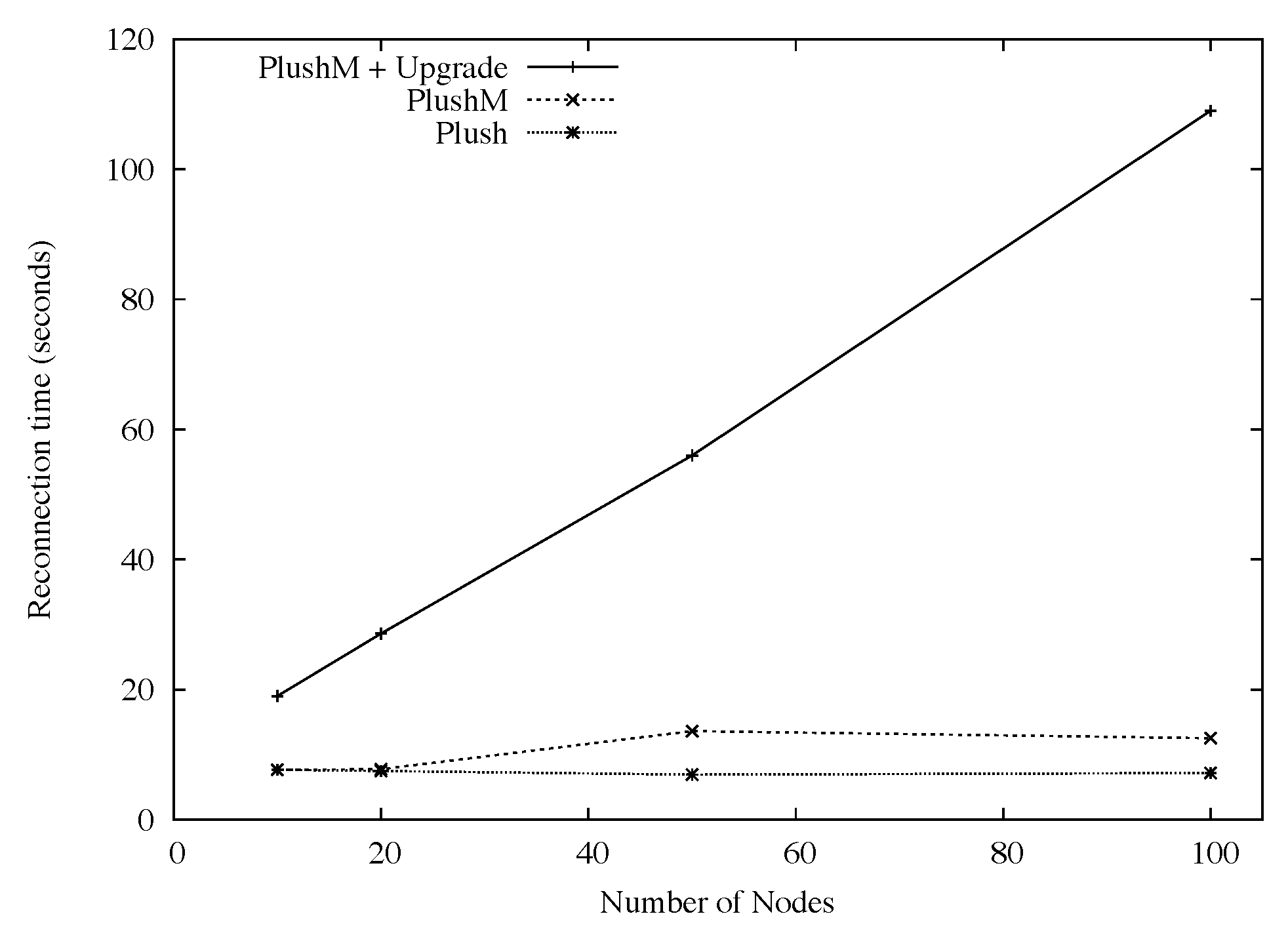 |
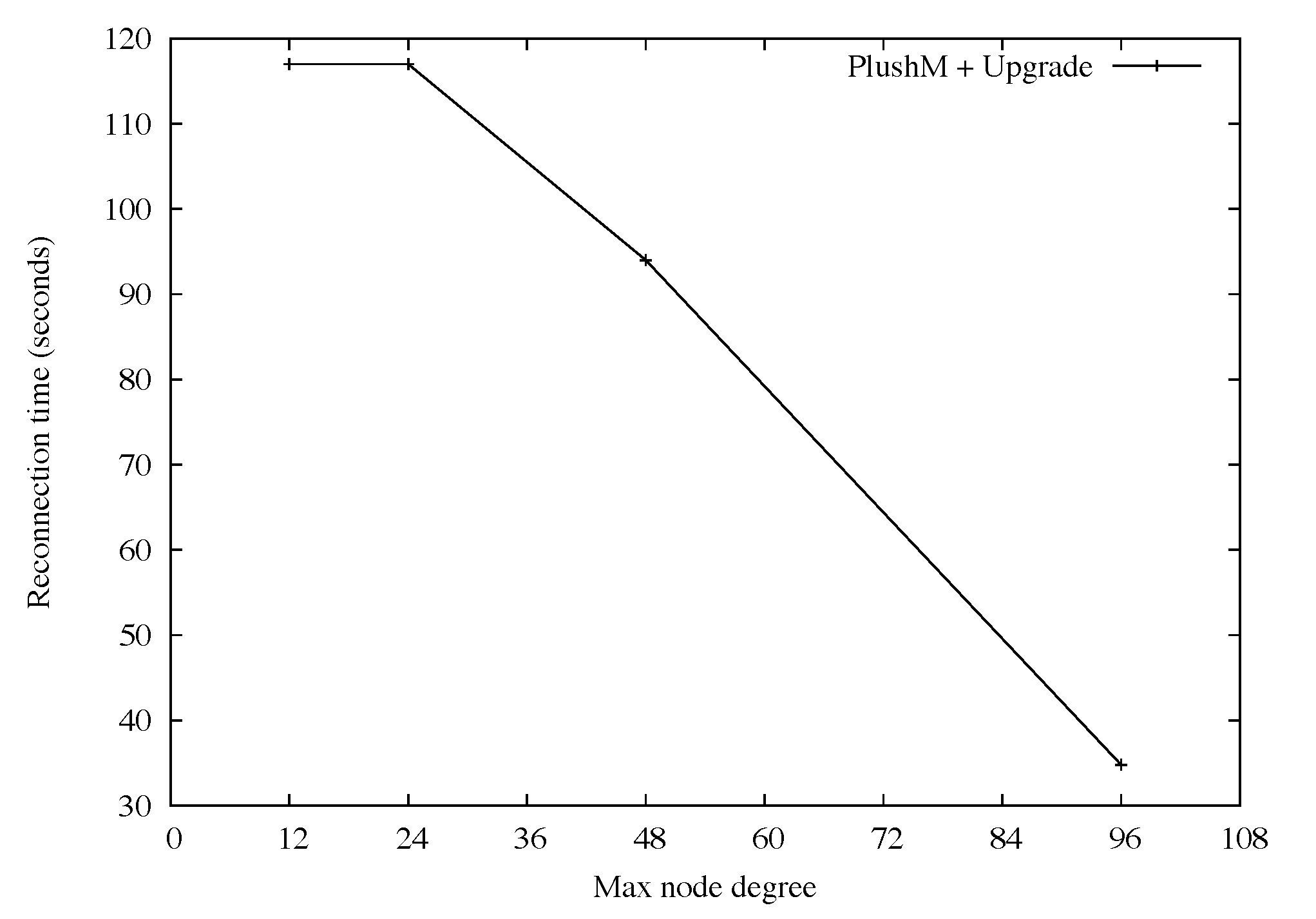
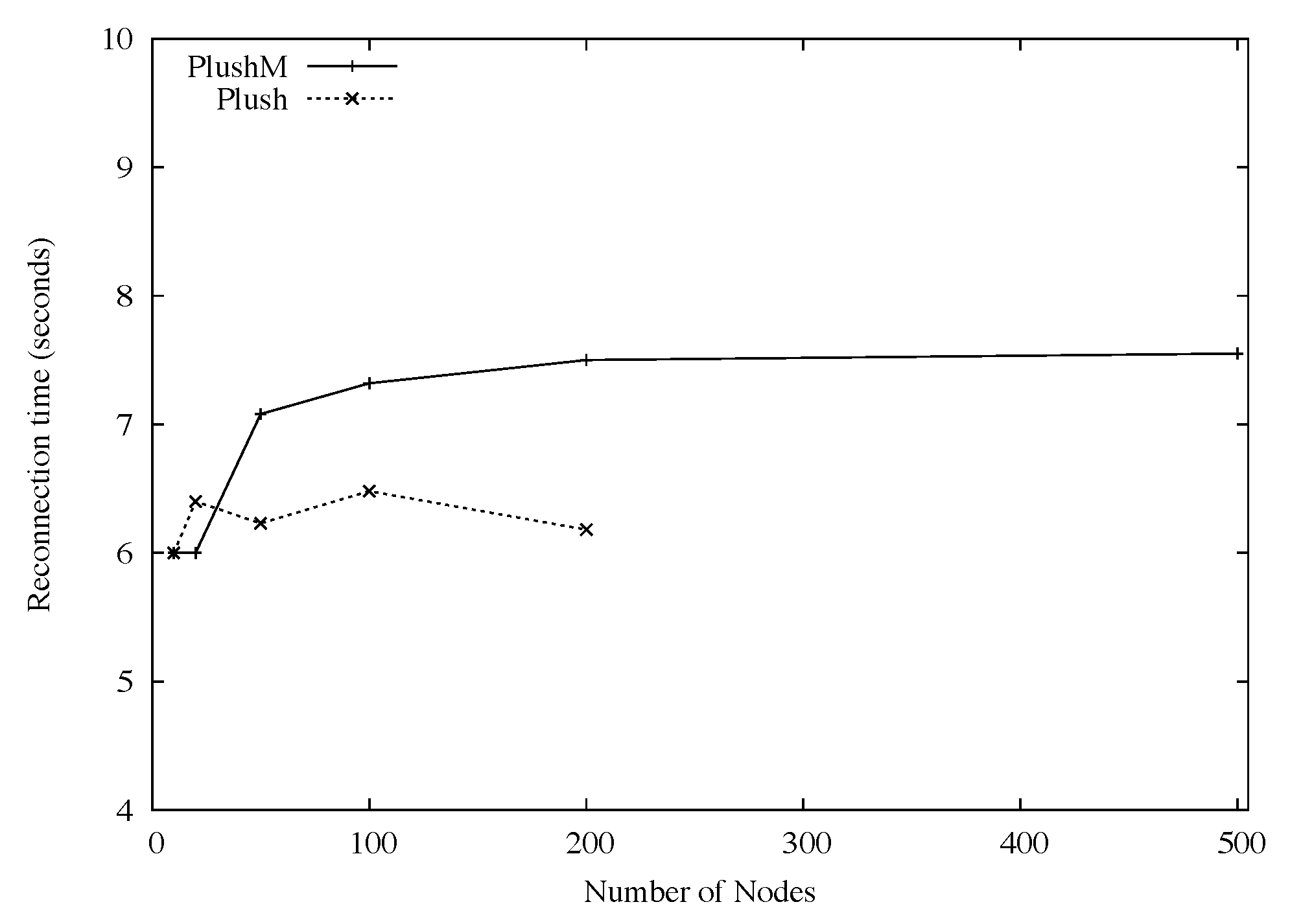
Figure 5 also shows that with automatic upgrade enabled, as the number of participants increased, so did the average reconnection time. This was expected, since many PlanetLab nodes were running with high CPU loads and had slow connectivity to the software version server. With automatic upgrade disabled, the results are much more promising. The average reconnection latency using Plush-M and Plush was very close. For Plush-M, the average reconnection time for overlays with more than 12 participants took approximately 12 seconds. When less than 12 nodes were involved, RandTree created a tree with one level and all nodes directly linking to the root. In this case the average time was about 8 seconds. Plush running over its default star topology performed consistently as the number of nodes increased, with an average reconnect time of about 7 seconds. The difference between Plush-M and Plush on larger overlays is likely caused by the overhead of tree reconfiguration. However, this overhead was relatively small (less than 7 seconds for all experiments), and did not seem to increase significantly as the number of participants grew.
