
Zoe Sebepou1, Kostas Magoutis, Manolis Marazakis,
and Angelos Bilas1
Institute of Computer Science (ICS)
Foundation for Research and Technology - Hellas (FORTH)
P.O.Box 1385, Heraklion, GR-71110, Greece
{sebepou,magoutis,maraz,bilas}@ics.forth.gr
When designing a large-scale computing installation for a scientific or industrial application, IT architects face a challenge deciding on the most appropriate parallel file system. The right choice typically depends on the specific characteristics of the application as well as the design assumptions built into the parallel file system. In this study, we address this challenge by taking a closer look at two prominent parallel file systems and comparing them experimentally on a range of benchmark-driven scenarios modeling specific real-world applications.
Our choice of parallel file systems to evaluate in this study, namely PVFS2 [12] and Lustre [5], is driven primarily by the increasing interest on these systems by the large-scale data processing community. Both systems share the fundamental design concepts of separation of data and metadata paths and the creation of I/O parallelism through direct client access to the storage servers [8]; however, they also differ in several other facets of their architecture, on issues such as consistency semantics, support for client caching, and metadata management. The experimental evaluation presented in this paper aims to highlight the areas where the systems perform comparably as well as the areas where their performance differs, using several industry-standard benchmarks.
A common problem with many benchmark-driven experimental evaluation studies is the difficulty of understanding the impact of a multitude of tunable parameters on the measured performance. A related problem is the difficulty of extrapolating the measured results to a wider range of applications. In this paper, we take a first step towards solving this problem by establishing a common framework based on a general model of applications performing parallel I/O. In this model, described in detail in Section 2, we capture typical application file-access patterns, attributes, and other characteristics that impact file performance. To understand the interaction of the application model with the fundamental design concepts behind PVFS2 and Lustre, in Section 3 we discuss their key similarities and differences, focusing on issues such as separation of control-data paths, parallelism, consistency, and access semantics. In Section 4 we describe the benchmarks used in our study and in Section 5, the results of our experimental evaluation.
Our results show that:
Finally, in Section 6 we discuss related work, and in Section 7 we summarize our conclusions.
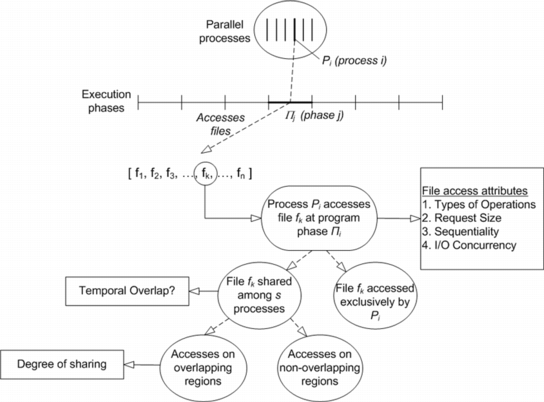
Parallel applications typically access one or more files throughout their execution for the purposes of reading and writing their initial input, final output, or temporary data; taking snapshots of their state; saving statistics, etc. The I/O characteristics of a parallel application play a key role in the resulting performance, through their interaction with the underlying file system architecture, and can be characterized by a number of attributes, depicted in Figure 1.
It is important to note that the type of file access may vary for different
phases of a parallel program. In general, a parallel program consists of a
number of phases ![]() through
through ![]() ,
each phase executed by a number
of processes P1 through Pm. During a phase
,
each phase executed by a number
of processes P1 through Pm. During a phase ![]() ,
a specific
process Pi may be accessing a number of files f1 through fn,
with each file fk accessed either exclusively by Pi or concurrently
with other processes. In this model, each triplet
,
a specific
process Pi may be accessing a number of files f1 through fn,
with each file fk accessed either exclusively by Pi or concurrently
with other processes. In this model, each triplet
![]() is associated with a file access pattern characterized through the following
attributes: (a) the type of the operations performed on fk (e.g. read,
write); (b) the average requested size in bytes; (c) the degree of
sequentiality (e.g., sequential, strided, mixed, random); (c) the amount of
I/O concurrency (e.g., number of outstanding I/Os per process). For files that
are open for access by multiple processes, we distinguish between files in
which the processes do not overlap, and files for which the processes do
overlap. In the latter case, we specify the degree of sharing (i.e., number
of bytes). Besides spatial overlap, we capture the degree of temporal overlap
(i.e., simultaneous access to a file) by multiple processes.
is associated with a file access pattern characterized through the following
attributes: (a) the type of the operations performed on fk (e.g. read,
write); (b) the average requested size in bytes; (c) the degree of
sequentiality (e.g., sequential, strided, mixed, random); (c) the amount of
I/O concurrency (e.g., number of outstanding I/Os per process). For files that
are open for access by multiple processes, we distinguish between files in
which the processes do not overlap, and files for which the processes do
overlap. In the latter case, we specify the degree of sharing (i.e., number
of bytes). Besides spatial overlap, we capture the degree of temporal overlap
(i.e., simultaneous access to a file) by multiple processes.
Our intention in creating an I/O model of parallel applications is two-fold: First, we want to identify the different types of behavior underlying real-world applications, so that we can understand and quantify the demands they pose in the underlying parallel file system. Second, we want to capitalize on the predictive power of such a model by combining its instantiation for specific applications with experimental results obtained from standard or novel parallel file system benchmarks. Such benchmarks alone cannot address the question of ``how does my application perform on parallel file system X?''. A model-driven approach to application-specific performance prediction is similar in spirit to previous work on application-specific benchmarking [19] , which has also been applied to file systems [22].
Predicting application performance over parallel file systems, however, is a particularly challenging task, complicated by the multitude of system components involved (metadata and storage servers over storage controllers (RAID) over potentially thousands of disk devices) and the tiered architecture of most parallel file systems. File and storage allocation policies can vary significantly across parallel file systems and even across installations of the same parallel file system. As a result, reasoning about performance of an application requires taking into account specific characteristics of the underlying parallel file system. For example, whereas a specific phase of a parallel application appears to be accessing data in a (logically) regular manner, such as sequential or strided-sequential, the specific file allocation policy may in effect turn this to a near-random pattern towards the actual storage servers. Combining the aforementioned application model with such characteristics of parallel file systems in order to achieve accurate prediction of application performance is part of our ongoing and future work.
|
The parallel file systems used in this study, PVFS2 and Lustre, are targeted for large-scale parallel computers as well as commodity Linux clusters. A side-by-side comparison of the architectural concepts behind these systems, summarized in Table 1 , reveals a number of similarities as well as a number of differences. In terms of similarities, both systems decouple metadata from data accesses, offering clients direct data paths to a shared object-based [8] storage pool addressable through a common namespace. One or more metadata servers are responsible for informing clients of the location of data in the storage servers but are not involved in the actual I/O operation. Both systems stripe data across the available storage servers, offering parallel I/O paths. Utilizing such parallel data paths, clients can achieve scalable I/O performance.
Key differences between the two systems are in their consistency semantics and in their caching and locking policies. Starting from file access semantics, PVFS2 offers the UNIX I/O and MPI-IO interfaces to applications. However, the UNIX I/O interface implementation in PVFS2 does not support POSIX atomicity semantics. Instead, it guarantees sequential consistency only when concurrent clients access non-overlapping regions of a file (otherwise referred to as ``non-conflicting writes'' semantics). On the other hand, Lustre's implementation of the UNIX I/O interface guarantees consistency in the presence of concurrent conflicting requests.
Support for POSIX consistency semantics in parallel file systems requires cache consistency across file system clients, typically implemented through the use of a locking mechanism. Lustre utilizes a scalable intent-based locking protocol whose functionality and management are distributed across file servers. With intent-based locking, a client that requests a lock on a directory in order to create a file in that directory, tags the lock request with information on the intended operation (i.e., to create a file). If the lock request is granted, the metadata server uses the intention specified in the lock request to modify the directory, creating the requested file and returning a lock on the new file instead of the directory. In Lustre, each file server is responsible for the locking of the data stripes that it holds, avoiding a single lock manager bottleneck and increasing availability under failures. Lustre guarantees cache consistency by forcing the clients that have cached data to flush their caches before releasing any previously acquired locks.