 |
In the context of remote job execution, Plush-M has similar goals as cfengine [7] and gexec [9]. However, since Plush-M can be used to actively monitor and manage a distributed application, and also supports automatic failure recovery and reconfiguration, the functionality provided by cfengine and gexec is only a subset of the functionality provided by Plush-M. Like Plush, cfengine defaults to using a star topology for communication, with additional configuration support for constructing custom topologies. This constructed topology typically reflects the administrative needs of the network, and depending on what topology is used, can impact scalability. gexec relies on building an n-ary tree of TCP sockets, and propagates control information up and down the tree. The topology allows gexec to scale to over 1000 nodes, and seems similar to the approach used in Plush-M.
SmartFrog [11] and the PlanetLab Application Manager (appmanager) [13] are designed to manage distributed applications. SmartFrog is a framework for building and deploying distributed applications. SmartFrog daemons running on each participating node work together to manage distributed applications. Unlike Plush-M, there is no central point of control in SmartFrog; work-flows are fully distributed and decentralized. However, communication in SmartFrog is based on Java RMI, which can become a bottleneck for large numbers of participants and long-lived connections. appmanager is designed solely for managing long-running PlanetLab services. It does not support persistent connections among participants. Since it utilizes a simple client-server model, it most closely resembles the Plush star topology, and has similar scalability limitations. The scalability also largely depends on the capacity of the server and the number of simultaneous requests.
Condor [6] is a workload management system for compute-bound jobs. Condor takes advantage of under-utilized cycles on machines within an organization for hosting distributed executions. The communication topology of Condor uses a central manager which is directly connected to the machines in the resource pool, constructing a star topology like Plush. The scale of this design is limited by the constraints of the operating system, such as file descriptor limits, similar to the star topology in the original design of Plush.
In addition, we plan to evaluate the scalability and fault tolerance of Plush-M on much larger topologies. Thus far we have been limited by the unavailability of physical cluster machines and PlanetLab resources to host our experiments. We plan to gain access to larger testbeds and perform more extensive testing. While we are confident that our design will scale to much larger topologies, we need to verify correct operation in a realistic large-scale computing environment. This will also allow us to identify additional performance bottlenecks that only appear when large numbers of participants are present.
One last problem that we hope to address relates to how failed nodes are handled in Plush-M and Mace. Currently, when a node fails repeatedly, Plush-M detects that the node may be problematic and marks it as failed. This prevents the control node from attempting to use the node for future computations. However, Plush-M lacks the facility to indicate the failure to Mace. Hence, Mace continually attempts to reestablish the connection with the failed node during every recovery cycle. By introducing an extension to Mace that allows Plush-M to mark certain nodes as failed, we can significantly decrease the traffic associated with overlay maintenance, thus improving performance.
Based on our experimentation thus far, we believe that RandTree is a robust tree-based overlay network that allows Plush-M to scale far beyond the limits of the original Plush design. We believe that the performance bottlenecks experienced are largely due to limitations in our testing infrastructure. Further testing will allow us to confirm these speculations. In addition, RandTree provides Plush-M with advanced failure recovery options, including automatic failure detection and tree reconfiguration. As a result, Plush-M provides a scalable and fault tolerant solution for distributed application management in large-scale computing environments.
This document was generated using the LaTeX2HTML translator Version 2002-2-1 (1.71)
Copyright © 1993, 1994, 1995, 1996,
Nikos Drakos,
Computer Based Learning Unit, University of Leeds.
Copyright © 1997, 1998, 1999,
Ross Moore,
Mathematics Department, Macquarie University, Sydney.
The command line arguments were:
latex2html -split 0 -show_section_numbers -local_icons -no_navigation albrecht_html
The translation was initiated by jeannie on 2008-06-03