Unlike Lustre, PVFS2 does not offer client-side caching or any file locking mechanisms. Lack of client caching fits well workloads with litttle or no data re-use. However, the application is responsible for I/O policies typically implemented in a file cache, such as prefetching. A benefit of not providing a client cache is the avoidance of the double-buffering effect when data is stored in both application and file system (client) buffers, increasing memory pressure [13]. Both file systems by default implement client write operations asynchronously (i.e., without the need to synchronize with the underlying disk).
Lustre optimizes individual metadata operations by maintaining a cache of pre-allocated objects, thus de-coupling allocation and assignment of metadata objects. Lustre further optimizes metadata operations by implementing a metadata-specific write-back (WB) cache. Through the use of that cache, a lock on a metadata object granted to a client allows the client to cache any modifications to that metadata object in its WB cache. PVFS's support for metadata optimizations includes a server-side attribute cache (disabled by default) and a client-side name cache (also disabled by default).
PVFS2 and Lustre differ in the way they distribute metadata management tasks for performance and availability. PVFS2 distributes metadata management responsibilities across any number of metadata servers in a partitioned, ``share-nothing'' manner that does not offer any availability guarantees. Lustre on the other hand, can utilize two metadata servers in a primary-backup clustering scheme, thus achieving high availability, without however improving performance.
PVFS2 is implemented in both user-level and kernel versions whereas Lustre is implemented in the kernel. With regard to their metadata server architecture, PVFS2 uses the Berkeley DB database for mapping file handles to object references whereas Lustre uses a modified Linux ext3 in its metadata servers. Finally, PVFS2 includes support for increased parallelism in non-contiguous access patterns through an implementation of the list I/O interface [4].
IOzone: In this highly configurable benchmark [1] a single process opens a file in order to perform a sequence of I/O operations
with a certain profile (operation mix, access pattern, block size, etc.).
IOzone is implemented as a single thread. However, multiple concurrent instances
of IOzone can be explicitly started on a single client node.
Parallel I/O (PIO): This benchmark [21] produces a number of common
spatial access patterns, such as strided, nested strided, random
strided, sequential, tiled, and unstructured mesh. In this
benchmark each process issues a number of I/O requests of a given size to either
a single shared file or multiple exclusively-owned files.
The total amount of data transferred (termed buffer size) is equal to
the size of a single I/O request multiplied by the total number of I/O requests
issued by each process.
Cluster PostMark: PostMark [10] is a synthetic benchmark aimed
at measuring the system performance over a workload composed of many
short-lived, relatively small files. Such a workload is typical of mail and
netnews servers used by Internet Service Providers. PostMark workloads are
characterized by a mix of metadata intensive operations. The benchmark begins
by creating a pool of files with random sizes within a specified range. The
number of files, as well as upper and lower bounds for file sizes, are
configurable. After creating the files, a sequence of transactions is
performed. These transactions are chosen randomly from a file creation or
deletion operations, paired with a file read or write. A file creation
operation creates and writes random text to a file. File deletion removes a
random file from the active set. File read reads a random file in its entirety
and file write appends a random amount of data to a randomly chosen file. In
our evaluation we used a parallel version of this benchmark called Cluster
PostMark, which was developed in our lab [7]. In this
version, each PostMark process performs transactions within their own
independent file set and synchronizes with all other processes over a global
barrier at the beginning and end of the benchmark.
MPI Tile I/O (Tile IO): This benchmark [16] models scientific
and visualization applications, which typically access file data structured in
a two-dimensional set of tiles. In this benchmark, a number of processes
concurrently access a shared file in which data has been laid out in a tiled
pattern. A tile assigned to a specific process may or may not be overlapping
with a tile assigned to a different process; we experiment with both cases and
refer to the corresponding configurations as Tile I/O 1 and
Tile I/O 2, respectively. The access pattern is strided-sequential with
a block size that depends on tile dimensions.
User-Perceived Response Time: Measuring the performance of interactive tasks is important as it attests to the quality of the day-to-day experience of human users. To estimate the response time of a typical interactive task as perceived by users of a parallel file system we evaluate the performance of the Unix ls -lR command on the Linux kernel tree (about 25,000 files).
|
Our experimental setup consists of a 24-node cluster of Opteron x86 servers with 1GB of DRAM running Linux 2.6.12 and connected through a 1Gbps Ethernet switch. In this cluster we deployed Lustre v1.6.0.1 and PVFS2 v2.6.3. Half of the nodes are configured as file servers-one of them doubling as metadata server in both setups- and the rest as clients. Each node of each file system is provisioned with a dedicated logical volume comprising four 40GB partitions of SATA disks in a RAID-0 configuration. The total capacity of each parallel file system in the 12-server setup is about 1.7TB. Each file server node uses an underlying Linux file system of type ext3. In all MPI experiments we use the MPICH2 implementation [2].
To ensure that the benchmark workloads exceed cache capacity at clients and servers, thus producing significant disk I/O activity, we used a (shared) file of about 12GB (or about 1GB per client) in most cases. Files are laid out using the same file-system stripping policy, which is round-robin across all file servers using a 64KB stripe. While this is the default for PVFS2, we had to explicitly reduce Lustre's default stripe size of 1MB. However, we found that this change had minimal impact in our experimental results.
Client writes are performed
asynchronously (i.e., without flushing to disk) on both file systems in all
benchmarks. Lustre's client cache uses a write-back policy, whereas PVFS2
does not perform client caching for data at all. Details
on all benchmarks can be found in Section 4.
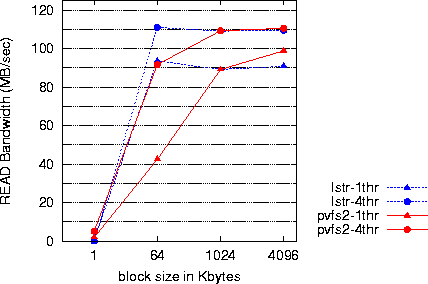
IOzone: In this benchmark we measure streaming performance reading and writing a large file stripped over all 12 file servers from a single client. The client process performs I/O with configurable block size (1KB, 64KB, 1MB, 4MB), waiting on completion of each I/O operation. We perform experiments using a single client thread (lstr-1thr, pvfs2-1thr) and four client threads (lstr-4thr, pvfs2-4thr).
Our results for the case of reads (Figure 2) indicate
that both PVFS2 and Lustre can achieve the maximum achievable
single-client bandwidth of
about 110MB/s for large block sizes (upwards of 1MB) when using
four client threads (lstr-4thr, pvfs2-4thr).
For a 64KB block size and a single client thread, lstr-1thr
reaches 90MB/s whereas pvfs2-1thr achieves only about 45MB/s.
We believe that the difference is due to the lack
of prefetching policies in the PVFS2 file client.
As a result, performance under PVFS2 is constrained by
the lack of I/O parallelism in the application. By increasing the
number of simultaneously executing IOzone threads (pvfs2-4thr) we
increase I/O parallelism at the client side, thus
eliminating the performance difference between the two file systems.
As can be seen from Figure 2, Lustre also stands
to benefit from
increasing application parallelism from one to four threads.
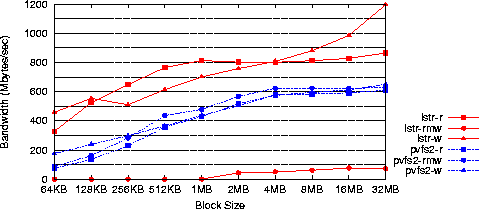
PIO: In this benchmark we measure sequential access by multiple file clients varying the block size from 64KB to 32MB, with each client process accessing a total of 1GB of data. For each block size we measure three configurations: (a) reads from a single shared file; (b) writes to separate, exclusively-owned files; (c) reads followed by writes (50%-50%) to a single shared file.
From the aggregate bandwidth results shown in Figure 3 we observe that PVFS2 performance scales consistently across the 64KB-4MB block size range across all configurations, leveling for larger block sizes (4MB-32MB). In contrast, Lustre performance varies across configurations. In the cases of reading from a shared file (lstr-r) or writing to separate exclusively-owned files (lstr-w), Lustre outperforms PVFS2 by at least 25-30% for all block sizes. For block sizes larger than 4MB, Lustre scalability improves to a nearly-linear rate when writing to separate exclusively-owned files. We attribute this difference to Lustre's use of a write-back client cache.
In the case of reads followed by writes to a single shared file (lstr-rmw), Lustre performance is hit by the overhead of maintaining strict consistency semantics across all 12 clients, reducing aggregate bandwidth to only a few MB/s for 64KB-1MB blocks, which increases to about 100MB/s for block sizes up to 32MB. This overhead is reduced in setups with fewer clients (and thus lower cache consistency maintenance cost) as we experimentally confirmed in a single-client single-server system.
To investigate the causes of the leveling in performance
for PVFS2 (all configurations) and Lustre (reads; lstr-r)
starting at 4MB blocks, we measured PIO performance with a
single client and 12 servers, which we expected to be consistent
with the IOzone benchmark for a single thread. We confirmed
that expectation measuring about 90MB/s for both systems, which we
believe is the asymptotic performance
achievable by a single client when accessing a striped file
over all 12 servers. Moving to 12 clients in the PIO
benchmark, aggregate bandwidth for PVFS2 falls short of
that achieved by Lustre by about 25%. We believe the reason
lies in inefficiencies within PVFS2's metadata server involved
in all I/O operations.
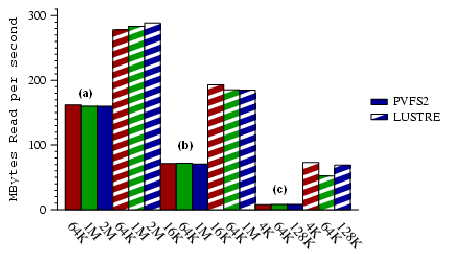
PostMark: We experimented with three configurations of Cluster PostMark with the following characteristics: (a) few large files: (b) a moderate number of medium-size files; (c) many small files. The parameters in these configurations are summarized in Table 3.
Looking at aggregate read throughput (depicted in Figure 4) for different block sizes, we observe that Lustre outperforms PVFS2 across all configurations and block sizes. In configuration (a), the benefit for Lustre is expected to be due to client caching, particularly in the absence of file sharing (i.e., no contention for the cache), as well as its optimized metadata server architecture. As the benchmark becomes less I/O-intensive with decreasing file sizes, metadata management rises as the dominant source of overhead. In this case (configuration (c)), Lustre outperforms PVFS2 due to its more efficient metadata operations based on its support for intent-based locking [5] and pre-allocation of metadata objects. Our results are similar for the aggregate write-throughput (not shown).
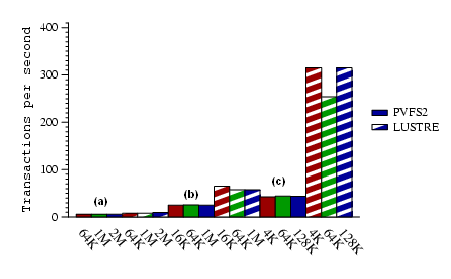
Looking at aggregate transactions per second
(depicted in Figure 5) for different block sizes, we
observe that in the metadata-intensive case (configuration (c); large number
of small files), Lustre outperforms PVFS2 by a factor of about 5 due to its
more efficient metadata management operations. PVFS2 performance could
in principle be improved by
enabling additional (active) metadata server, a feature not
supported by Lustre. In our experience however, we were not able to
observe a measureable
performance difference when using more than one metadata servers.
Tile-IO:
In this MPI benchmark, a large file is logically partitioned into a
two-dimensional grid of tiles. In this experiment we configure the
benchmark for 12 tiles (6![]() 2), each tile comprising
1254
2), each tile comprising
1254![]() 1254 elements of
512 bytes each. In this logical structure, which is overlaid on a
shared 9.5GB file,
each file client is assigned and accesses a specific tile. We
measure the cases of (a) non-overlapping file access (i.e., clients do not access any
common data); (b) overlapping file access in one dimension of the 6
1254 elements of
512 bytes each. In this logical structure, which is overlaid on a
shared 9.5GB file,
each file client is assigned and accesses a specific tile. We
measure the cases of (a) non-overlapping file access (i.e., clients do not access any
common data); (b) overlapping file access in one dimension of the 6![]() 2 grid.
The block size with which MPI is performing file I/O is determined by tile dimensions
and element size, in this case about 620KB.
2 grid.
The block size with which MPI is performing file I/O is determined by tile dimensions
and element size, in this case about 620KB.
This benchmark is expected to stress the file systems in more than one ways. First, access by each client to a dedicated tile (case (a)) requires effective strided-sequential I/O to non-contiguous regions in the file, resulting in a near-random access pattern (Section 2). Second, overlap in file accesses between clients in case (b) is expected to stress Lustre's cache consistency mechanisms. In contrast, PVFS2 is not expected to be impacted from sharing since it lacks support for file caching. In addition, PVFS2 avoids the double buffering effect between application buffers and file client cache, which is expected to impact Lustre.
Figure 6 reports aggregate read and write
throughput respectively, in the cases of overlap and no overlap
in tiles. Lustre outperforms PVFS2 by about 10% in aggregate
read throughput (Figure 6 (a)) in both cases,
aided by its more efficient metadata server implementation.
Both systems benefit from overlap in tiles as they can take
advantage of server-side file caching. In contrast,
PVFS2 outperforms Lustre by a factor of two on aggregate write
bandwidth (Figure 6 (b)) as Lustre is
experiencing the overhead of maintaining cache consistency.
Unfortunately, this overhead is not justified by the benchmark
semantics which do not require strict consistency. Both systems
benefit from write-back caching at file servers.
User-perceived Response Time: Interactive tasks common in day-to-day operations performed by human users are key to the adoption of parallel file systems by practitioners. To get a feeling for the performance of a typical such task, we measure the response time of a Unix ls -lR operation on all files in the Linux version 2.6.12 kernel tree (about 25,000 files). Our results are summarized in Table 4 in the cases of a local file system (ext3), Lustre, and PVFS2. We observe that PVFS2 is about 40% slower than Lustre. Both parallel file systems, however, exhibit a significant slowdown (about an order of magnitude) compared to a local file system.
|
An earlier experimental evaluation [3] at Lawrence Berkeley National Labs compared AFS, GFS, GPFS and PVFS to NFS [17] using PostMark, IOzone, and other benchmarks. A follow-on study [15] evaluated a number of shared-storage file systems on issues such as parallel I/O performance, metadata operations, and scalability using the MPTIO and METEBENCH parallel tests. Two related experimental evaluations [14,6] of PVFS, Lustre and GPFS focused on I/O performance, scalability, redundancy, ease of installation and administration characteristics using the IOR parallel benchmark from Lawrence Livermore National Lab. Another study [6] focused on issues of installation, configuration, and management of these systems on two heterogeneous compute clusters using single-client and multiple-client bandwidth tests. This study concluded that all measured file systems outperformed an NFS installation and that PVFS2, Lustre and GPFS performed comparably across all their benchmark tests. Finally, Kunkel [11] focused on parallel file system performance bottlenecks using PVFS2 as a test case. This study introduced the idea of replacing PVFS2's methods accessing the underlying I/O subsystem with stubs diverting I/O from physical storage in order to avoid the performance impact of several sources of inefficiency in the I/O subsystem. Results provided for a wide range of contiguous requests as well as for metadata operations.
Our work relates to the aforementioned experimental evaluation studies in the focus on specific parallel file systems, including PFVS and Luster, but differs in that it provides a more comprehensive comparison spanning a wide range of benchmarks.
This document was generated using the LaTeX2HTML translator Version 98.1p1 release (March 2nd, 1998)
Copyright © 1993, 1994, 1995, 1996, 1997, Nikos Drakos, Computer Based Learning Unit, University of Leeds.
The command line arguments were:
latex2html -split 0 -show_section_numbers -local_icons -no_navigation -tmp /tmp -dir sebepou-lasco08-html paper.tex.
The translation was initiated by Manolis Marazakis on 2008-06-06
![\begin{figure*}
\centering
\subfigure[Read]{\epsfig{file=camfigures/figure6,widt...
...,width=8cm,bbllx=30bp,bblly=160bp,bburx=300bp,bbury=380bp,clip=} }
\end{figure*}](img11.gif)